前回の続きです。
Requests+BeautifulSoupでスクレイピング の速度を測ったところlibcurlと同等でした。
通常はRequests、クリックやページ遷移などブラウザ操作する場合はselenium、好事家はlibcurlというのが結論です。
<該当箇所のみ>
response = requests.get(url)
soup = BeautifulSoup(response.text.encode('utf-8'), "html.parser")前回の続きです。
Requests+BeautifulSoupでスクレイピング の速度を測ったところlibcurlと同等でした。
通常はRequests、クリックやページ遷移などブラウザ操作する場合はselenium、好事家はlibcurlというのが結論です。
<該当箇所のみ>
response = requests.get(url)
soup = BeautifulSoup(response.text.encode('utf-8'), "html.parser")seleniumの動きがもっさりしているため、C/C++のlibcurlというライブラリで高速化を試みました。スクレイピング先のhtmlをまるごとダウンロードして解析し、テキストを抽出してcsvファイルにまとめるという流れです。
その結果、こちらが引くくらい速くなったので全編C言語で書く必要はなくなり、html解析はPythonライブラリのBeautifulSoupで実施しました。スクレイピング先に負荷をかけないようtime.sleepでループの速度を遅くしています。
C言語の方は参考サイトのコードに少しだけ手を入れて完成させました。
今思えばここまでやらなくてもRequests + BeautifulSoupであればPythonだけで高速化できていたかもしれません。時間があれば検証します。
21/07/17追記:C言語にこだわらなければ、以下のコマンドをsubprocessモジュールで走らせてhtmlをダウンロードするのが最も簡単だと思います。
curl “スクレイピング先のurl” > 出力先
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <curl/curl.h>
#define EXIT_SUCCESS 0
FILE *fp; // 入力ファイル
FILE *fp2; // 出力ファイル
char fname[] = "horse_url.txt";
char fname2[] = "curl.html";
char buffer[100];
char horse_url[100];
struct Buffer {
char *data;
int data_size;
};
size_t buffer_writer(char *ptr, size_t size, size_t nmemb, void *stream) {
struct Buffer *buf = (struct Buffer *)stream;
int block = size * nmemb;
if (!buf) {
return block;
}
if (!buf->data) {
buf->data = (char *)malloc(block);
}
else {
buf->data = (char *)realloc(buf->data, buf->data_size + block);
}
if (buf->data) {
memcpy(buf->data + buf->data_size, ptr, block);
buf->data_size += block;
}
return block;
}
int main(void) {
CURL *curl;
struct Buffer *buf;
buf = (struct Buffer *)malloc(sizeof(struct Buffer));
buf->data = NULL;
buf->data_size = 0;
fp = fopen(fname, "r");
while(fgets(buffer,100, fp) != NULL ) {
sscanf(buffer,"%s",horse_url);
}
fclose(fp);
curl = curl_easy_init();
curl_easy_setopt(curl, CURLOPT_URL, horse_url);
curl_easy_setopt(curl, CURLOPT_SSL_VERIFYPEER, 0);
curl_easy_setopt(curl, CURLOPT_WRITEDATA, buf);
curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, buffer_writer);
curl_easy_perform(curl);
curl_easy_cleanup(curl);
fp2 = fopen(fname2, "w");
fprintf(fp2, "%s", buf->data);
fclose(fp2);
free(buf->data);
free(buf);
return EXIT_SUCCESS;
}<C言語コンパイル&実行とBeautifulSoup処理の箇所のみ>
proc = subprocess.run("gcc [ソースコード] -I/usr/local/opt/curl/include -lcurl ; ./a.out ; ECHO 'C言語実行完了'", shell=True, stdout= subprocess.PIPE, stderr = subprocess.PIPE)
print(proc.stdout.decode('UTF-8'))
with open(html,encoding='EUC-JP',errors='ignore') as f:
contents= f.read()
soup = BeautifulSoup(contents, "html.parser")前回の続きです。
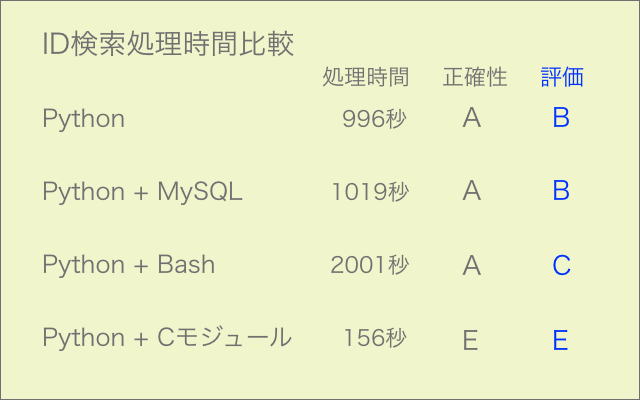
どう考えても検索ヒットした馬名のデータが2行になるのは無駄なので、1行になるよう修正しました。
この修正により処理時間が87秒から80秒に短縮されました。
<修正箇所>
while(fgets(buf,2000, fp ) != NULL ) {
sscanf(buf, " %9s, %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %s",horseID,horse_name,horse_name0,status,gender,hair,birthday,trainer,owner,info,breeder,area,price,prize_money,result,wining_race,relatives ) ;
if (i != 0){
if (strcmp(horse_name,horse_name_in)==0){
fp3 = fopen(fname3, "a");
fprintf(fp3, "%s,%9s\n", horse_name,horseID);
fclose(fp3);
b ++;
break;
}
}
i ++ ;
}
if (b == 0){
fp3 = fopen(fname3, "a");
fprintf(fp3, "%s,100000000\n", horse_name_in);
fclose(fp3);
}前回の続きです。
C言語実行から作成したデータを処理する流れを説明します。
実行ファイルはsubprocessモジュールで走らせて、処理の終了は実行ファイルの最後に仕込んだ標準出力の受け取りで判断します。
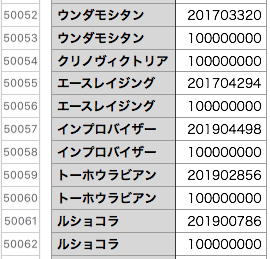
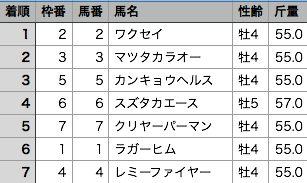
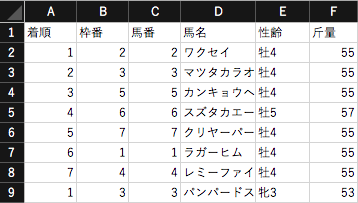
作成されたデータ内容は下図のようになっています。データベースにヒットした馬名は2行になり、ヒットしなかった馬名は1行になります。
あとはpandasなどを使ってデータ加工するのですが、重複行の削除には一工夫必要でした。馬名は複数回登場することがあるのでpandasのduplicatedメソッドは使えず、馬名列要素のリストと1要素分スライドしたリストを比較し重複する所のインデックス番号をリスト化して処理しました。
重たい処理はC言語にさせて、出来上がったラフなデータをPythonで加工する。データベースを扱うに際し私にとって最強の組み合わせになりそうです。
<該当箇所のみ>
# C言語実行ファイル
proc = subprocess.run(C言語実行ファイルのパス, shell=True, stdout= subprocess.PIPE, stderr = subprocess.PIPE)
print(proc.stdout.decode('UTF-8'))
# horseID.csvのデータフレーム化
df = pd.read_csv(horseID_file,names=['馬名2','horseID'],encoding='UTF-8')
# "馬名2"列リストと1要素スライドしたリストを作成(最後の'A'は数合わせ)
list_horseA = df['馬名2'].tolist()
list_horseB = list_horseA[1:] + ['A']
# 重複行のインデックス番号を取得してリスト化
list_num = []
i = 1
for nameA,nameB in zip(list_horseA,list_horseB):
if nameA == nameB:
list_num.append(i)
i = i + 1
# 重複行を削除
df2 = df.drop(df.index[list_num])前回記事で試みたCモジュールの導入は残念ながらうまくいきませんでしたが、次にPythonコードからターミナルコマンドでC言語実行ファイルを走らせてみたところ、こちらの方は難なく成功しました。
Pythonだけで処理するよりも10倍以上の速さです。
ファイルを介してデータのやり取りをするのであれば、この方法で問題ありません。
C言語のコードを書くのは初心者ゆえかなりしんどいものの、その凄まじい実力を知ってしまったら使わずにはいられないです。
#include <stdio.h>
#include <stdlib.h>
int main(void) {
FILE *fp; // 誕生年競走馬リスト
int horseID[9]; // 1 horseID
char horse_name[50]; // 2 検索馬名
char horse_name0[50]; // 3 馬名
char status[10]; // 4 稼働
char gender[10]; // 5 性別
char hair[10]; // 6 毛色
char birthday[50]; // 7 生年月日
char trainer[50]; // 8 調教師
char owner[50]; // 9 馬主
char info[100]; // 10 募集情報
char breeder[50]; // 11 生産者
char area[50]; // 12 産地
char price[50]; // 13 セリ取引価格
char prize_money[50]; // 14 獲得賞金
char result[50]; // 15 通算成績
char winning_race[100]; // 16 主な勝鞍
char relatives[100]; // 17 近親馬
char horse_name_in[50]; // 検索馬名
FILE *fp2; // 入力ファイル
FILE *fp3; // 出力ファイル
char buf[2000]; // fgets用
char buf2[200]; // 検索馬名用
int i=0;
int strcmp(const char *s1, const char *s2);
char fname[100];
char fname2[] = "path_horse.txt"; // 誕生年競走馬リストのパスと競走馬名
char fname3[] = "horseID.csv"; // 検索結果
fp2 = fopen(fname2, "r");
while(fgets(buf2,200, fp2) != NULL ) {
sscanf(buf2,"%[^,],%s",fname,horse_name_in);
fp = fopen(fname, "r");
if(fp == NULL) {
printf("%s file not open!\n", fname);
return -1;
}
while(fgets( buf,2000, fp ) != NULL ) {
sscanf(buf, " %9s, %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %s",horseID,horse_name,horse_name0,status,gender,hair,birthday,trainer,owner,info,breeder,area,price,prize_money,result,winning_race,relatives ) ;
if (i != 0){
if (strcmp(horse_name,horse_name_in)==0){
fp3 = fopen(fname3, "a");
fprintf(fp3, "%s,%9s\n", horse_name,horseID);
fclose(fp3);
break;
}
}
i ++ ;
}
fp3 = fopen(fname3, "a");
// ヒットしなかった馬名には仮番号100000000を付ける
fprintf(fp3, "%s,100000000\n", horse_name_in);
fclose(fp3);
fclose(fp);
}
fclose(fp2);
printf("C言語実行しました");
}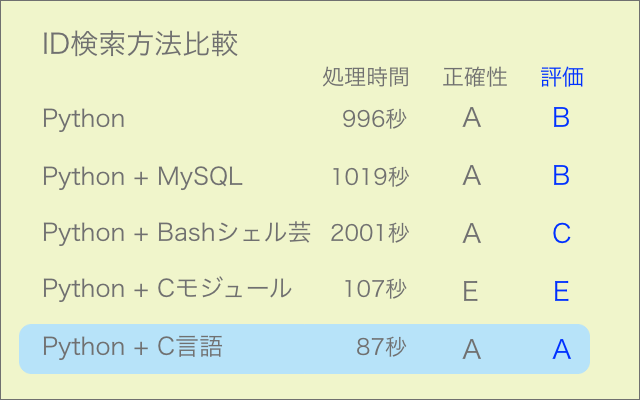
競走馬名からIDを検索する部分をC言語で作成し、Python用にモジュール化して走らせてみました。約25000件の処理になります。
速度は6倍になりましたが、検索漏れのエラーが多発して今のところ使えない状態です(エラー率6%)。
丸1日掛けて過去最高レベルで苦労したにも関わらず、残念な結果となりました。
シェルスクリプトのワンライナーでも試してみましたが、処理は正確なものの時間は2倍掛かりました。やはり大量処理には向かないようです。
馬名を都度Cモジュールに渡して検索する方式から一括渡しのバッチ式に変更してさらに検証を進める予定です。
それでも改善しなければ、観念して全編C言語で作成することになるかもしれません。なるべく回避したいところです。
21/7/12追記 バッチ式で検証したところC言語ではOK、モジュール化するとNGでした。モジュール化の方法に問題があるようです。
#include <stdio.h>
#include <stdlib.h>
int main(void) {
FILE *fp; // horse_listファイル
int horseID[9]; // 1 horseID
char horse_name[50]; // 2 馬名
char horse_name0[50]; // 3 馬名0 (外),(地)等を付加した馬名
char status[10]; // 4 稼働状態
char gender[10]; // 5 性別
char hair[10]; // 6 毛色
char birthday[50]; // 7 生年月日
char trainer[50]; // 8 調教師
char owner[50]; // 9 馬主
char breeder[50]; // 10 生産者
char area[50]; // 11 産地
char price[50]; // 12 セリ取引価格
char prize_money[50]; // 13 獲得賞金
char result[50]; // 14 通算成績
char winning_race[100]; // 15 主な勝鞍
char horse_name_in[50]; // 検索馬名
FILE *fp2; // 入出力用一時ファイル
char buf[600]; // fgets用
char buf2[100]; // 検索馬名用
int ret;
int i=0;
int strcmp(const char *s1, const char *s2);
char fname[100];
char fname2[] = "horseID.txt";
fp2 = fopen(fname2, "r");
while(fgets(buf2,100, fp2) != NULL ) {
sscanf(buf2,"%[^,],%s",fname,horse_name_in);
printf("%s,%s\n",fname,horse_name_in);
fclose(fp2);
}
fp = fopen(fname, "r");
if(fp == NULL) {
printf("%s file not open!\n", fname);
return -1;
}
while( fgets( buf,600, fp ) != NULL ) {
ret = sscanf(buf, " %9s, %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %s",horseID,horse_name,horse_name0,status,gender,hair,birthday,trainer,owner,breeder,area,price,prize_money,result,winning_race ) ;
if (i != 0){
if (strcmp(horse_name,horse_name_in)==0){
fp2 = fopen(fname2, "w");
fprintf(fp2, "%9s\n", horseID);
fclose(fp2);
}
}
i ++ ;
}
fclose(fp);
}
メモ書き。
print(df.iat[2, 1])
# 代入も可能
df.iat[1, 0] = 50ささいなことでハマったのでメモ書きしておきます。
コードにprint関数による標準出力が含まれているにもかかわらず引数に–noconsoleを付けたために、作成したアプリが起動しませんでした。
アプリが標準出力したいのにコンソールが立ち上がらないのでは当然エラーになります。
標準出力の箇所は削除し、以下コマンドで再度作成しました。
pyinstaller pythonファイル名 --onefile --noconsoleCSVファイルのデータ型を小数の文字列から整数に変換するコードの一例です。画像上・中は表計算ソフトNumbersで変換前後をファイル表示したものです。
小数の文字列から整数への直接変換は仕様のため不可なので、一旦浮動小数点数に変換してから整数にします。
<コードの一部>
with open (file, mode="r", encoding="shift_jis") as f1:
with open(file_convert, mode="a", encoding="shift_jis") as f2:
writer = csv.writer(f2)
for i,row in enumerate(csv.reader(f1)):
if i == 0: # ヘッダ行
rows = row[0:23]
writer.writerow(rows)
else:
try: # 着順 "中(止)"や"除(外)"への対応
col0 = int(float(row[0]))
except:
col0 = row[0]
try: # 人気 空欄への対応
col13 = int(float(row[13]))
except:
col13 = row[13]
rows2 = [col0] + [int(float(row[1]))] + [int(float(row[2]))] + row[3:13] + [col13] + row[14:23]
writer.writerow(rows2)
Excelでは変換前後で見た目変わらず。この種の作業には全く向きません。Numbersの優秀さが際立ちます。
[macOS Catalina 10.15.7]
pyenvでpipを使ったMySQLモジュールのインストールコマンド例は以下のようになります。
モジュール名がmysqlではなくてmysql-connector-pythonなので注意が必要です。
Python 3.9.X毎にライブラリを管理する場合
(pythonコマンドをマイクロバージョン毎に変える必要がある)
/Users/xxx/.pyenv/versions/3.9.5/bin/python -m pip install mysql-connector-python
<インストール先>
/Users/xxx/.pyenv/versions/3.9.5/lib/python3.9/site-packagesPython 3.9でまとめて管理する場合
(1.which python → /Users/xxx/.pyenv/shims/python
2.python –version → Python3.9.X を事前確認する)
python -m pip install mysql-connector-python
<インストール先>
/Users/xxx/.local/lib/python3.9/site-packages