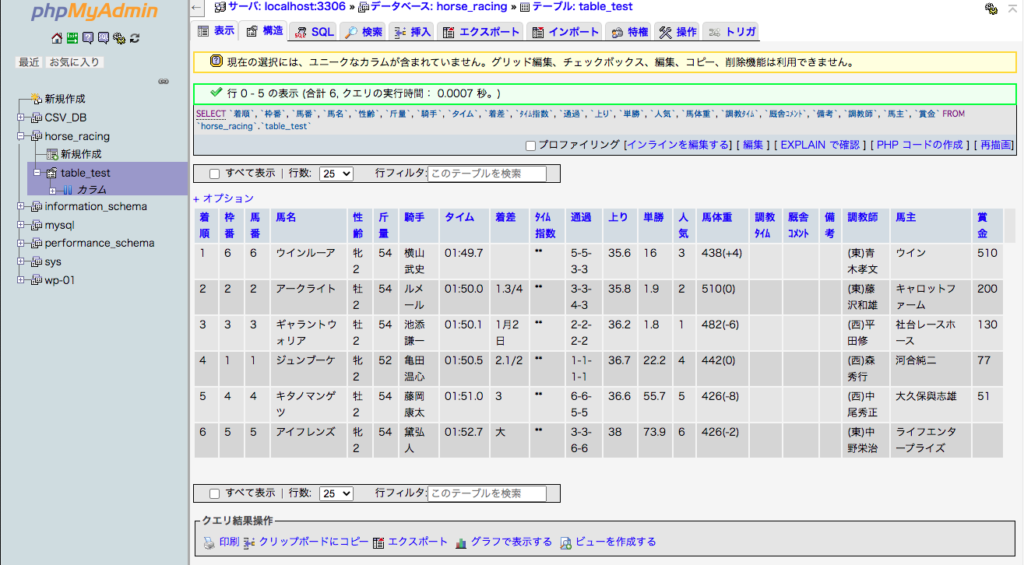
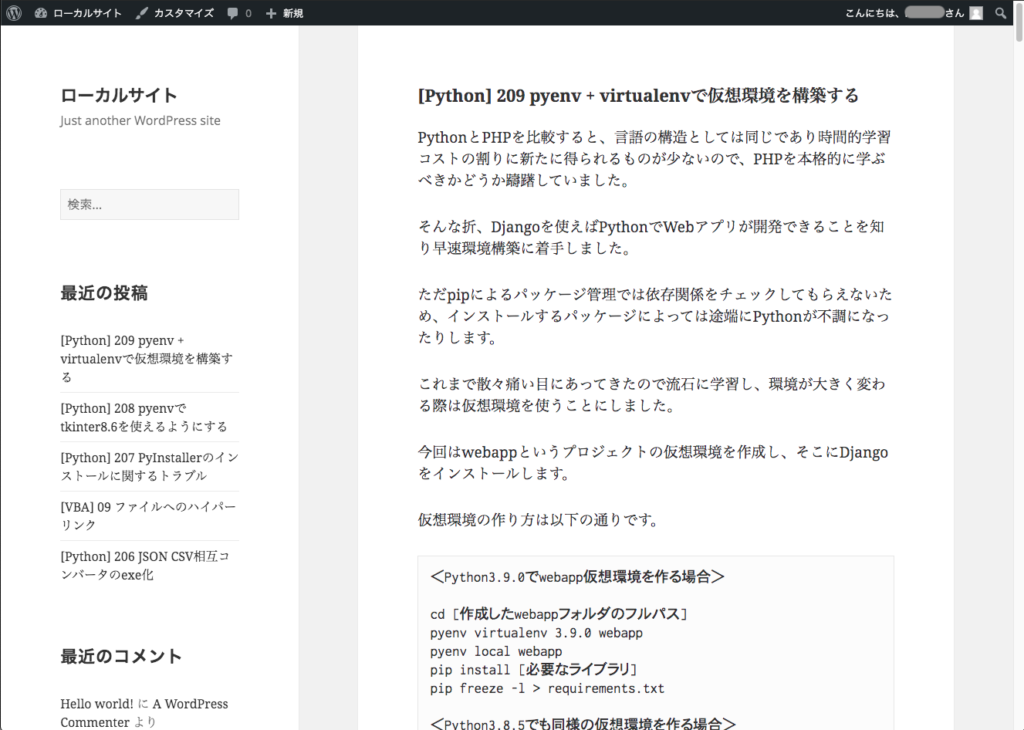
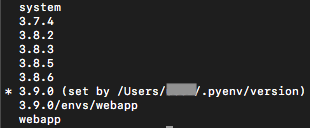
前回記事で扱ったフォルダ内のファイルをカウントしてみました。
os.path.isfile関数でファイルかどうかを一応判定します。
import glob,os
# 1986年から2020年のレースファイルをカウントする
count_all = 0
year_count = []
for year in range(1986,2021):
count = 0
for f in glob.glob(f'/horse_racing/race/{year}/*/*/*.csv', recursive=True):
if os.path.isfile(f):
count +=1
count_all += 1
year_count.append({year:count})
print(count_all)
print(year_count)
--------------------------------------------------
出力
--------------------------------------------------
119460
[{1986: 3274}, {1987: 3283}, {1988: 3307}, {1989: 3335}, {1990: 3353}, {1991: 3389}, {1992: 3399}, {1993: 3425}, {1994: 3429}, {1995: 3417}, {1996: 3407}, {1997: 3433}, {1998: 3443}, {1999: 3415}, {2000: 3451}, {2001: 3448}, {2002: 3452}, {2003: 3449}, {2004: 3452}, {2005: 3438}, {2006: 3453}, {2007: 3453}, {2008: 3436}, {2009: 3453}, {2010: 3454}, {2011: 3444}, {2012: 3454}, {2013: 3454}, {2014: 3431}, {2015: 3454}, {2016: 3454}, {2017: 3455}, {2018: 3158}, {2019: 3452}, {2020: 3456}]