[M1 Mac, Big Sur 11.6.8, clang 13.0.0, FLTK 1.3.8, NO IDE]
前回の続きです。
どうしても気になったので、さらに調べてみました。
どうやらappファイルではmbstowcs関数がまともに動かないようです。マルチバイト文字を1文字としてカウントすることができません。
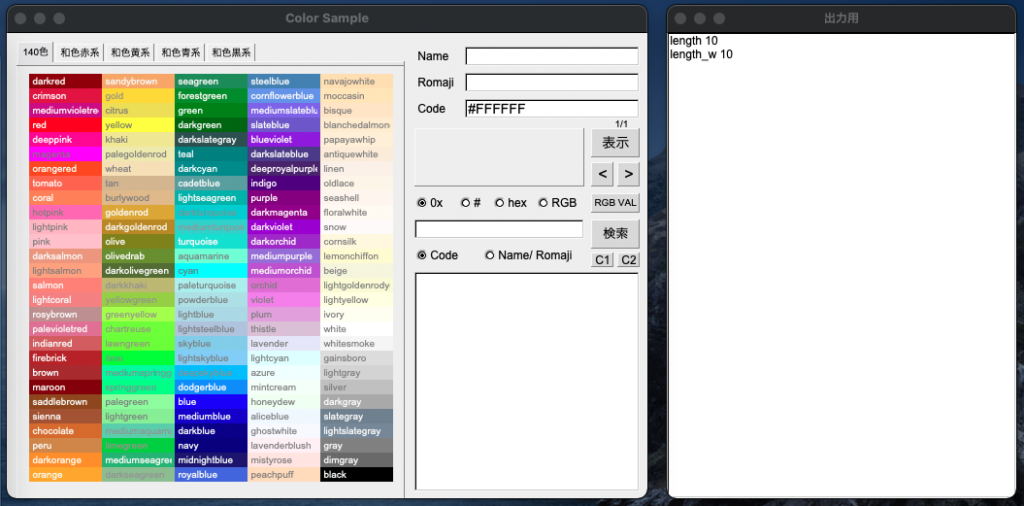
下図の右ウインドウに表示されているように、#FFFFFF(#は3バイト文字)がstring、wstringともに10文字としてカウントされています。mbstowcs関数が機能していればwstringは8文字になるはずです。同時にビルドした実行ファイルでは実際そうなっています。
これはライブラリを提供しているApple側の問題に思えます。これで一応の結論にたどり着きました。
MacOSでC++を扱っていると細かいところで非対応や不具合に遭遇します。やはりWindowsのVisual C++が至高だと思います。まあいざとなればObjective-C++へ鞍替えします。
int narrowToWide(string str) {
wchar_t *wcs = new wchar_t[str.length() + 1];
int num = mbstowcs(wcs, str.c_str(), str.length() + 1);
return num;
}
int multibyteDetect(string str){
int length = str.length();
cout << "length " << length << endl;
output_line2->insert("length ");
output_line2->insert((to_string(length)).c_str());
output_line2->insert("\n");
int length_w = narrowToWide(str);
cout << "length_w " << length_w << endl;
output_line2->insert("length_w ");
output_line2->insert((to_string(length_w)).c_str());
output_line2->insert("\n");
if (length != length_w){
return -1;
}
return 0;
}