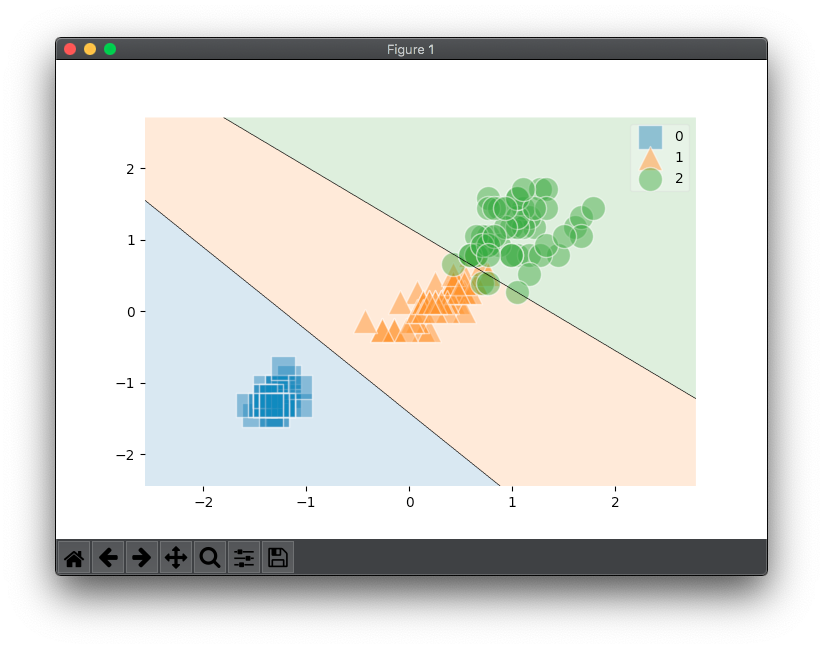
前回の続きです。
アヤメの花弁データ(3列目と4列目)をサポートベクターマシン(SVM)を使って超平面で分類できるようにしました。
手順としては、データを標準化してからSVMのインスタンスを生成してモデル学習させ散布図を作成します。最後に適当な花弁データを入力してアヤメのどの種に該当するのか判定させています。
私の教本ではその前にデータを交差検証するために学習データと検証データに分けて、検証後に標準化データを結合して超平面を作成しています。
本の構成のためでしょうが、教本の方法は少々荒っぽいかと思います。統計学をかじったことのある方でしたら理由は分かるでしょう。
import numpy as np
import matplotlib.pyplot as plt
from mlxtend.plotting import plot_decision_regions as pdr
from sklearn import datasets
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
def test():
model = analize()
test_data=np.array([[3.0,4.0]])
print(test_data)
test_result = model.predict(test_data)
print(test_result)
plt.show()
def analize():
iris = datasets.load_iris()
features = iris.data[:,[2,3]]
print(features)
labels = iris.target
sc = StandardScaler()
sc.fit(features)
# データの標準化(中心を0にするための変換)
features_std = sc.transform(features)
print(features_std)
# 線形SVMのインスタンスを生成
model = SVC(kernel='linear', random_state=None)
# モデル学習
model.fit(features_std, labels)
fig = plt.figure(figsize=(12,8))
# 散布図関連設定
scatter_kwargs = {'s': 300, 'edgecolor': 'white', 'alpha': 0.5}
contourf_kwargs = {'alpha': 0.2}
scatter_highlight_kwargs = {'s': 200, 'label': 'Test', 'alpha': 0.7}
pdr(features_std, labels, clf=model, scatter_kwargs=scatter_kwargs,
contourf_kwargs=contourf_kwargs,
scatter_highlight_kwargs=scatter_highlight_kwargs)
return model
if __name__ == "__main__":
test()
--------------------------------------------------
出力(検証データと判定結果のみ)
--------------------------------------------------
[[3. 4.]]
[2]