[Mac M2 Pro 12CPU, Sonoma 14.5]
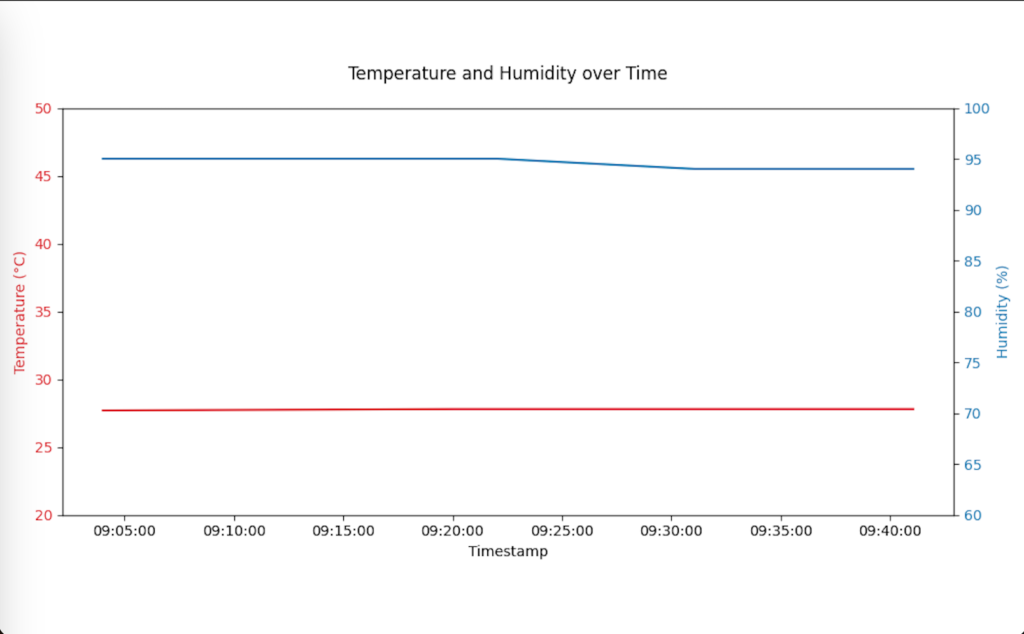
浴室暖房乾燥機で洗濯物を乾かす際の温湿度をモニタリングしました。途中何度か風呂場に素早く入って乾き具合をチェックしました。
絶対湿度33g/m3位で洗濯物が8割方乾いていたので回収し、残りは27g/m3まで下がった時点で完全に乾いていました。
製作するアプリでは絶対湿度33g/m3以下で最初の回収を促し、27g/m3以下で終了を合図するようにします。
物理的にボタンを押してくれるスマートスイッチがあれば、浴室のリモコンまで行かなくても乾燥を自動停止できます。
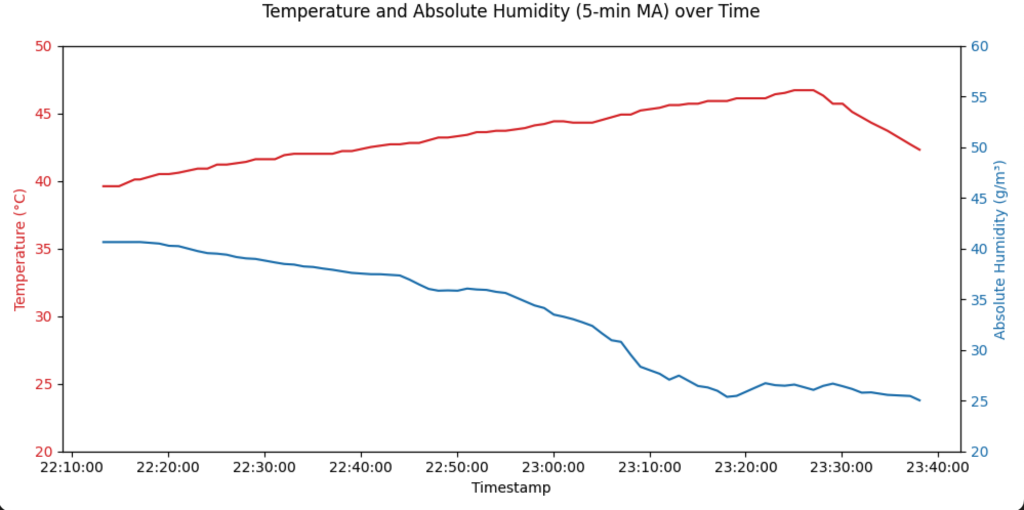 乾燥開始30分後から測定開始、23:24乾燥停止
乾燥開始30分後から測定開始、23:24乾燥停止
import os
import time
import json
import hashlib
import hmac
import base64
import uuid
import requests
import datetime
import pandas as pd
import matplotlib.pyplot as plt
from os.path import exists
import subprocess
import numpy as np
dir_name = "/SwitchBot/data"
device_id = "XXX"
token = 'XXX'
secret = 'XXX'
nonce = str(uuid.uuid4())
t = int(round(time.time() * 1000))
string_to_sign = "{}{}{}".format(token, t, nonce)
string_to_sign = bytes(string_to_sign, "utf-8")
secret = bytes(secret, "utf-8")
sign = base64.b64encode(
hmac.new(secret, msg=string_to_sign, digestmod=hashlib.sha256).digest()
)
apiHeader = {}
apiHeader["Authorization"] = token
apiHeader["Content-Type"] = "application/json"
apiHeader["charset"] = "utf8"
apiHeader["t"] = str(t)
apiHeader["sign"] = str(sign, "utf-8")
apiHeader["nonce"] = nonce
response = requests.get(
f"https://api.switch-bot.com/v1.1/devices/{device_id}/status",
headers=apiHeader,
)
devices = response.json()
timestamp = datetime.datetime.now().strftime("%Y%m%d%H%M%S")
response_file = f"{dir_name}/json/status_{device_id}_{timestamp}.json"
with open(response_file, "w") as f:
json.dump(devices, f, ensure_ascii=False, indent=4)
print("Success get device status.")
# CSVファイルを作成(データ行を追加する)
timestamp_date = datetime.datetime.now().strftime("%Y%m%d")
csv_file = f"{dir_name}/{timestamp_date}_{device_id}_data.csv"
# デバイスのステータスから必要なデータを抽出
temperature = devices['body']['temperature']
humidity = devices['body']['humidity']
battery = devices['body']['battery']
# 湿度が60%以下の場合に通知を送る(動作不可)
if humidity <= 60:
subprocess.run(['osascript', '-e', f'display notification "Humidity is {humidity}%" with title "Humidity Alert"'])
# 絶対湿度を計算
absolute_humidity = (6.112 * np.exp((17.67 * temperature) / (temperature + 243.5)) * humidity * 2.1674) / (273.15 + temperature)
# CSVファイルにデータを追加
data = {
'timestamp': [timestamp],
'temperature': [temperature],
'relative_humidity': [humidity],
'absolute_humidity': [absolute_humidity],
'battery': [battery]
}
df = pd.DataFrame(data)
if exists(csv_file):
df.to_csv(csv_file, mode='a', header=False, index=False)
else:
df.to_csv(csv_file, mode='w', header=True, index=False)
print("Success append data to CSV.")
# CSVファイルからグラフを作成する(上書き更新)
plot_file = f"{dir_name}/{timestamp_date}_{device_id}_data_plot.png"
# CSVファイルを読み込む
df = pd.read_csv(csv_file)
# タイムスタンプをdatetime型に変換
df['timestamp'] = pd.to_datetime(df['timestamp'], format='%Y%m%d%H%M%S')
# 絶対湿度の移動平均を計算(5分間の移動平均)
df.set_index('timestamp', inplace=True)
df['absolute_humidity_ma'] = df['absolute_humidity'].rolling('5T').mean()
# グラフを作成
fig, ax1 = plt.subplots(figsize=(10, 5))
ax1.set_xlabel('Timestamp')
ax1.set_ylabel('Temperature (°C)', color='tab:red')
ax1.plot(df.index, df['temperature'], label='Temperature', color='tab:red')
ax1.tick_params(axis='y', labelcolor='tab:red')
ax1.set_ylim(20, 50)
ax2 = ax1.twinx()
ax2.set_ylabel('Absolute Humidity (g/m³)', color='tab:blue')
ax2.plot(df.index, df['absolute_humidity_ma'], label='Absolute Humidity (5-min MA)', color='tab:blue')
ax2.tick_params(axis='y', labelcolor='tab:blue')
ax2.set_ylim(20, 60)
fig.tight_layout(rect=[0, 0, 1, 0.95]) # タイトルが切れないように調整
plt.title('Temperature and Absolute Humidity (5-min MA) over Time', pad=20)
plt.xticks(rotation=45)
ax1.xaxis.set_major_formatter(plt.matplotlib.dates.DateFormatter('%H:%M:%S'))
# グラフを保存
plt.savefig(plot_file)
plt.close()
print("Success create plot.")