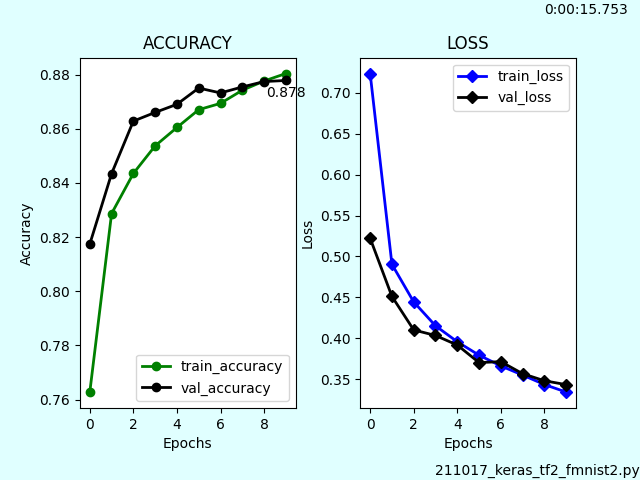
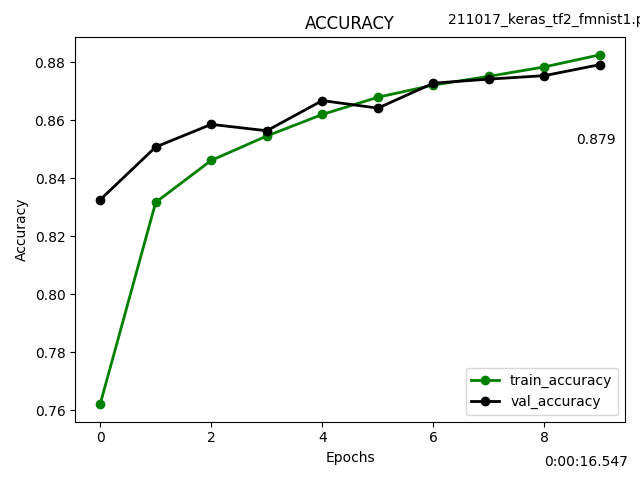
matplotlibの設定箇所が間延びした見た目だったのでスッキリさせました。
グラフ内と枠内にテキスト表示させています。val_accuracyの最後の値をグラフ内表示しています。枠内表示は実行時間とファイル名です。
start = time.time()
def plot_loss_accuracy_graph(history):
process_time = time.time() - start
td = datetime.timedelta(seconds = process_time)
image ='accuracy_loss.png'
fig = plt.figure(facecolor='#e0ffff')
fig.subplots_adjust(bottom=0.15,wspace=0.3)
ax = fig.add_subplot(121, title = 'ACCURACY',xlabel = 'Epochs',ylabel = 'Accuracy')
ax.plot(history.history['accuracy'],"-o", color="green", label="train_accuracy", linewidth=2)
ax.plot(history.history['val_accuracy'],"-o",color="black", label="val_accuracy", linewidth=2)
ax.legend(loc="lower right")
# グラフ内テキスト表示
ax.text(len(history.history['val_accuracy']) -1, history.history['val_accuracy'][-1]-0.002, '{:.3f}'.format(history.history['val_accuracy'][-1]),verticalalignment='top',horizontalalignment='center')
ax2 = fig.add_subplot(122, title = 'LOSS',xlabel = 'Epochs',ylabel = 'Loss')
ax2.plot(history.history['loss'], "-D", color="blue", label="train_loss", linewidth=2)
ax2.plot(history.history['val_loss'], "-D", color="black", label="val_loss", linewidth=2)
ax2.legend(loc='upper right')
# 枠内テキスト表示
fig.text(0.68, 0.01, os.path.basename(__file__))
fig.text(0.85, 0.97, str(td)[:11])
fig.savefig(image)