[M1 Mac, Ventura 13.3.1, Python 3.10.4]
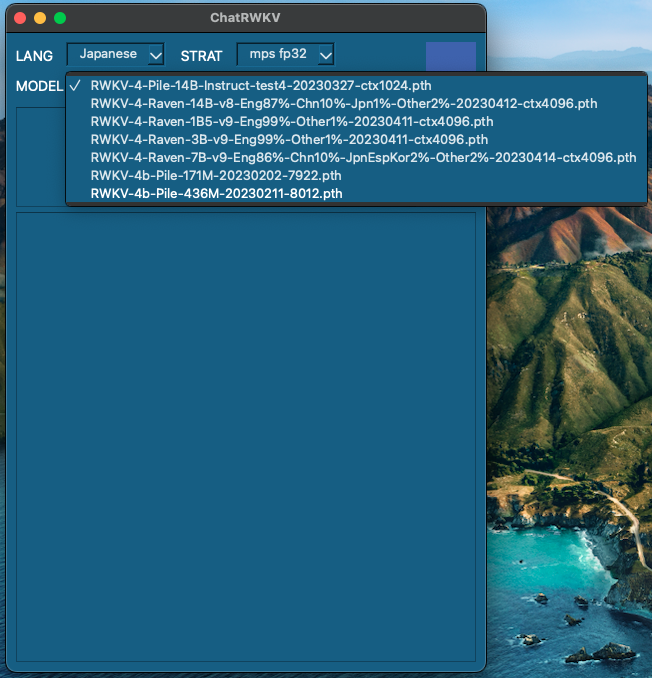
ChatRWKVアプリでmodel, language, strategyを選択できるようにしました。スクリプトをいちいち書き換える手間が省けるので、検証用ツールとして有用です。
chat.pyからメイン部分と各関数を抽出してクラスにまとめています。C++とは別種のややこしさがあってかなり手間取りました。
C/C++ではexternやヘッダファイルを駆使してファイル間で変数を自在に使っていますが、Pythonでは循環importになってしまい、いらいらが募ります。まあC/C++が自由すぎるのでしょう。
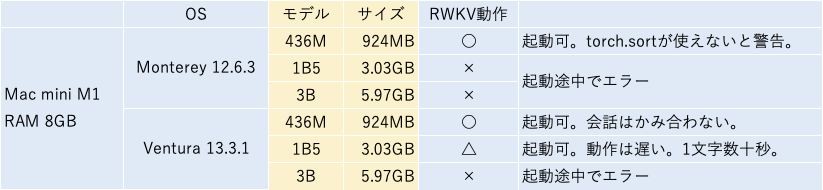
チャットボットを使ってみたところ、M1 Mac RAM 8GBで速度的に問題なく動作する436Mのモデルでは会話にならないです。
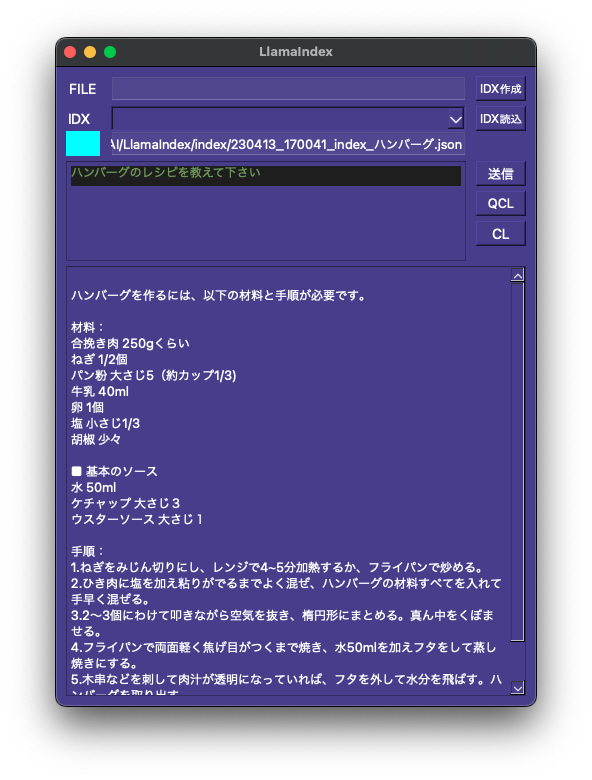
これで検証用ツール製作という目的はほぼ達成しましたが、ここまできたらGUI上で会話できるようにしたいです。
import os, copy, types, gc, sys
import numpy as np
from prompt_toolkit import prompt
import torch
END_OF_TEXT = 0
END_OF_LINE = 187
CHUNK_LEN = 256 # split input into chunks to save VRAM (shorter -> slower)
CHAT_LEN_SHORT = 40
CHAT_LEN_LONG = 150
FREE_GEN_LEN = 256
GEN_TEMP = 1.1 # It could be a good idea to increase temp when top_p is low
GEN_TOP_P = 0.7 # Reduce top_p (to 0.5, 0.2, 0.1 etc.) for better Q&A accuracy (and less diversity)
GEN_alpha_presence = 0.2 # Presence Penalty
GEN_alpha_frequency = 0.2 # Frequency Penalty
AVOID_REPEAT = ',:?!'
class chat_base():
def __init__(self):
self.model_tokens = []
self.model_state = None
self.all_state = {}
self.user = None
self.bot = None
self.interface = None
self.init_prompt = None
self.pipeline = None
def load_model(self, lang, strat, model):
self.lang = lang
self.strat = strat
self.model = model
CHAT_LANG = self.lang # English // Chinese // more to come
PROMPT_FILE = f'/Volumes/DATA_m1/AI/ChatRWKV_work/ChatRWKV/v2/prompt/default/{CHAT_LANG}-2.py'
self.load_prompt = self.load_prompt(PROMPT_FILE)
sys.path.append('/Volumes/DATA_m1/AI/ChatRWKV_work/ChatRWKV/rwkv_pip_package/src')
try:
os.environ["CUDA_VISIBLE_DEVICES"] = sys.argv[1]
except:
pass
np.set_printoptions(precision=4, suppress=True, linewidth=200)
args = types.SimpleNamespace()
print('\n\nChatRWKV v2 https://github.com/BlinkDL/ChatRWKV')
torch.backends.cudnn.benchmark = True
torch.backends.cudnn.allow_tf32 = True
torch.backends.cuda.matmul.allow_tf32 = True
<以下略>