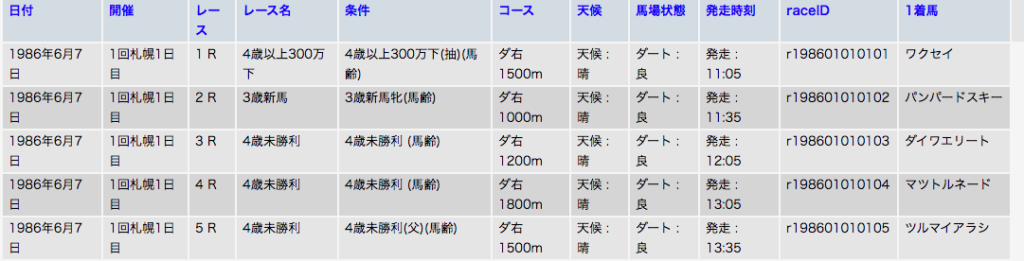
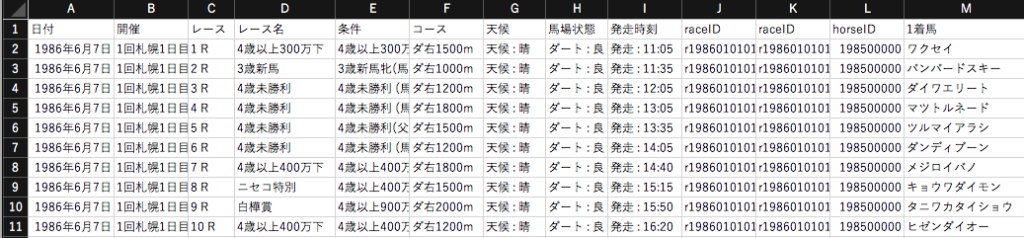
レースDBに1着馬名の列を追加しました。
mysql.connectorではデータフレームをSQLテーブルに変換できないので、PyMySQLを使いました。
今回のケースではわざわざデータフレームに変換しなくても、ALTER TABLE文で列削除できたのかもしれません。
import csv,glob
import pandas as pd
import pymysql
import sqlalchemy as sqa
# 対象ファイルパスのリストを作成
file_l = [path for path in glob.glob('/horse_racing/race_name/*/*.csv')]
# ファイルパスから拡張子なしのファイル名を抽出
table_l = [path[-17:-4] for path in file_l]
# mysqlに接続
url = 'mysql+pymysql://<username>:<password>@<host>'
engine = sqa.create_engine(url, echo=True)
# データベースhorse_race_nameとhorse_race_winnerのテーブルを結合して不要な列を削除後、MySQLに戻す
for table in table_l:
year = table[-6:-2]
sql = f'SELECT * FROM horse_race_name.{table} INNER JOIN \
horse_race_winner.{year}_1着馬リスト ON horse_race_name.{table}.raceID \
= horse_race_winner.{year}_1着馬リスト.raceID'
data = pd.read_sql_query(sql=sql, con=engine)
data_new = data.drop(data.columns[[-2]], axis=1)
data_new.to_sql(name=f'{table}', con=engine, schema='horse_race_name', \
if_exists='replace', index=False)