もう一息のところまで出来ました。
データ型の変更でastype関数が効かないため、to_numeric関数を使いました。to_numeric関数の取り扱いはドキュメントを読まないと分かりませんでした。中級者向けでしょうか。
あとは2番目のtableのいくつかの列を右寄せにして一応完成になります。
各tableにIDを付けて2番目だけ書式設定する必要がありますが、少し工数が掛かりそうなので次回以降の記事で紹介します。
このアプリを作り上げてきて、ようやく実用に耐えるレベルに達したように思います。インターネット接続が従量制だった頃であれば、どれだけコストが浮いたことでしょう。
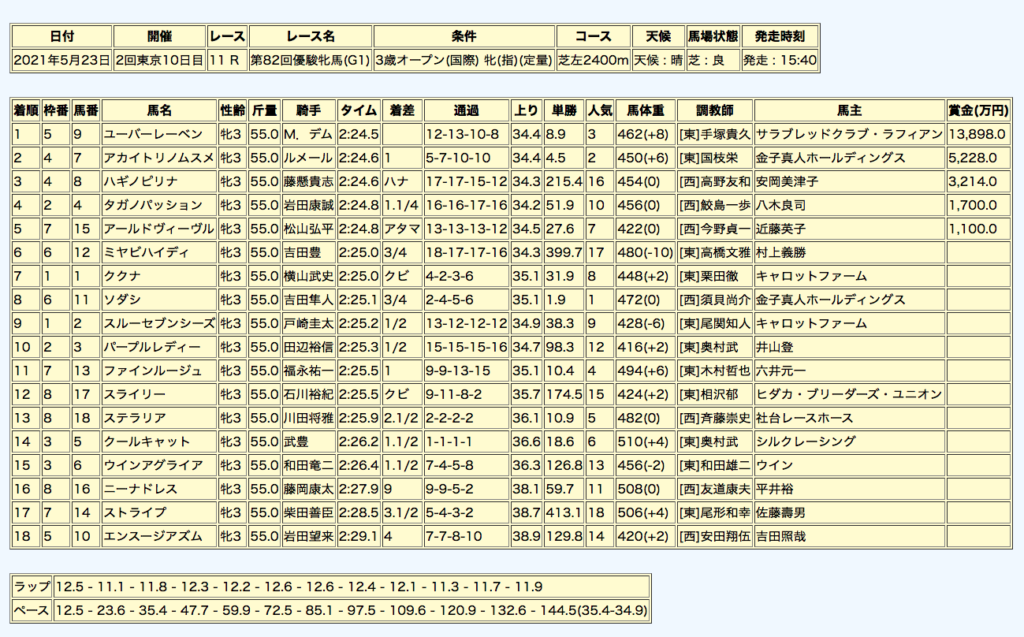
<CSVファイルの読み込み以降>
try:
df2 = pd.read_csv(racefile_path,encoding="shift_JIS")
except UnicodeDecodeError:
df2 = pd.read_csv(racefile_path,encoding="UTF-8")
# df2を複数のTableに分割
dfA = df2[['1 日付','2 開催','3 レース','4 レース名','5 条件','6 コース','7 天候','8 馬場状態','9 発走時刻']]
dfB = df2[['着順','枠番','馬番','馬名','性齢','斤量','騎手','タイム','着差','通過','上り','単勝','人気','馬体重','調教師','馬主','賞金(万円)']]
dfB2 = dfB[:-3]
dfC = dfB[-2:]
print(dfC)
dfC2 = dfC[['着順','枠番']]
print(dfC2)
# dfAのデータ行のみ抽出
row_num = len(df2)-3
print(row_num)
# データ行以外の行番号をリスト化
row_list = [row for row in range(0,row_num + 3) if not row==row_num]
print(row_list)
dfA2 = dfA.drop(dfA.index[row_list])
dfA3 = dfA2.rename(columns={'1 日付': '日付','2 開催': '開催','3 レース': 'レース','4 レース名': 'レース名','5 条件': '条件','6 コース': 'コース','7 天候': '天候','8 馬場状態': '馬場状態','9 発走時刻': '発走時刻'})
dfB3 = dfB2.fillna('')
print(dfB3.dtypes)
# 中(止)、除(外)、取(消)への対応
try:
dfB3['着順'] = pd.to_numeric(dfB3['着順'], downcast='signed')
except Exception as e:
print(e)
dfB3['枠番'] = pd.to_numeric(dfB3['枠番'], downcast='signed')
dfB3['馬番'] = pd.to_numeric(dfB3['馬番'], downcast='signed')
dfB3['人気'] = pd.to_numeric(dfB3['人気'], downcast='signed')
print(dfB3.dtypes)
html_string = '''
<html>
<head>
<meta charset="UTF-8">
<title>{raceID}</title>
<link rel="stylesheet" href="style.css">
</head>
<body>
<div class="container">
{tableA}
{tableB}
{tableC}
</div>
</body>
</html>.
'''
with open(html_file,'w') as f:
f.write(html_string.format(tableA=dfA3.to_html(index=False),tableB=dfB3.to_html(index=False),tableC=dfC2.to_html(index=False,header=False),raceID=raceID))