[RTX 4070Ti, Ubuntu 22.04.1, CUDA 11.8, PyTorch 2.0.0]
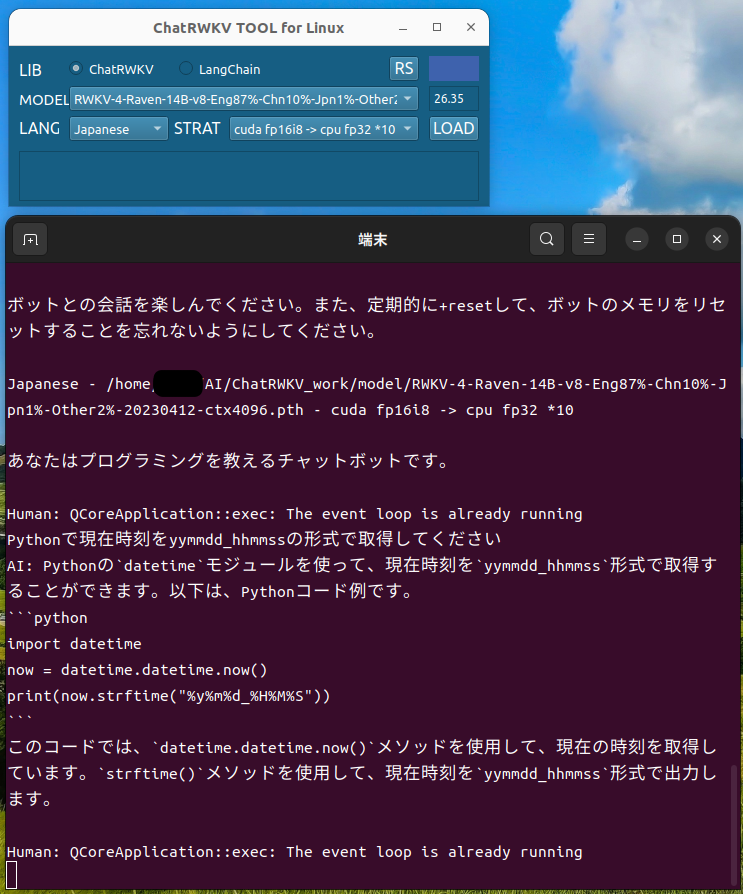
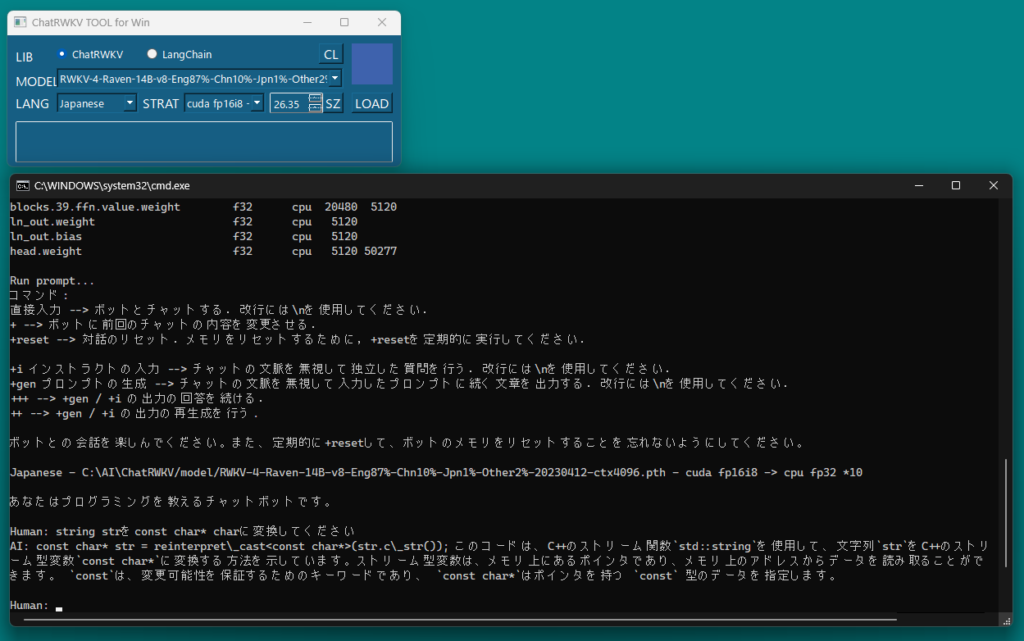
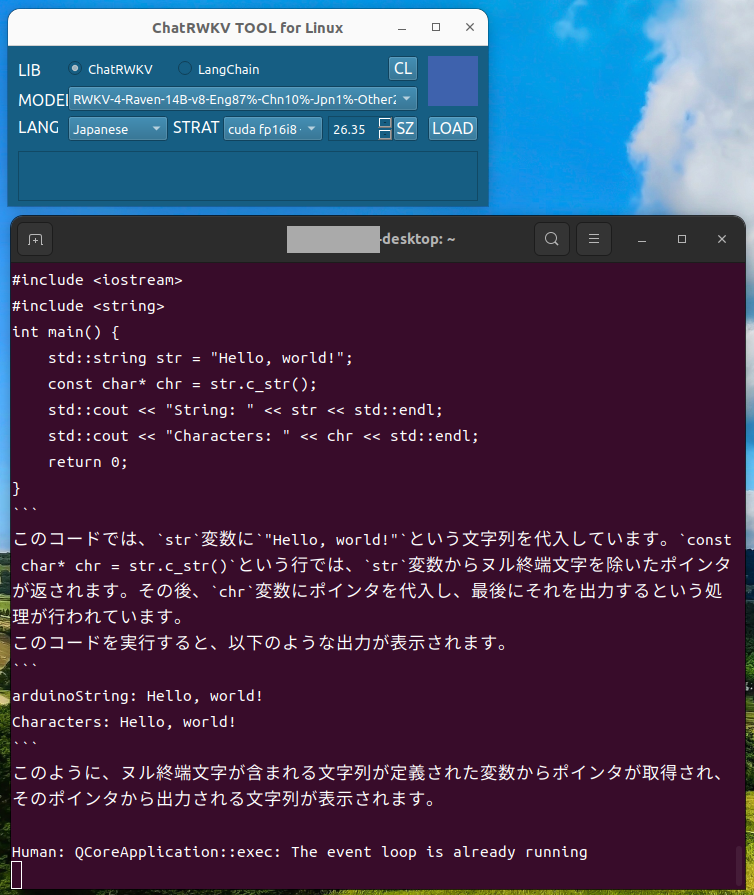
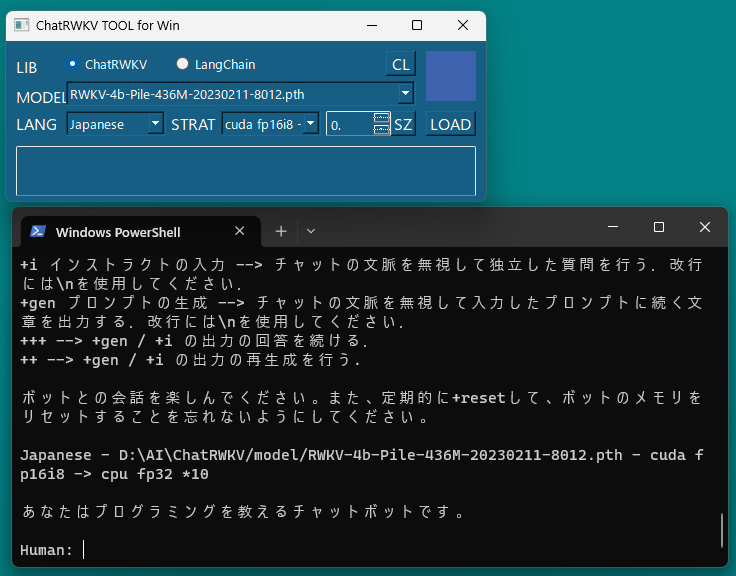
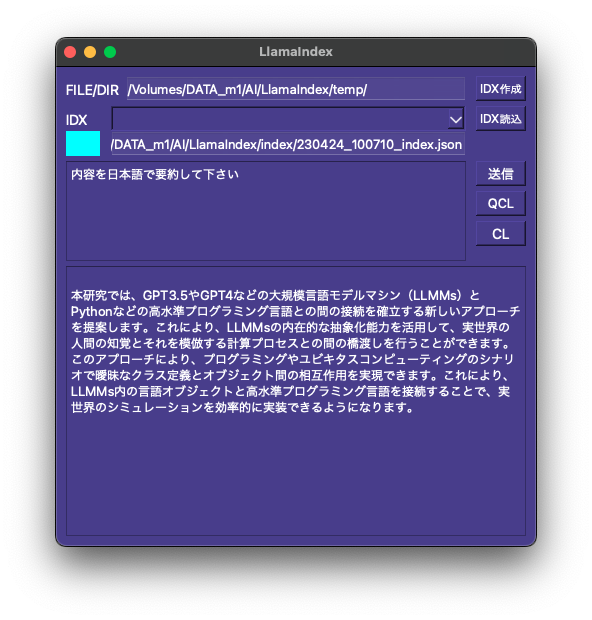
LoRAで追加学習したデータを既存の学習モデルと統合してチャットボットを動作させてみました。
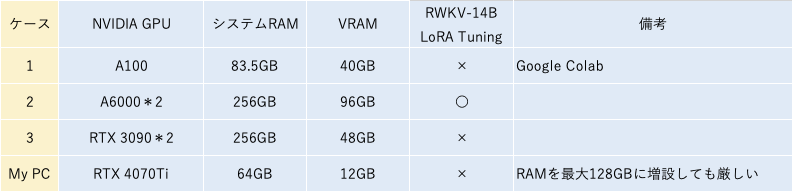
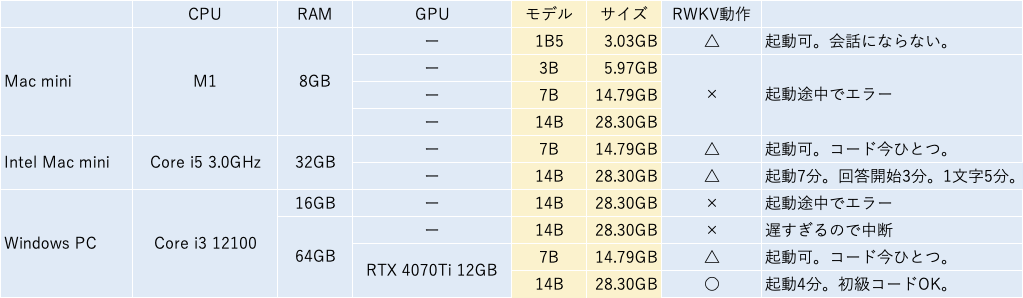
有識者や実務家によるネット情報では、A6000×2やRTX 3090×2を搭載した超ハイスペックPCを駆使していたり、一般人ができる現実的なところではGoogle ColabでA100マシンを使ったりしています。
今回はRWKVのstrategy引数を使い、RTX 4070Tiでチャットボットを動作させました。この方法でVRAM12GBを超えるサイズの学習モデルを読み込むことができます。
args = types.SimpleNamespace()
args.strategy = 'cuda fp16i8 -> cpu fp32 *10'
GPUとシステムRAMを併用してパラメータ数14BのLoRA追加学習ができないか次回以降検討します。
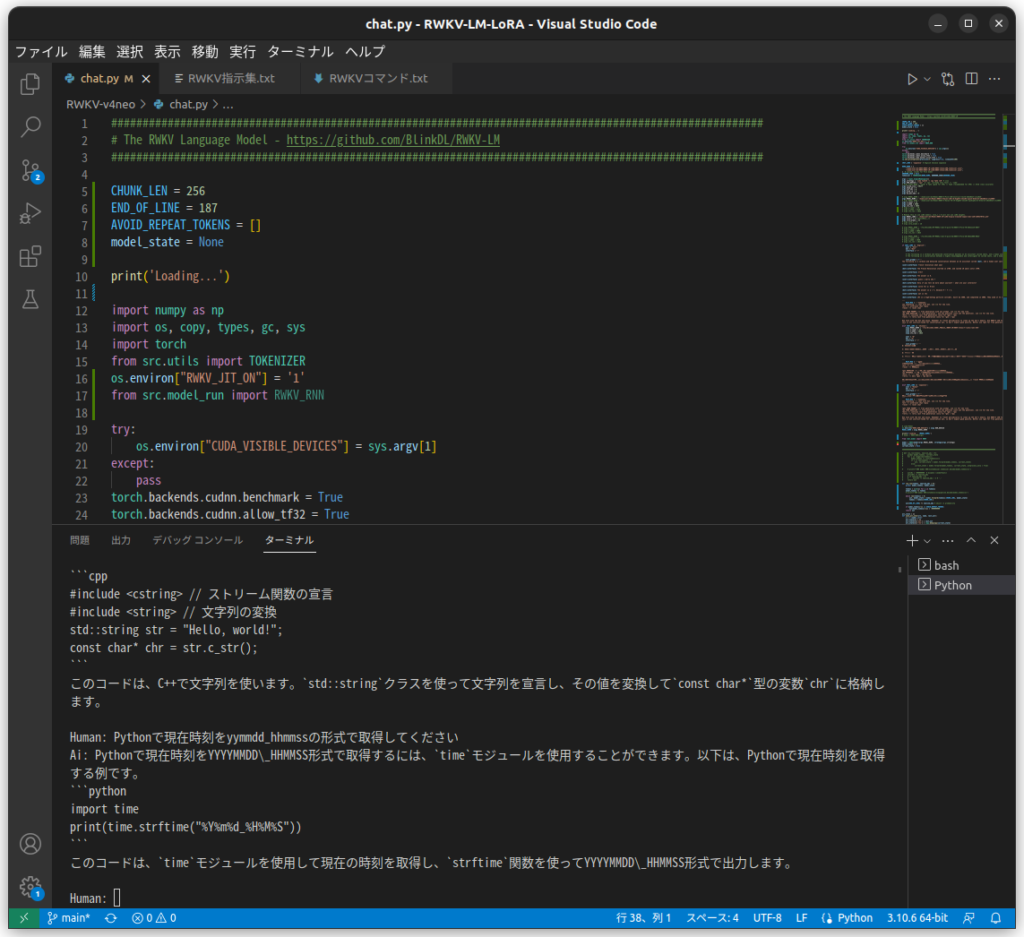
CHUNK_LEN = 256
END_OF_LINE = 187
AVOID_REPEAT_TOKENS = []
model_state = None
print('Loading...')
import numpy as np
import os, copy, types, gc, sys
import torch
from src.utils import TOKENIZER
os.environ["RWKV_JIT_ON"] = '1'
from src.model_run import RWKV_RNN
try:
os.environ["CUDA_VISIBLE_DEVICES"] = sys.argv[1]
except:
pass
torch.backends.cudnn.benchmark = True
torch.backends.cudnn.allow_tf32 = True
torch.backends.cuda.matmul.allow_tf32 = True
np.set_printoptions(precision=4, suppress=True, linewidth=200)
CHAT_LANG = 'Japanese' # English Chinese Japanese
WORD_NAME = [
"/home/xxx/AI/RWKV/RWKV-LM-LoRA/RWKV-v4neo/20B_tokenizer.json",
"/home/xxx/AI/RWKV/RWKV-LM-LoRA/RWKV-v4neo/20B_tokenizer.json",
] # [vocab, vocab] for Pile model
UNKNOWN_CHAR = None
tokenizer = TOKENIZER(WORD_NAME, UNKNOWN_CHAR=UNKNOWN_CHAR)
args = types.SimpleNamespace()
args.strategy = 'cuda fp16i8 -> cpu fp32 *10' # 追記
args.RUN_DEVICE = "cpu" # 'cpu' (already very fast) // 'cuda'
# args.FLOAT_MODE = "fp16" # fp32 (good for CPU) // fp16 (recommended for GPU) // bf16 (less accurate)
args.vocab_size = 50277
args.head_qk = 0
args.pre_ffn = 0
args.grad_cp = 0
args.my_pos_emb = 0
args.MODEL_NAME = '/home/xxx/AI/Model/RWKV-4-Raven-14B-v8-Eng87%-Chn10%-Jpn1%-Other2%-20230412-ctx4096'
args.n_layer = 24
args.n_embd = 2048
args.ctx_len = 1024
# Modify this to use LoRA models; lora_r = 0 will not use LoRA weights.
args.MODEL_LORA = '/home/xxx/AI/Model/RWKV-LM-LoRA-Alpaca-Cleaned-Japan/rwkv-120-2304270732.pth'
args.lora_r = 8 # 0はLoRA未使用
args.lora_alpha = 32
<以下略>
参考サイト
LoRA対応RWKV
LoRA追加学習データ