[Python] 239の続きです。
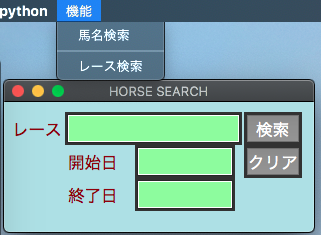
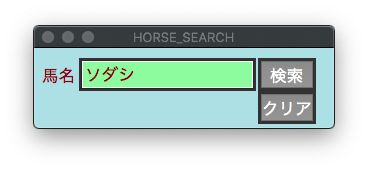
別フレームの作成や元フレームの消去などで画面を遷移させるのは容易ですが、画面内への入力内容を取得するのにかなり苦労しました。
結局Widget変数IntVarを利用して解決しました。具体的にはIntVarが0または1であれば画面A、2であれば画面Bというif文を作成しました。
if文から抜け出すために検索ボタンを2回クリックする必要がありますが、この方法であればどう画面遷移しても固まらずに対応できます。ただし画面Aと画面Bでエントリの位置が異なることが条件になります。
ネットには日本語・英語共にピッタリな情報は見あたらず、一晩考えてようやくアイデアが浮かびました。
いつものことですが、出来上がってみると実にシンプルな内容です。
# frameBを消去・frameAを作成、frameAを消去・frameBを作成する関数を設定する
# 上記関数とメニューの'馬名検索','レース検索'をそれぞれ連携させる
<中略>
# 親メニューの設定
menu_kinou = tk.Menu(menubar)
menubar.add_cascade(label='機能', menu=menu_kinou)
# 子メニューの設定
menu_kinou.add_command(label='馬名検索', command=create_A)
menu_kinou.add_separator()
menu_kinou.add_command(label='レース検索', command=create_B)
<中略>
# 初期画面・実行ボタンの作成・配置
var = tk.IntVar()
btn = tk.Button(frame, text="検索",command=lambda:var.set(1),width=2,font=my_font)
btn.grid(row=0,column=2,padx=2)
<中略>
for i in range(1000):
print(f'var for文先頭 {var.get()}')
try:
children = frame.winfo_children()
except:
children = frameB.winfo_children()
if var.get() == 0 or var.get() == 1:
print('分岐A')
# 馬名の入力を待機
btn.wait_variable(var)
# 入力した馬名を取得
try:
name = children[1].get()
except:
pass
else:
print(f'name {name}')
# 実際は<馬名検索モジュール>
else:
print(f'分岐B')
children = frameB.winfo_children()
# レース名の入力を待機
children[-2].wait_variable(var)
# 入力したレース名を取得
try:
race = children[-3].get()
except:
pass
else:
print(f'race {race}')
# 実際は<レース検索モジュール>
horse.mainloop()
--------------------------------------------------
出力
--------------------------------------------------
var for文先頭 0
分岐A
name サリオス
var for文先頭 1
分岐A
name クロノジェネシス
var for文先頭 1
分岐A
var for文先頭 2
分岐B
race 有馬記念
var for文先頭 2
分岐B
var for文先頭 1
分岐A