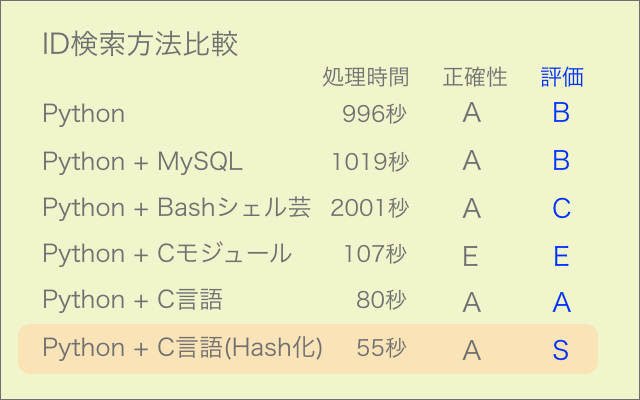
一定の頻度で必要になりそうなので書いておきます。
import csv
print("開始年度を入力してください")
start_year = input()
print("終了年度を入力してください")
end_year = input()
for year in range(int(start_year),int(end_year)+1):
file = f'{year}.csv'
file_new= f'{year}_new.csv'
with open (file, mode="r", encoding="UTF-8") as f1:
with open(file_new, mode="w", encoding="UTF-8") as f2:
writer = csv.writer(f2)
for row in csv.reader(f1):
rows = []
for i in range(0,len(row)):
rows.append(row[i].replace('\n',''))
writer.writerow(rows)