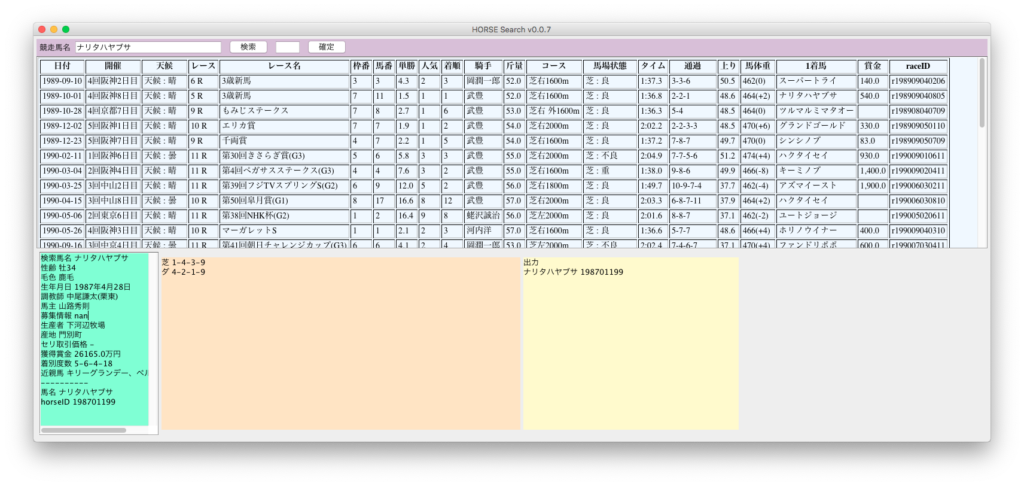
芝とダートの着別度数を算出し、プロフィール隣のJTextAreaに表示しました。あと馬場状態や距離の着別度数は必須でしょう。
芝とダートで活躍した実力馬といえばホクトベガですが地方競馬のデータがこちらにないので、中央の芝とダートにデータがあるナリタハヤブサを検索例にしました。ここまで書いたところでアグネスデジタルを思い出しました。
import glob,csv
import pandas as pd
paths = glob.glob('/*.csv')
print(paths)
paths2 = sorted(paths)
print(paths2)
csvfile = paths2[-1]
print(csvfile)
df = pd.read_csv(csvfile,encoding='UTF-8')
print(df)
prize = df['賞金'].sum(skipna=True).round(1)
print(f"獲得賞金 {prize}")
race_count = len(df)
print("レース数 " + str(len(df)))
list_着順 = df['着順'].tolist()
着順1 = len([i for i in list_着順 if i == 1])
着順2 = len([i for i in list_着順 if i == 2])
着順3 = len([i for i in list_着順 if i == 3])
着順外 = len([i for i in list_着順 if i > 3])
着別度数 = f"{着順1}-{着順2}-{着順3}-{着順外}"
print("着別度数 " + 着別度数)
list_馬場 = df['馬場状態'].tolist()
list_turf_order = list()
list_dirt_order = list()
for course,order in zip(list_馬場,list_着順):
if "芝" in course:
list_turf_order.append(order)
else:
list_dirt_order.append(order)
着順1_t = len([i for i in list_turf_order if i == 1])
着順2_t = len([i for i in list_turf_order if i == 2])
着順3_t = len([i for i in list_turf_order if i == 3])
着順外_t = len([i for i in list_turf_order if i > 3])
着別度数_t = f"{着順1_t}-{着順2_t}-{着順3_t}-{着順外_t}"
print("芝着別度数 " + 着別度数_t)
着順1_d = len([i for i in list_dirt_order if i == 1])
着順2_d = len([i for i in list_dirt_order if i == 2])
着順3_d = len([i for i in list_dirt_order if i == 3])
着順外_d = len([i for i in list_dirt_order if i > 3])
着別度数_d = f"{着順1_d}-{着順2_d}-{着順3_d}-{着順外_d}"
print("ダ着別度数 " + 着別度数_d)
list_output = [{"獲得賞金":prize,"着別度数":着別度数,"芝":着別度数_t,"ダ":着別度数_d}]
# 出力ファイル名作成
filename = csvfile.split(".")[0] + "_agg.csv"
field_name = ['獲得賞金','着別度数','芝','ダ']
with open(filename,'w',encoding='utf-8') as f:
writer = csv.DictWriter(f, fieldnames = field_name)
writer.writeheader()
writer.writerows(list_output)