前回の続きです。
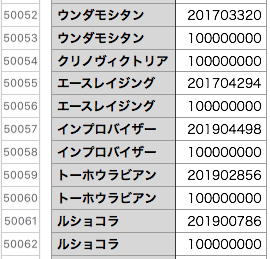
どう考えても検索ヒットした馬名のデータが2行になるのは無駄なので、1行になるよう修正しました。
この修正により処理時間が87秒から80秒に短縮されました。
<修正箇所>
while(fgets(buf,2000, fp ) != NULL ) {
sscanf(buf, " %9s, %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %s",horseID,horse_name,horse_name0,status,gender,hair,birthday,trainer,owner,info,breeder,area,price,prize_money,result,wining_race,relatives ) ;
if (i != 0){
if (strcmp(horse_name,horse_name_in)==0){
fp3 = fopen(fname3, "a");
fprintf(fp3, "%s,%9s\n", horse_name,horseID);
fclose(fp3);
b ++;
break;
}
}
i ++ ;
}
if (b == 0){
fp3 = fopen(fname3, "a");
fprintf(fp3, "%s,100000000\n", horse_name_in);
fclose(fp3);
}