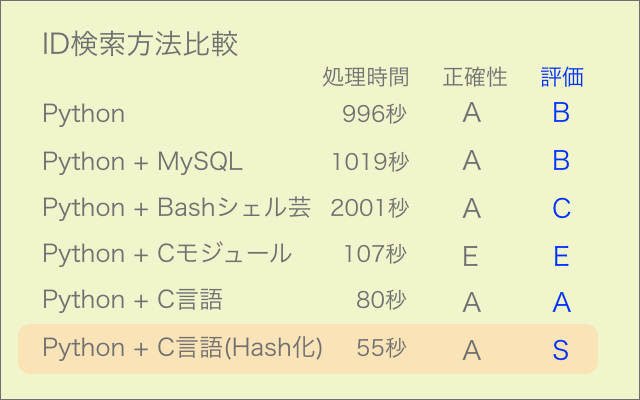
これまでC言語を学習してきて、この言語は文字列の取り扱いが不得手というのがよく分かりました。そのような仕様でもstrcmp関数は1文字づつの比較しかできないながら相当速くなっていると思います。
さらなる高速化を検討した結果、文字列を数字に変換して加減計算等できるようにすれば処理が速くなるのではと考え、ハッシュ関数によるハッシュ化を試してみました。
データベースに馬名のハッシュ値を格納し検索に用いたところ、24000件の処理を80秒から55秒に短縮しました。
sscanf関数が扱いづらくatoi関数の必要性にもなかなか気がつかなかったため、かなり難航しました。
今回は比較する文字列の片方を前もってハッシュ化しましたが、両方処理していたらさらに速くなるはずです。
<修正箇所>
uint32_t horse_hash_int;
while(fgets(buf,2000,fp ) != NULL ) {
if (i != 0){
ret = sscanf(buf, " %[^,],%[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %s",horseID,horse_hash,horse_name,horse_name0,status,gender,hair,birthday,trainer,owner,info,breeder,area,price,prize_money,result,wining_race,relatives) ;
horse_hash_int = atoi(horse_hash);
if(horse_hash_int - fnv_1_hash_32(horse_name_in) == 0){
fp3 = fopen(fname3, "a");
fprintf(fp3," %s,%9s\n",horse_name_in,horseID);
fclose(fp3);
b ++;
break;
}
}
i ++ ;
}