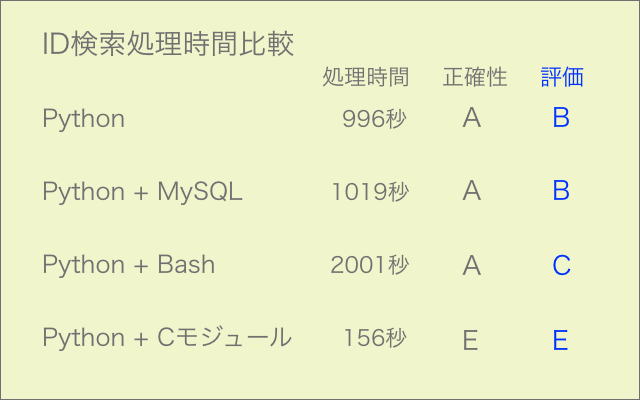
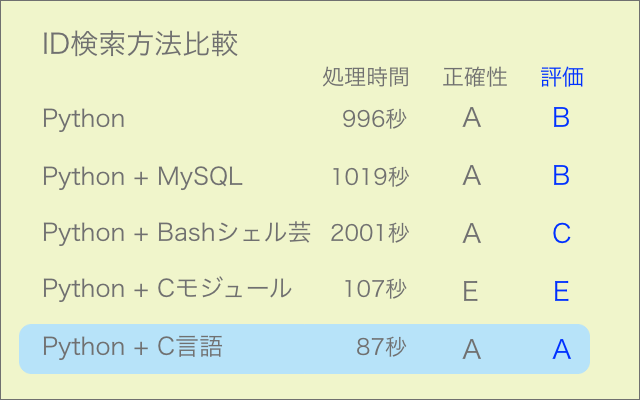
競走馬名からIDを検索する部分をC言語で作成し、Python用にモジュール化して走らせてみました。約25000件の処理になります。
速度は6倍になりましたが、検索漏れのエラーが多発して今のところ使えない状態です(エラー率6%)。
丸1日掛けて過去最高レベルで苦労したにも関わらず、残念な結果となりました。
シェルスクリプトのワンライナーでも試してみましたが、処理は正確なものの時間は2倍掛かりました。やはり大量処理には向かないようです。
馬名を都度Cモジュールに渡して検索する方式から一括渡しのバッチ式に変更してさらに検証を進める予定です。
それでも改善しなければ、観念して全編C言語で作成することになるかもしれません。なるべく回避したいところです。
21/7/12追記 バッチ式で検証したところC言語ではOK、モジュール化するとNGでした。モジュール化の方法に問題があるようです。
#include <stdio.h>
#include <stdlib.h>
int main(void) {
FILE *fp; // horse_listファイル
int horseID[9]; // 1 horseID
char horse_name[50]; // 2 馬名
char horse_name0[50]; // 3 馬名0 (外),(地)等を付加した馬名
char status[10]; // 4 稼働状態
char gender[10]; // 5 性別
char hair[10]; // 6 毛色
char birthday[50]; // 7 生年月日
char trainer[50]; // 8 調教師
char owner[50]; // 9 馬主
char breeder[50]; // 10 生産者
char area[50]; // 11 産地
char price[50]; // 12 セリ取引価格
char prize_money[50]; // 13 獲得賞金
char result[50]; // 14 通算成績
char winning_race[100]; // 15 主な勝鞍
char horse_name_in[50]; // 検索馬名
FILE *fp2; // 入出力用一時ファイル
char buf[600]; // fgets用
char buf2[100]; // 検索馬名用
int ret;
int i=0;
int strcmp(const char *s1, const char *s2);
char fname[100];
char fname2[] = "horseID.txt";
fp2 = fopen(fname2, "r");
while(fgets(buf2,100, fp2) != NULL ) {
sscanf(buf2,"%[^,],%s",fname,horse_name_in);
printf("%s,%s\n",fname,horse_name_in);
fclose(fp2);
}
fp = fopen(fname, "r");
if(fp == NULL) {
printf("%s file not open!\n", fname);
return -1;
}
while( fgets( buf,600, fp ) != NULL ) {
ret = sscanf(buf, " %9s, %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %s",horseID,horse_name,horse_name0,status,gender,hair,birthday,trainer,owner,breeder,area,price,prize_money,result,winning_race ) ;
if (i != 0){
if (strcmp(horse_name,horse_name_in)==0){
fp2 = fopen(fname2, "w");
fprintf(fp2, "%9s\n", horseID);
fclose(fp2);
}
}
i ++ ;
}
fclose(fp);
}