import tkinter as tk
import tkinter.font as font
from tkinter import ttk
class Horse(tk.Tk):
def __init__(self, master=None):
super().__init__(master)
self.title("HORSE SEARCH")
self.geometry("310x130")
self.configure(background = '#B0E0E6')
self.create_menu()
# Horseのグリッドを 1x1 にする
self.grid_rowconfigure(0, weight=1)
self.grid_columnconfigure(0, weight=1)
def create_menu(self):
menubar = tk.Menu(self)
# 親メニューの設定
menu_kinou = tk.Menu(menubar)
menubar.add_cascade(label='機能', menu=menu_kinou)
# 子メニューの設定
menu_kinou.add_command(label='馬名検索', command=create_A)
menu_kinou.add_separator()
menu_kinou.add_command(label='レース検索', command=create_B)
self.config(menu=menubar)
class FrameA(tk.Frame):
def __init__(self, master=None):
super().__init__(master)
self.configure(background = '#B0E0E6')
self.grid(row=0,column=0, sticky=tk.NSEW, padx=5, pady=10)
self.create_widgets()
def create_widgets(self):
# ラベルの作成・配置
label = tk.Label(self,text='馬名',background = '#B0E0E6',foreground = '#8b0000',font=my_font)
label.grid(row=0, column=0)
# パス入力エントリの作成・配置
entry = tk.Entry(self,width=15,background = '#98fb98',foreground = '#8b0000',font=my_font)
entry.grid(row=0,column=1)
# 実行ボタンの作成・配置
btn = tk.Button(self, text="検索",command=lambda:var.set(1),width=2,font=my_font)
btn.grid(row=0,column=2,padx=2)
# クリアボタンの作成・配置
btn2 = tk.Button(self, text="クリア",command=lambda:entry.delete(0,tk.END),width=2,font=my_font2)
btn2.grid(row=1,column=2,padx=2)
class FrameB(tk.Frame):
def __init__(self, master=None):
super().__init__(master)
self.configure(background = '#B0E0E6')
self.grid(row=0,column=0, sticky=tk.NSEW, padx=5, pady=10)
self.create_widgets()
def create_widgets(self):
# frameB2,frameB3の作成
frameB2 = tk.Frame(self,background = '#B0E0E6')
frameB2.grid(row=1,column=1, sticky=tk.NSEW, padx=5, pady=0)
frameB3 = tk.Frame(self,background = '#B0E0E6')
frameB3.grid(row=2,column=1, sticky=tk.NSEW, padx=5, pady=0)
# frameBラベル1の作成・配置
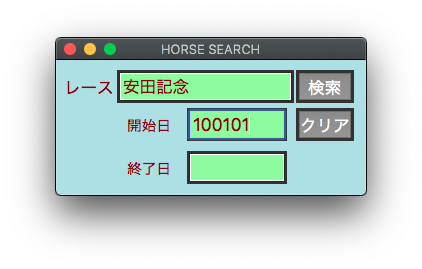
labelB = tk.Label(self,text='レース',background = '#B0E0E6',foreground = '#8b0000',font=my_font)
labelB.grid(row=0, column=0)
# frameBラベル2の作成・配置
labelB2 = tk.Label(self,text='開始日',background = '#B0E0E6',foreground = '#8b0000',font=my_font2)
labelB2.grid(row=1, column=1,sticky=tk.W)
# frameBラベル3の作成・配置
labelB3 = tk.Label(self,text='終了日',background = '#B0E0E6',foreground = '#8b0000',font=my_font2)
labelB3.grid(row=2, column=1,sticky=tk.W)
# frameBエントリ1の作成・配置
entryB = tk.Entry(self,width=15,background = '#98fb98',foreground = '#8b0000',font=my_font)
entryB.grid(row=0,column=1)
# frameBエントリ2の作成・配置
entryB2 = tk.Entry(frameB2,width=8,background = '#98fb98',foreground = '#8b0000',font=my_font)
entryB2.pack(padx=2,side=tk.RIGHT)
# frameBエントリ3の作成・配置
entryB3 = tk.Entry(frameB3,width=8,background = '#98fb98',foreground = '#8b0000',font=my_font)
entryB3.pack(padx=2,side=tk.RIGHT)
# frameB実行ボタンの作成・配置
btnB = tk.Button(self, text="検索",command=lambda:var.set(2),width=2,font=my_font)
btnB.grid(row=0,column=2,padx=2)
# frameBクリアボタンの作成・配置
btnB2 = tk.Button(self, text="クリア",command=lambda:entryB.delete(0,tk.END),width=2,font=my_font)
btnB2.grid(row=1,column=2,padx=2)
def create_A():
global frame
frame.destroy
children[-3].delete(0,tk.END)
frame = FrameA(master=horse)
def create_B():
global frame
frame.destroy
children[1].delete(0,tk.END)
frame = FrameB(master=horse)
# ウィンドウの作成
horse = Horse(master=None)
# フォント設定
my_font = font.Font(horse,family="System",size=18,weight="normal")
my_font2 = font.Font(horse,family="System",size=16,weight="normal")
# フレームの作成
frame = FrameA(master=horse)
# IntVarの初期化
var = tk.IntVar()
for i in range(1000):
print(f'var for文先頭 {var.get()}')
children = frame.winfo_children()
print(f'children {children}')
if var.get() == 0 or var.get() == 1:
print('分岐A')
# 馬名の入力を待機
children[2].wait_variable(var)
# 入力した馬名を取得
name = children[1].get()
print(f'name {name}')
# 馬名検索モジュールは省略
else:
print('分岐B')
children = frame.winfo_children()
print(f'elseウィジェットinfo\n{children}\n')
# レース名の入力を待機
children[-2].wait_variable(var)
# 入力したレース名を取得
race = children[-3].get()
print(f'race {race}')
# レース検索モジュールは省略
frame.mainloop()