[Python]220の続編です。
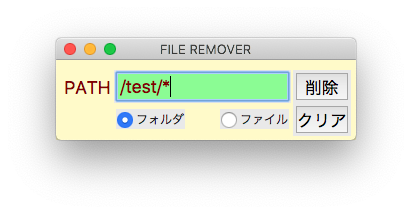
下図のように/test/*などと入力するとプログラムにより/*が追記され、孫ファイル、孫フォルダのみを削除できます。
[Python]220の続編です。
下図のように/test/*などと入力するとプログラムにより/*が追記され、孫ファイル、孫フォルダのみを削除できます。
使い回ししやすいようにメモ書きしておきます。子フォルダ、孫フォルダの一括作成です。
macOSではディレクトリという表現が正しいようですが、字数が少ないのでフォルダを使っています。
f文字列による表記です。
import os
# 2021年各競馬場フォルダを各開催分作成する。競馬場コード、開催回は2桁表記。
l=[2,1,2,5,5,5,6,0,6,4]
for i,e in enumerate(l):
os.mkdir(f'/horse_racing/race/2021/{i+1:02}')
for c in range(e):
os.mkdir(f'/horse_racing/race/2021/{i+1:02}/{c+1:02}')
Windows10で作成したCSVファイルに余計な改行が含まれていたので下記コードで削除しました。
# file1,file2の設定は省略
with open(file1, 'r', encoding='shift_jis') as f1:
with open(file2, 'w', encoding='shift_jis') as f2:
rows = []
reader = csv.reader(f1)
for row in reader:
for i,v in enumerate(row):
row[i] = v.replace('\n', '')
rows.append(row)
writer = csv.writer(f2)
for row in rows:
writer.writerow(row)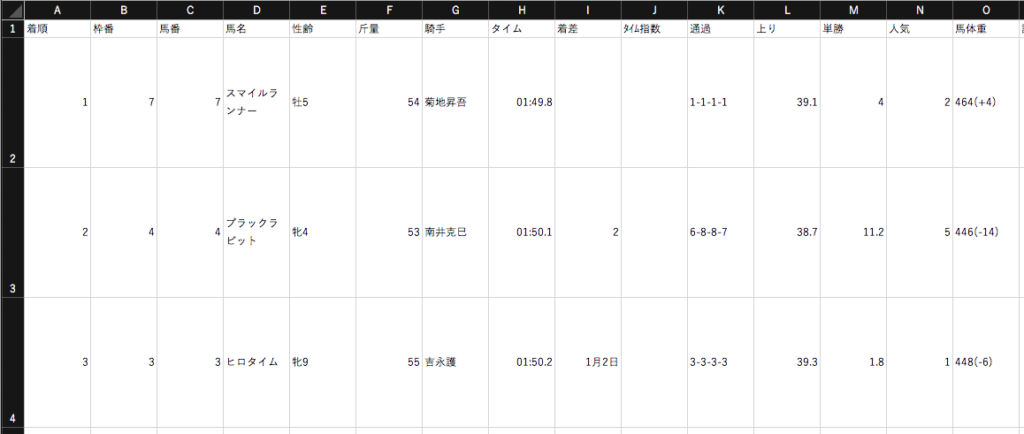

レースファイルの馬名から馬名ファイルにあるhorseIDを取り出すコードを作成しました。
書いた本人にしかわからない内容ですが、pandasを扱って案の定苦戦したので記録を残しておきます。
手順としてはレースファイルから各着順の馬名を取り出し年齢から誕生年(満年齢の場合はレース年-年齢)を算出。誕生年の馬名リストからhorseIDを取得し、レースファイルの最後列に追記します。
データフレームはあくまでも配列であり一次元であってもリストとして扱わないことを今後は肝に銘じます。
import glob
import pandas as pd
import csv,re
# 1986年から2020年のレースファイルにhorseID列を追加する
for year in range(1986,2021):
for f in glob.glob(f'/horse_racing/race_result_mas/{year}/*/*/*.csv'):
file_new = f.split('race_result_mas/')[0] + 'race_result/' + f.split('race_result_mas/')[1]
with open (f, mode="r", encoding="shift_jis") as f1:
with open(file_new, mode="w", encoding="shift_jis") as f2:
writer = csv.writer(f2)
for i,row in enumerate(csv.reader(f1)):
if i != 0:
if year >=2001: # 満年齢
birthyear = int(year) - int(re.sub("\\D", "", row[4]))
else: # 2000年以前は数え年
birthyear = int(year) - int(re.sub("\\D", "", row[4])) + 1
# 誕生年馬名ファイル
namefile = f'/horse_racing/horse/horse{birthyear}.csv'
try:
df = pd.read_csv(namefile,encoding="shift_jis")
except:
horseID = '1985年以前'
else:
# 各行の馬名セルにレースファイルの馬名を含む場合にTrueとする縦向き配列を作成
b_array = df[df.columns[1]].str.contains(row[3])
# ブール値の横向き配列として取り出しリスト化
b_array_v = b_array.values.tolist()
# Trueのインデックス値を算出しhorseIDを取得
try:
i = b_array_v.index(True)
except:
horseID = '該当なし'
else:
print(f'index {i}')
horseID = df.iloc[i,0]
print(f'{row[3]} {birthyear} {horseID}')
rows = row[0:22] + [horseID]
writer.writerow(rows)
else: # タイトル行(0行目)
rows = row[0:22] + ['horseID']
writer.writerow(rows)
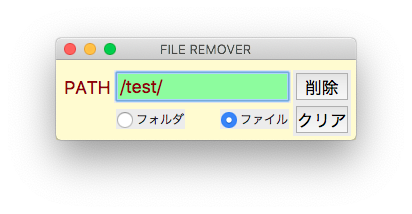
ファイルやフォルダを一括削除するツールを作成しました。
[Python] 206で紹介したJSON CSV相互コンバータのGUIを流用しています。
削除したいファイルのあるフォルダのパスを入力するだけです。フォルダかファイルを選択できます。下層ファイルも削除するのでフォルダだけの骨格が残ります。
コードは以下の通りです。PyInstallerでexeファイルを作成しました。
import glob,os,shutil
import sys,json
import tkinter as tk
import tkinter.font as font
from tkinter import ttk
root = tk.Tk()
root.title("FILE REMOVER")
root.geometry("300x80")
root.configure(bg='#FFFACD')
# 設定
my_font = font.Font(root,family="System",size=18,weight="normal")
# フレームの作成・配置
frame = tk.Frame(root,background = '#FFFACD')
frame.grid(row=0,column=0, sticky=tk.NSEW, padx=5, pady=10)
# ラベルの作成・配置
label = tk.Label(frame,text='PATH',background = '#FFFACD',foreground = '#8b0000',font=my_font)
label.grid(row=0, column=0)
# パス入力エントリの作成・配置
entry = tk.Entry(frame,width=15,background = '#98fb98',foreground = '#8b0000',font=my_font)
entry.grid(row=0,column=1)
# 実行ボタンの作成・配置
var_act = tk.IntVar()
btn = tk.Button(frame, text="削除",command=lambda:var_act.set(1),width=2,font=my_font)
btn.grid(row=0,column=2,padx=2)
# クリアボタンの作成・配置
btn2 = tk.Button(frame, text="クリア",command=lambda:entry.delete(0,tk.END),width=2,font=my_font)
btn2.grid(row=1,column=2,padx=2)
# ラジオボタンの作成・配置
var = tk.IntVar()
rb1 = ttk.Radiobutton(frame,text='フォルダ',value=1,variable=var)
rb1.grid(row=1,column=1,padx=2,pady=5,sticky=tk.W)
rb2 = ttk.Radiobutton(frame,text='ファイル',value=2,variable=var)
rb2.grid(row=1,column=1,padx=2,pady=5,sticky=tk.E)
for i in range(100): # 100回処理可能
# フォルダパスの入力を待機
btn.wait_variable(var_act)
# 入力したフォルダパスを取得
dirpath = entry.get()
# ラジオボタンのvalueを取得
v = var.get()
if v == 1:
path = dirpath + '/*' # 直下のフォルダを削除
for f in glob.glob(path):
if os.path.isdir(f):
shutil.rmtree(f)
else:
path = dirpath + '/**' # 再帰的処理により下層ファイルも削除
for f in glob.glob(path, recursive=True):
if os.path.isfile(f):
os.remove(f)
root.mainloop()
CSVファイルの行と列の入れ替えはpandasやnumpyでもできますが、今回はCSVモジュールでやってみました。
読み込んだ行データを列毎に分割、リスト化して行データにする手法です。そのようなメソッドがないため手作りするしかありません。
pandasでは列インデックスや行インデックスについても考慮しなければならないので、CSVモジュールの方が私には楽です。
コード例
各馬のデータを年毎にまとめる。
import glob
import csv
# 1986年から2020年のhorseファイルを年毎にまとめる
for year in range(1986,2021):
for f in glob.glob(f'/horse_racing/horse_mas/{year}/*/*.csv'):
file_new = f.split('horse_mas/')[0] + 'horse/' + f'horse{year}' + '.csv'
with open (f, mode="r", encoding="shift_jis") as f1:
with open(file_new, mode="a", encoding="shift_jis") as f2:
writer = csv.writer(f2)
row1_pre = []
row2_pre = []
for row in csv.reader(f1):
row1_pre.append(row[0])
row2_pre.append(row[1])
row1 = ['horseID'] + row1_pre # 列タイトル
row2 = [f[-13:-4]] + row2_pre # 馬データ
if f[-9:-4] == '00001': # 各年1番の馬には列タイトルをつける
writer.writerow(row1[0:15])
writer.writerow(row2[0:15])
else:
writer.writerow(row2[0:15])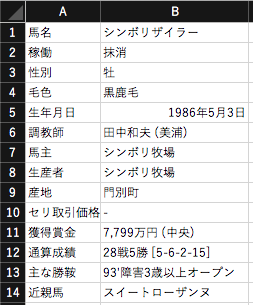
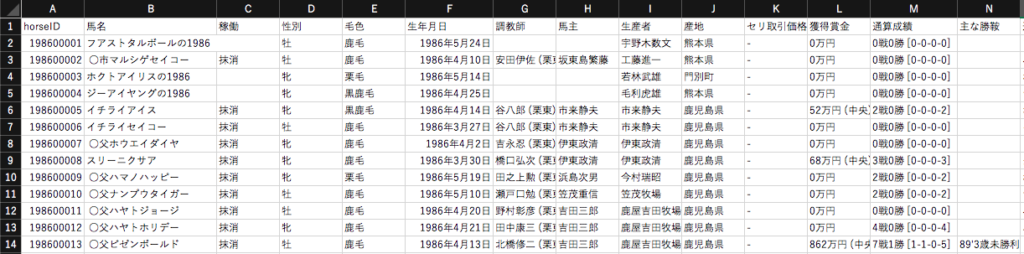
備忘のためメモ書きしておきます。
コード例
年フォルダ内のフォルダ(ファイル含)を全て消去
import glob,os,shutil
for year in range(1986,2021):
for f in glob.glob(f'/horse_racing/race_name/{year}/*'):
if os.path.isdir(f):
shutil.rmtree(f)
年フォルダ内のファイルを全て消去
import glob,os
for year in range(1986,2021):
for f in glob.glob(f'/Volumes/DATA_HR/horse_racing/race_name/{year}/*'):
if os.path.isfile(f):
os.remove(f)
複数のCSVファイルからある行を抽出し、1つのファイルにまとめるコードです。
with文を追記モード(mode = ‘a’)にします。
一連のCSVファイル処理でCSVモジュールの使いやすさを認識しました。
数値データの配列ではなく単なる表として扱うのであれば、pandasよりもこちらの方が適しているように思います。
コード例は[Python]215の図にあるレースファイルから図右下のレース名他を抽出します。
import glob,csv
# 1986年から2020年のレースファイルからレース名他を抽出して競馬場毎にまとめる
for year in range(1986,2021):
for f in glob.glob(f'/horse_racing/race/{year}/*/*/*.csv', recursive=True):
file_new = f.split('race/')[0] + 'race_name/' + f.split('race/')[1][:-26] + f'race_n_{year}' + f.split('race/')[1][-26:-24] + '.csv'
with open (f, mode="r", encoding="shift_jis") as f1:
with open(file_new, mode="a", encoding="shift_jis") as f2: # 追記モード
writer = csv.writer(f2)
for i,row in enumerate(csv.reader(f1)):
if i != 0: # 行0の列インデックスは削除
if '010101' == f[-10:-4]: # 1回1日1Rだけ列タイトルを書き込み
if i == 1: # 列タイトル
rows = [e[2:] for e in row[21:30]] + ['raceID']
writer.writerow(rows)
if '年' in row[21]: # 列21に'年'がある行を書き込み
rows = row[21:30] + [f[-20:-4]]
writer.writerow(rows)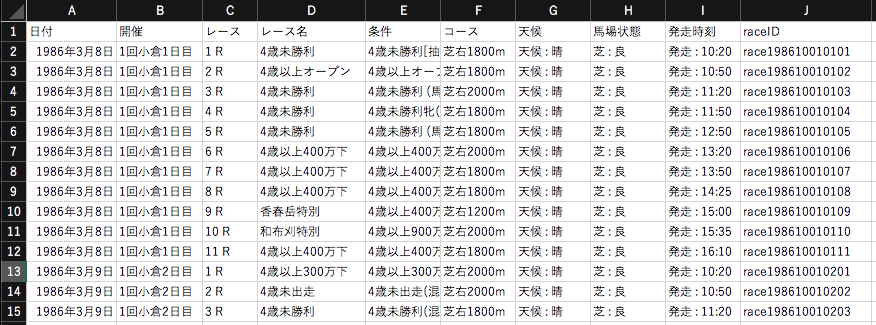
前回記事で扱ったフォルダ内のファイルをカウントしてみました。
os.path.isfile関数でファイルかどうかを一応判定します。
import glob,os
# 1986年から2020年のレースファイルをカウントする
count_all = 0
year_count = []
for year in range(1986,2021):
count = 0
for f in glob.glob(f'/horse_racing/race/{year}/*/*/*.csv', recursive=True):
if os.path.isfile(f):
count +=1
count_all += 1
year_count.append({year:count})
print(count_all)
print(year_count)
--------------------------------------------------
出力
--------------------------------------------------
119460
[{1986: 3274}, {1987: 3283}, {1988: 3307}, {1989: 3335}, {1990: 3353}, {1991: 3389}, {1992: 3399}, {1993: 3425}, {1994: 3429}, {1995: 3417}, {1996: 3407}, {1997: 3433}, {1998: 3443}, {1999: 3415}, {2000: 3451}, {2001: 3448}, {2002: 3452}, {2003: 3449}, {2004: 3452}, {2005: 3438}, {2006: 3453}, {2007: 3453}, {2008: 3436}, {2009: 3453}, {2010: 3454}, {2011: 3444}, {2012: 3454}, {2013: 3454}, {2014: 3431}, {2015: 3454}, {2016: 3454}, {2017: 3455}, {2018: 3158}, {2019: 3452}, {2020: 3456}]下図のように、レース結果、レース名、レースラップ、列インデックスが混在しているCSVファイルからレース結果のみを抜き出しました。
データベース化のための前処理です。
ちなみにExcel初級者が1ファイル30秒の手作業で処理するとしたら、1日8時間労働、月稼働20日とした場合、約半年かかります。このコードなら12万ファイルが70秒です。
120000ファイル × 0.5分 / 60分 / 8時間 / 20日 = 6.25ヶ月
しかしコードを書く人よりも、我慢強く手作業に取り組む人の方が評価されたりするのですから、日本の組織というのはなかなかのもんです。
import glob
import pandas as pd
import csv
# 1986年から2021年のレースファイルから結果のみを抽出する。/年/競馬場コード/回/*.csv
for year in range(1986,2022):
for f in glob.glob(f'/horse_racing/race/{year}/*/*/*.csv', recursive=True):
file_new = f.split('race/')[0] + 'race_result/' + f.split('race/')[1]
with open (f, mode="r", encoding="shift_jis") as f1:
with open(file_new, mode="w", encoding="shift_jis") as f2:
writer = csv.writer(f2)
for i,row in enumerate(csv.reader(f1)):
# 行0の列インデックスは削除
if i != 0:
# 列0にラップ、ペースが含まれていればTrue
word = ['ラップ'in row[0],'ペース'in row[0]]
# どちらもFalseであれば列0から列20を書き込みする
if not any(word):
writer.writerow(row[0:21])