[Mac M2 Pro 12CPU, Sonoma 14.3.1, clang++ 15.0.0]
LLMのランタイムであるllama.cppのmake時にセグフォ11が発生しました。
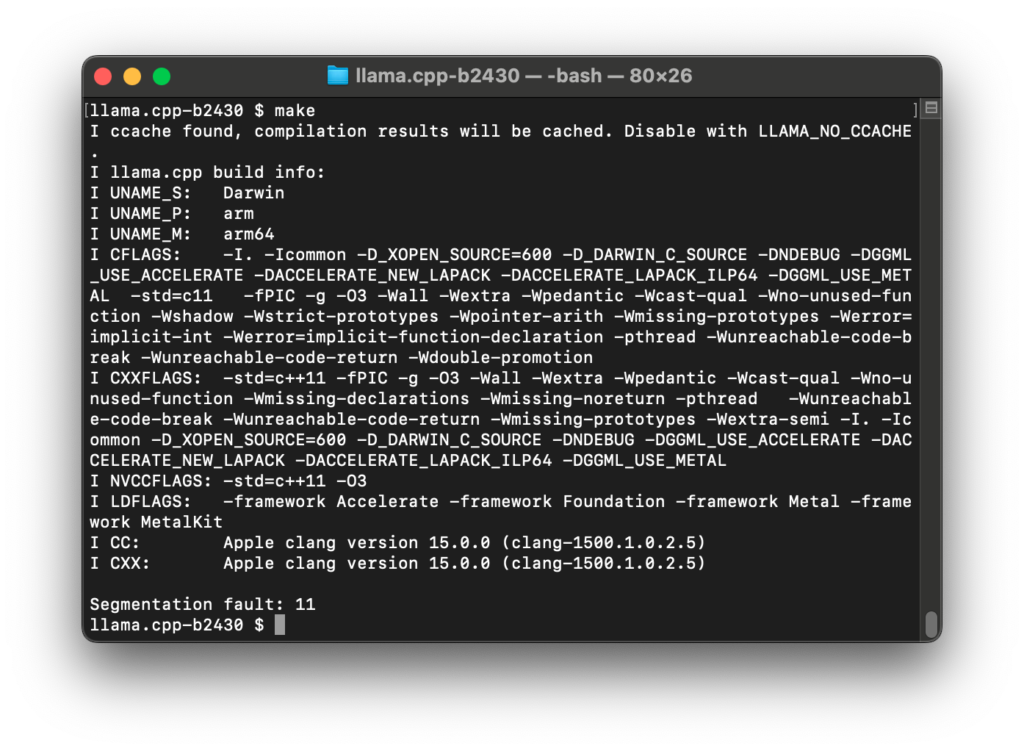
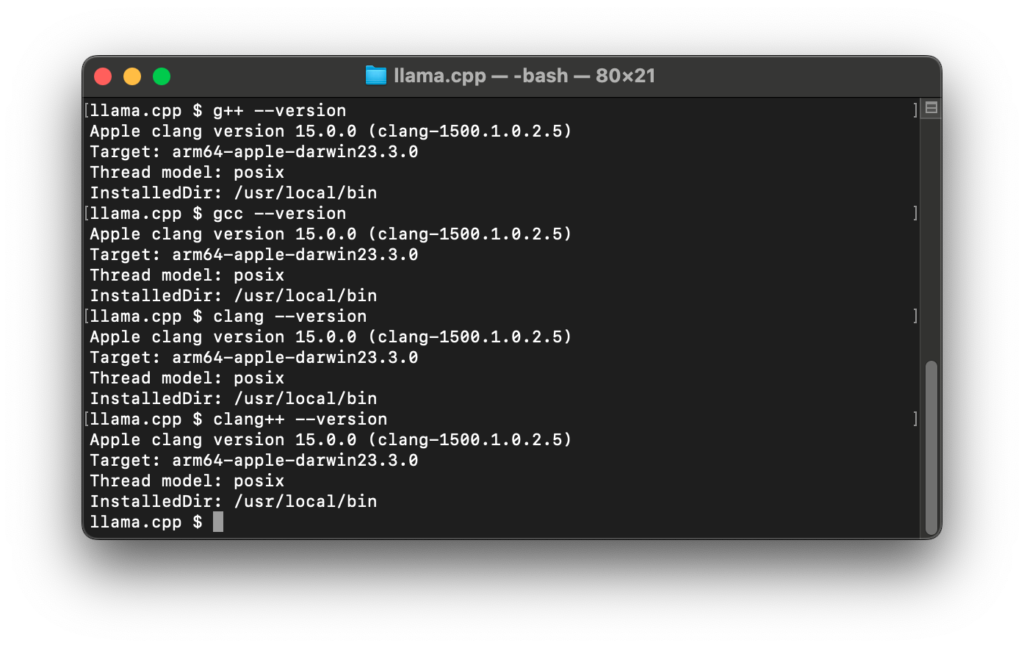
コンパイラがclangなのが問題なのかと考え、gccとg++に置き換えましたがダメでした。
Xcode内にあるclangのシンボリックリンクをgcc、g++にリネームして/usr/local/binに置いても状況は変わらず。
/usr/binにあるgccとg++(共に中身はclang)を認識させるようにすると、やっとmakeできました。.bash_profileの行を一部入れ替えて/usr/binの優先順位を上げています。
# /usr/binの優先順位を上げる
export PATH=/usr/local/bin:$PATH
export PATH=/usr/bin:$PATH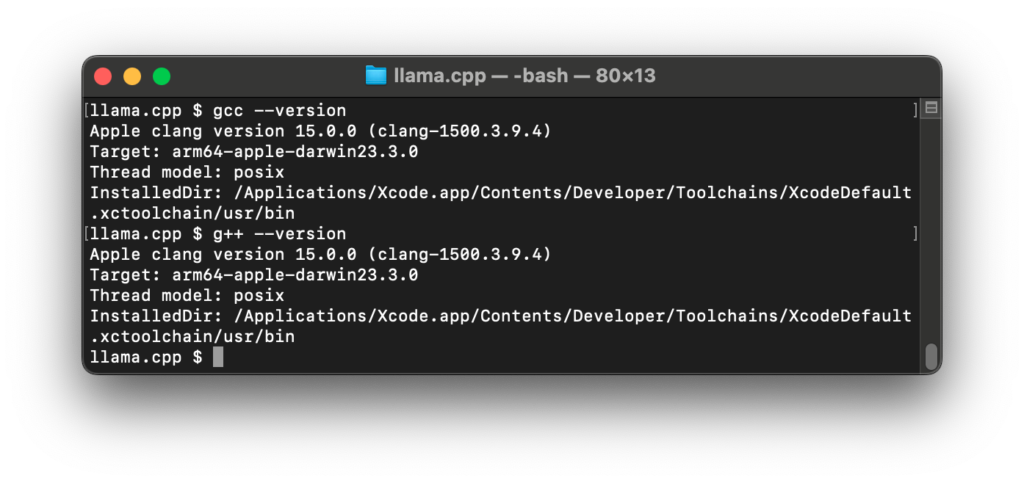
llama.cpp開発者がMacユーザーはCコンパイラをデフォルトのままで使用するものと想定しているために起こったトラブルでした。
gcc、g++についてclangではなく正規ファイルを使っているMacユーザーの存在は考慮していません。23年4月までのllama.cppでは正規ファイルでもビルド可能でした。ただし、その頃はモデル形式がGGMLだったため、現在のGGUFタイプのモデルは使用不可です。
make中のトラブルをデバッグする手段がなく途方に暮れましたが、Cコンパイラが動作するタイミングでセグフォ11が発生していることから推測して何とか解決できました。
gcc、g++の正規ファイルを使用しているMacユーザーのLLM使いは案外少ないのか、llama.cppのGitHubやStackOverFlowでこのような話題はありませんでした。
このトラブルの解決に丸一日費やしてしまいました。