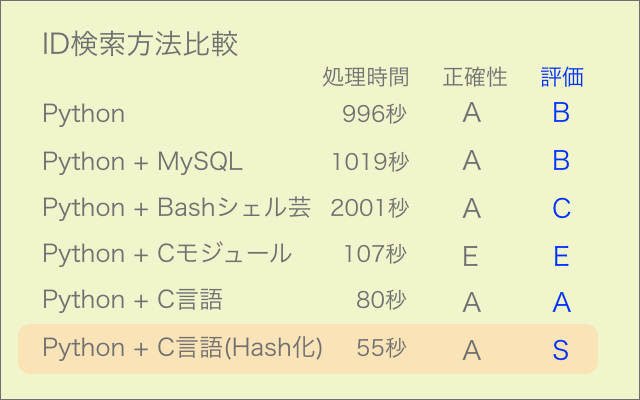
FNV-1により生成されたハッシュ値のばらつきをヒストグラムで確認しました。ハッシュ値は自製のC言語モジュールで生成しました。
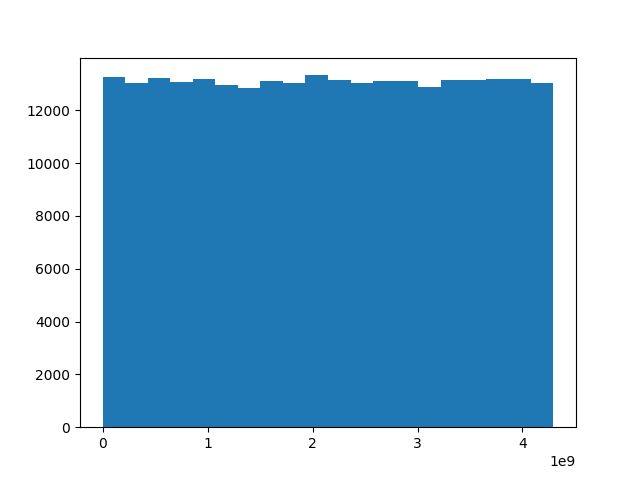
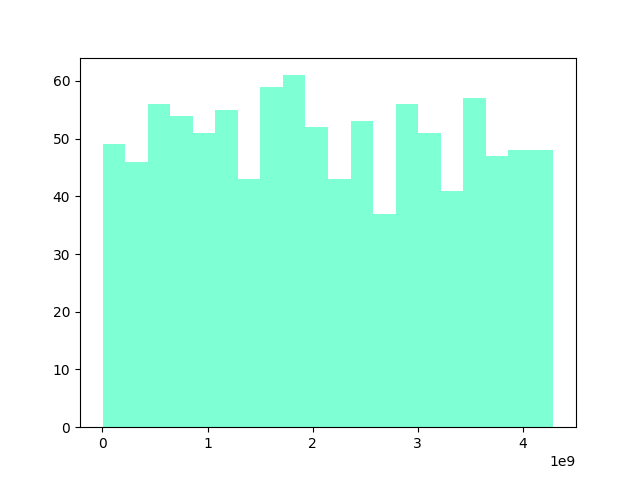
上のグラフが1986年以降に生まれた競走馬26.2万頭の馬名ハッシュ値、下のグラフが馬名にシルクが含まれる1000頭のハッシュ値をヒストグラムにしたものです。
満遍なくハッシュ値が生成されており、冠名による偏りもほとんど見られませんでした。
ハッシュ値の重複については調査中です。重複があれば他のハッシュ関数を検討します。
import matplotlib.pyplot as plt
import datetime
import pandas as pd
df = pd.read_csv("name_hash.csv",encoding='UTF-8')
df2 = df[df['馬名'].str.contains('シルク',na=False)]
list = df2['horse_hash'].tolist()
datetime_now = datetime.datetime.now()
datetime_now_str = datetime_now.strftime('%y%m%d%H%M')
plt.hist(list, bins=20,color=['#7fffd4'])
plt.savefig(f"{datetime_now_str}_hist_silk.png")