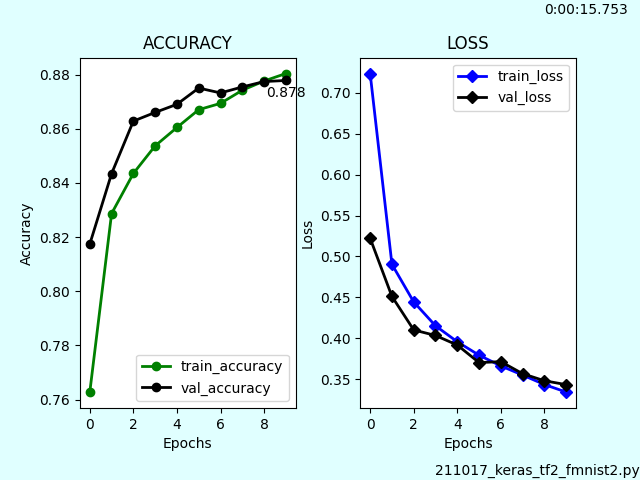
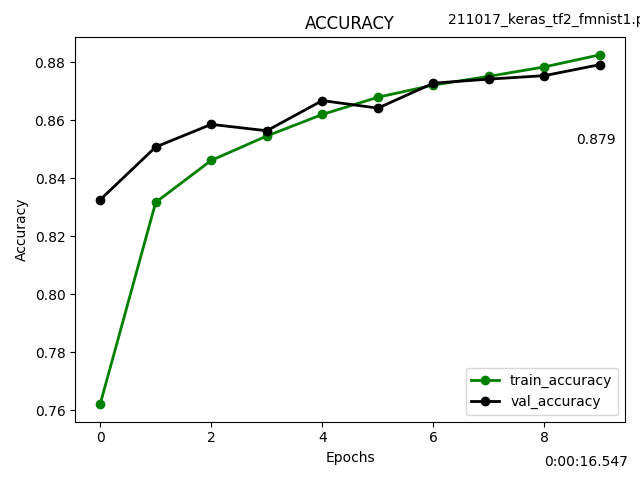
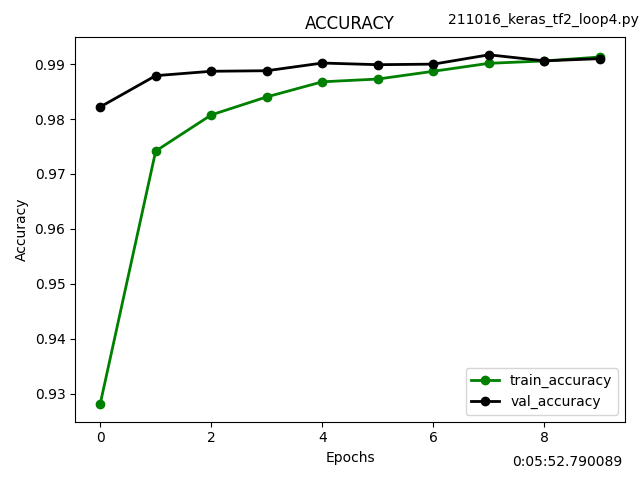
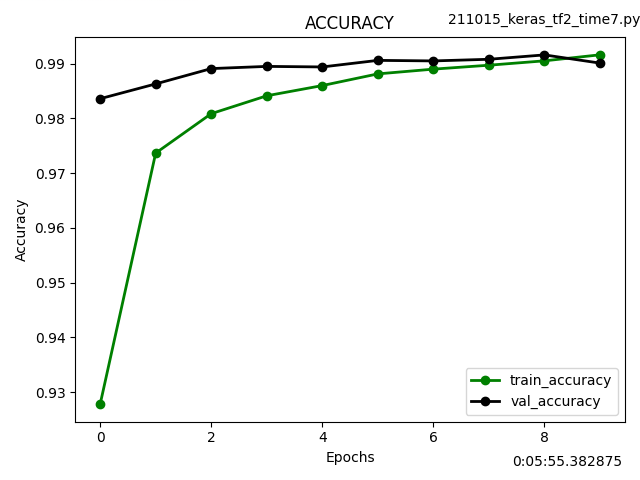
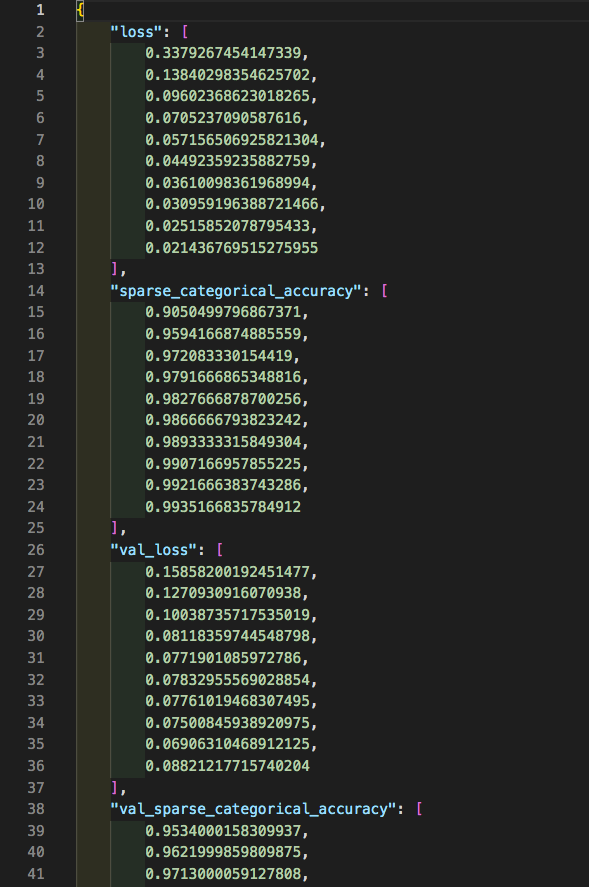
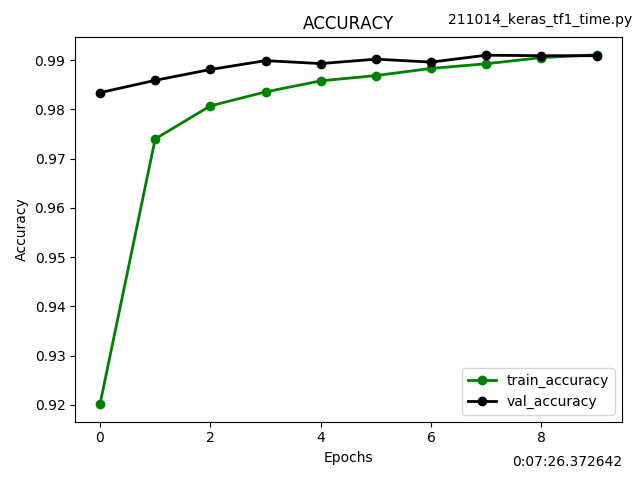
Kerasのfit(), evaluate()を使わずforループで訓練する Custom train loopという方法で学習させてみました。
TensorFlowでは計算の高速化のためデータ型はfloat32を採用しています。そのためfloat64しか受け付けないjson.dumpを使う前には、float32からfloat64に変換しておく必要があります。
プログラマの習性でコードとしての整合性ばかり見がちなので、深層学習の理論も並行して身に付けるよう心掛けたいです。
import tensorflow as tf
from tensorflow.keras import models
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
import matplotlib.pyplot as plt
import time,datetime,os
from stegano import lsb
import numpy as np
import json
def plot_loss_accuracy_graph(data):
<略>
return dt_now_str # 戻り値はグラフ作成日時
def create_model():
model = models.Sequential()
model.add(Conv2D(32, kernel_size=(3, 3),activation='relu'))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
return model
def main():
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
x_train = x_train.astype(np.float32).reshape(60000,28,28,1) / 255.0
x_test = x_test.astype(np.float32).reshape(10000,28,28,1) / 255.0
trainset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
trainset = trainset.shuffle(buffer_size=1024).batch(128)
print(f'len(trainset) {len(trainset)}')
testset = tf.data.Dataset.from_tensor_slices((x_test, y_test))
testset = testset.batch(128)
print(f'len(testset) {len(testset)}')
model = create_model()
loss = tf.keras.losses.SparseCategoricalCrossentropy()
acc = tf.keras.metrics.SparseCategoricalAccuracy()
optim = tf.keras.optimizers.Adam()
@tf.function
def train_on_batch(x, y):
with tf.GradientTape() as tape:
pred = model(x, training=True)
loss_val = loss(y, pred)
graidents = tape.gradient(loss_val, model.trainable_weights)
optim.apply_gradients(zip(graidents, model.trainable_weights))
acc.update_state(y, pred)
return loss_val
# 学習
epochs = 10
loss_list = list()
accuracy_list = list()
val_loss_list = list()
val_accuracy_list = list()
data = dict()
for i in range(epochs):
acc.reset_states()
print("Epoch =", i + 1)
for step, (x, y) in enumerate(trainset):
loss1 = train_on_batch(x, y)
if step % 100 == 0:
print(f"step = {step}, loss = {loss1}, accuracy = {acc.result()}")
elif step == 468:
print(f"step = {step}, loss = {loss1}, accuracy = {acc.result()}")
loss_list.append(loss1.numpy())
accuracy_list.append(acc.result().numpy())
acc.reset_states()
for step, (x, y) in enumerate(testset):
pred = model(x, training=False)
loss2 = loss(y, pred)
acc.update_state(y, pred)
if step == 78:
print(f"test step = {step}, loss = {loss2}, test accuracy = {acc.result()}")
val_loss_list.append(loss2.numpy())
val_accuracy_list.append(acc.result().numpy())
# float32からfloat64に変換
loss_list2 = [float(a) for a in loss_list]
accuracy_list2 = [float(a) for a in accuracy_list]
val_loss_list2 = [float(a) for a in val_loss_list]
val_accuracy_list2 = [float(a) for a in val_accuracy_list]
# 各リストをdict型にまとめてhistory.historyと同じデータ構成にする
data1 = {"loss":loss_list2}
data2 = {"accuracy":accuracy_list2}
data3 = {"val_loss":val_loss_list2}
data4 = {"val_accuracy":val_accuracy_list2}
data.update(**data1,**data2,**data3,**data4)
print(f'data {data}')
# 学習データ・グラフ化
ret = plot_loss_accuracy_graph(data)
json_file = '{}_history_data.json'.format(ret)
with open(json_file ,'w' ) as f:
json.dump(data ,f ,ensure_ascii=False ,indent=4)
model.save(f'{ret}_keras-mnist-model.h5')
if __name__ == "__main__":
main()参考サイト