非公開で開発中のBBS閲覧アプリiOS版をClaude Codeで整備しました。スレッド内容のフォントサイズが一定しないなどの問題を修正してくれました。
UI関連を3箇所ほど都度実機ビルドで確認しながら20分程度で完了。ボタンなどウィジェットを削除したらリンクしている関数も探して消してくれます。コストはたったの$0.49でした。楽勝すぎて引いています。
非公開で開発中のBBS閲覧アプリiOS版をClaude Codeで整備しました。スレッド内容のフォントサイズが一定しないなどの問題を修正してくれました。
UI関連を3箇所ほど都度実機ビルドで確認しながら20分程度で完了。ボタンなどウィジェットを削除したらリンクしている関数も探して消してくれます。コストはたったの$0.49でした。楽勝すぎて引いています。
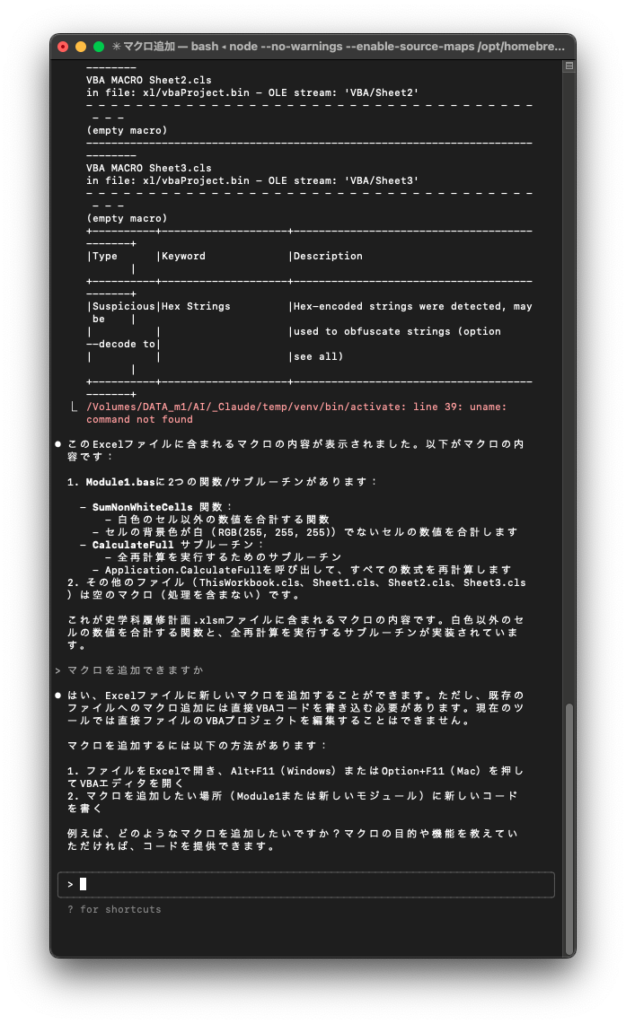
Claude Codeにマクロ入りxlmsファイルを解析させました。
Pythonのライブラリを使って解析してくれました。venvへのPython導入含め所要時間は5分程度、コストは$0.19でした。
直接編集はできませんが、VBAマクロコード自体は考えてくれるようです。
企業や組織にて個人単位で作られては廃棄されるVBAマクロを引き継ぐためのメンテに使えそうです。
[Mac M2 Pro 12CPU RAM 16GB, Sonoma 14.7.1, clang++ 16.0.0]
Claude Codeにバグの原因を調べさせて修正してもらいました。
プロジェクトファイルが大型化してメンテナンスを放置しがちだったのですが、Claude Codeがサクッと直してくれました。修正まで3分程度、コストはたったの$0.32(約48円)でした。
これはChatGPTリリース以来の衝撃です。現役プログラマはこういったサービスを使いこなさないと置いていかれますね。
Claude Codeで一から十まで作ろうとするから高コストになるだけで、最初の取っ掛かりと仕上げやメンテに限定すればそんなに費用はかさまないでしょう。骨組みを作らせたら、ChatGPTで中身を肉付けすればいいと思います。
昨今のAIブームではプログラマが職を失うというよりも、プログラマ間のスキル格差が広がっていく気がします。
Claude CodeでApple Watch用時計アプリを製作しました。
あらかじめデフォルトのXcodeプロジェクトを作成して置いておくと後はさくっと作ってくれました。コマンドプロンプトからXcodeプロジェクトを作成できるよう.bash_profileを書き換えてくれますが、空っぽのプロジェクトフォルダから作ろうとするので、先に書いたように手動でプロジェクトを作ってあげる方が効率的です。
プロジェクトにコードが書かれていく様はまさに衝撃です。トータル10分も掛からず、課金消費は1ドル程度でした。
開発中のプロジェクトをカレントディレクトリに置いて指示をすると色々いじってくれそうです。既存アプリのメンテナンスに使えるかどうか今後検証していきます。
ただビジネスユーザではなく個人ユーザがClaude Codeで扱ったコードをAnthropicが学習データにしているのかどうか気になります。そこが明確にならないと商品アプリには使えないです。
なお、このサービスはノンプログラマ対象ではなく、ある程度プログラミングができる人向けですね。
今話題のReplitでAppIconsを作成するWebアプリを作成しました。Replitでデプロイせずに、Macのローカルで起動させて使っています。
JavaScriptやPythonのようなスクリプト言語を扱うプログラマがまず存亡の危機に立たされています。C++やSwiftユーザーも時間の問題でしょうか。
ただ、Replitを使いこなすにはプログラミングに関する一通りの知識がある方がよさそうです。
Monthlyサブスクの場合はクーポン適用にて初月$10(本来は$25)で使えるのでしばらく使ってみます。
[Mac M2 Pro 12CPU RAM 16GB, Sonoma 14.7.1, clang++ 16.0.0]
これまでプログラミングに関してはgpt-4oの優位は変わらなかったのですが、今日初めてPerplexityのsonarがSwiftUIで圧勝しました。
sonarは日本語が不得手で文脈も読めませんが、プログラミングに関してはレベルが違う回答をしてくれました。gpt-4oは知識は十分なものの、提案の優先順位がおかしい印象です。
SwiftUIでWatchConectivityライブラリを使ってイベントストアを操作するという同期・非同期混在でややこし目のプログラムを一発回答で解決してくれました。今回のリクエストに関してはgpt-4oの回答はひどいものでした。
メインModelがsonarになる日が近いのかもしれません。
[Mac M2 Pro 12CPU RAM 16GB, Sonoma 14.7.1, clang++ 16.0.0]
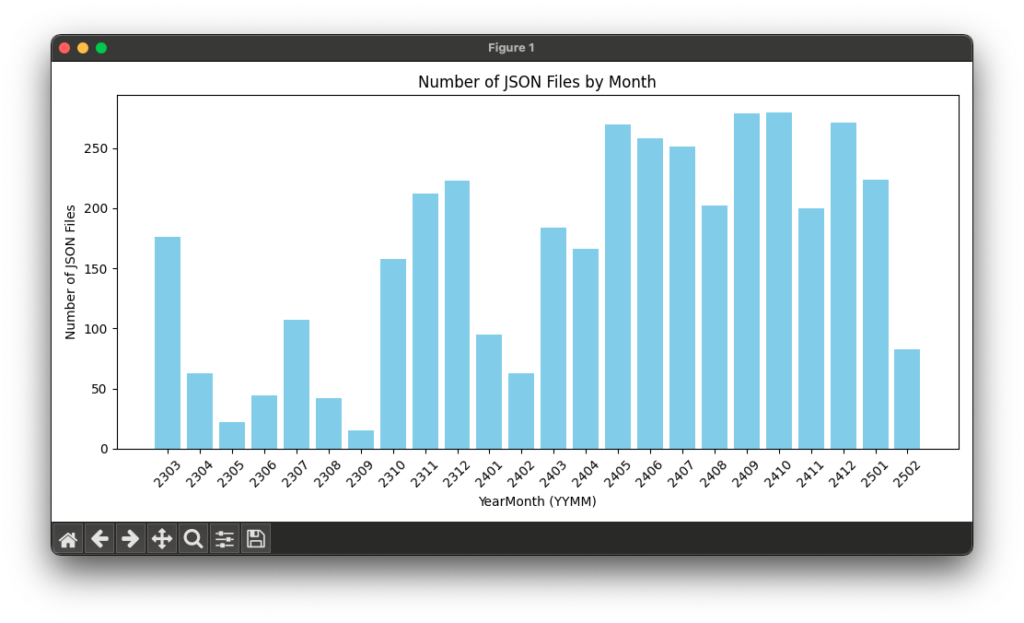
2023年3月にChatAIアプリ初版を製作して2年が経とうとしています。
APIを使用して作成されたJSONファイル数の推移をまとめてみました。
ChatGPT、Perplexity、つい最近ではDeepSeekとますます充実してきました。
gpt-4oとDeepSeekにPythonでのグラフ作成スクリプトを考えさせました。gpt-4oは一発で動きましたが、DeepSeek考案スクリプトはこちらで一回修正してあげてもダメでした。これにはガッカリです。
蒸留、量子化しなければまともに働くかどうかは不明です。
[Mac M2 Pro 12CPU RAM 16GB, Sonoma 14.7.1, clang++ 16.0.0]
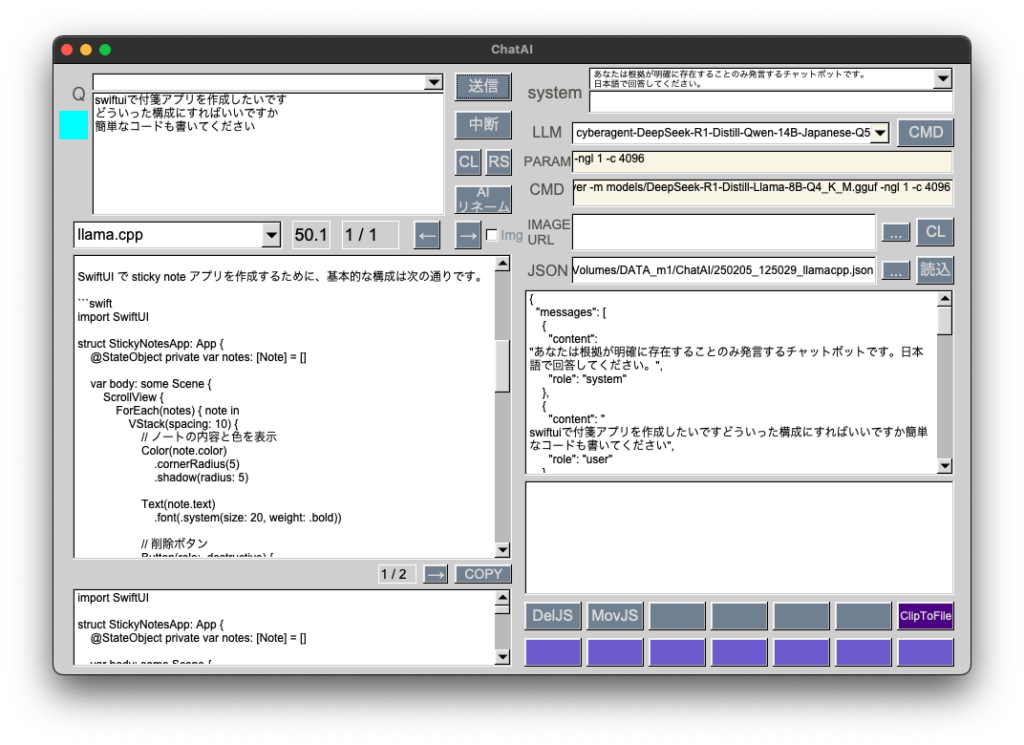
GGUF: cyberagent-DeepSeek-R1-Distill-Qwen-14B-Japanese-Q5_K_M.gguf 10.5GB
DeepSeek日本語版をサイバーエージェントが公開したので、量子化ファイルを動作検証しました。
前回記事のGGUFと同様に時間はかかりますが、コード提案能力はなかなかのものです。これまで量子化するとかなり能力が落ちるという印象でしたが、DeepSeekではそのようなことはありませんでした。蒸留が効いているのでしょうか。
プログラミング用途ではgpt-4oやPerplexityからこちらに移行します。
ローカルLLMをまともに動かすにはユニファイドメモリ 64GB以上が必要、という認識が見事に覆りました。最新GGUFはRAM 16GBで使用に耐えるレベルにて動作します。
VRAM 12GBのWindowsPCではどうなるか検証してみたいです。
[Mac M2 Pro 12CPU RAM 16GB, Sonoma 14.7.1, clang++ 16.0.0]
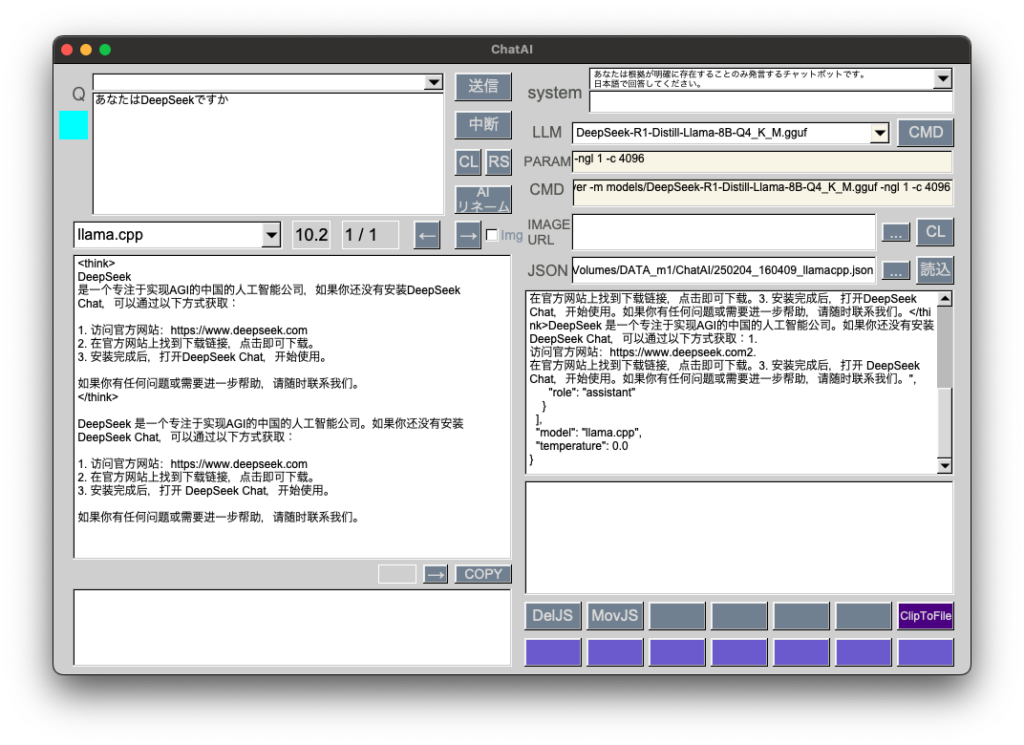
GGUF: DeepSeek-R1-Distill-Llama-8B-Q4_K_M.gguf 4.9GB
話題のDeepSeekを量子化ファイルで試してみました。
プログラミング用途ではこれまで扱ってきたGGUFと比べてかなり優秀です。gpt-4oと比べると回答内容はまずまず、レスポンス時間はかなり長いです。
DeepSeekチャットサーバ起動コマンド
cd /AI/llama.cpp && ./bin/llama-server -m models/DeepSeek-R1-Distill-Llama-8B-Q4_K_M.gguf -ngl 1 -c 4096[Mac M2 Pro 12CPU, Sonoma 14.7.1, clang++ 16.0.0]
[C++] 383は非公開
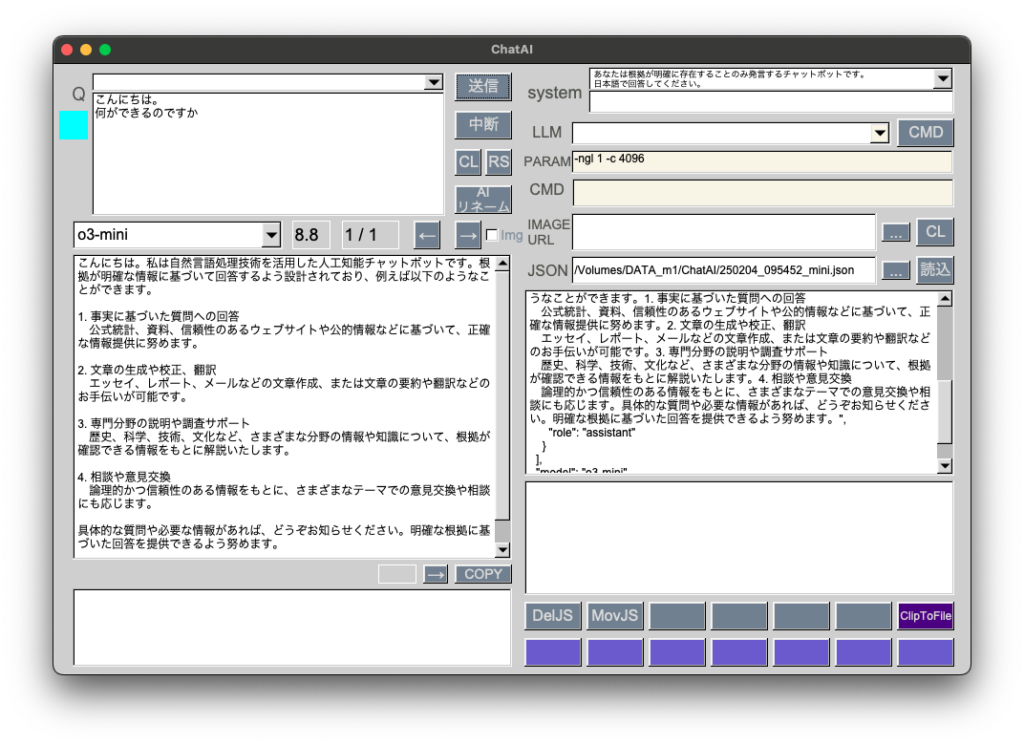
普段はgpt-4oで十分足りていますが、評判がいいようなのでo3-miniも使えるようにしました。temperatureを削除して、reasoning_effortを追加しています。
if(countQ == 0 && load == false){
cout << "question1回目\n" << question << endl;
cout << "model: \n" << model.c_str() << endl;
if (model.find("gpt") != string::npos){
// gpt-4
requestData = "{\"model\":\"" + model + "\", \"messages\":[{\"role\":\"system\",\"content\":\"" + systemStr + "\"},{\"role\":\"user\",\"content\":\"" + question + "\"}], \"temperature\":0.0}";
} else if (model.find("mini") != string::npos){
// o3-mini
requestData = "{\"model\":\"" + model + "\", \"messages\":[{\"role\":\"system\",\"content\":\"" + systemStr + "\"},{\"role\":\"user\",\"content\":\"" + question + "\"}], \"reasoning_effort\":\"medium\"}";
} else if (model.find("llama.cpp") != string::npos){
// llama.cpp
requestData = "{\"model\":\"" + model + "\", \"messages\":[{\"role\":\"system\",\"content\":\"" + systemStr + "\"},{\"role\":\"user\",\"content\":\"" + question + "\"}], \"temperature\":0.0}";
} else if (model.find("sonar") != string::npos){
// perplexity
requestData = "{\"model\":\"" + model + "\", \"messages\":[{\"role\":\"system\",\"content\":\"" + systemStr + "\"},{\"role\":\"user\",\"content\":\"" + question + "\\n日本語で回答してください。" + "\"}], \"temperature\":0.0}";
}