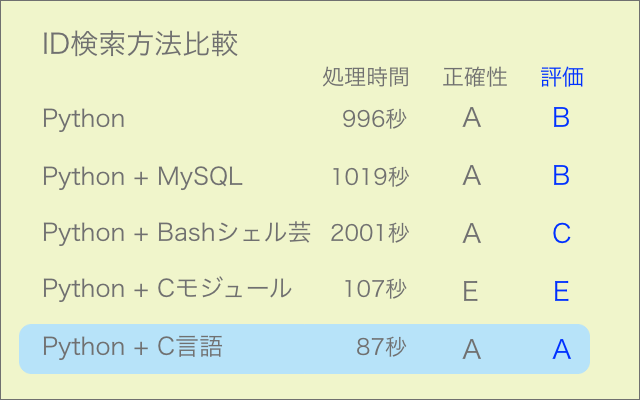
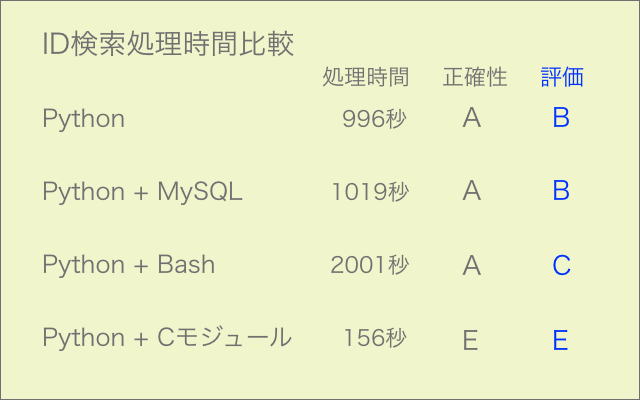
前回記事で試みたCモジュールの導入は残念ながらうまくいきませんでしたが、次にPythonコードからターミナルコマンドでC言語実行ファイルを走らせてみたところ、こちらの方は難なく成功しました。
Pythonだけで処理するよりも10倍以上の速さです。
ファイルを介してデータのやり取りをするのであれば、この方法で問題ありません。
C言語のコードを書くのは初心者ゆえかなりしんどいものの、その凄まじい実力を知ってしまったら使わずにはいられないです。
#include <stdio.h>
#include <stdlib.h>
int main(void) {
FILE *fp; // 誕生年競走馬リスト
int horseID[9]; // 1 horseID
char horse_name[50]; // 2 検索馬名
char horse_name0[50]; // 3 馬名
char status[10]; // 4 稼働
char gender[10]; // 5 性別
char hair[10]; // 6 毛色
char birthday[50]; // 7 生年月日
char trainer[50]; // 8 調教師
char owner[50]; // 9 馬主
char info[100]; // 10 募集情報
char breeder[50]; // 11 生産者
char area[50]; // 12 産地
char price[50]; // 13 セリ取引価格
char prize_money[50]; // 14 獲得賞金
char result[50]; // 15 通算成績
char winning_race[100]; // 16 主な勝鞍
char relatives[100]; // 17 近親馬
char horse_name_in[50]; // 検索馬名
FILE *fp2; // 入力ファイル
FILE *fp3; // 出力ファイル
char buf[2000]; // fgets用
char buf2[200]; // 検索馬名用
int i=0;
int strcmp(const char *s1, const char *s2);
char fname[100];
char fname2[] = "path_horse.txt"; // 誕生年競走馬リストのパスと競走馬名
char fname3[] = "horseID.csv"; // 検索結果
fp2 = fopen(fname2, "r");
while(fgets(buf2,200, fp2) != NULL ) {
sscanf(buf2,"%[^,],%s",fname,horse_name_in);
fp = fopen(fname, "r");
if(fp == NULL) {
printf("%s file not open!\n", fname);
return -1;
}
while(fgets( buf,2000, fp ) != NULL ) {
sscanf(buf, " %9s, %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %s",horseID,horse_name,horse_name0,status,gender,hair,birthday,trainer,owner,info,breeder,area,price,prize_money,result,winning_race,relatives ) ;
if (i != 0){
if (strcmp(horse_name,horse_name_in)==0){
fp3 = fopen(fname3, "a");
fprintf(fp3, "%s,%9s\n", horse_name,horseID);
fclose(fp3);
break;
}
}
i ++ ;
}
fp3 = fopen(fname3, "a");
// ヒットしなかった馬名には仮番号100000000を付ける
fprintf(fp3, "%s,100000000\n", horse_name_in);
fclose(fp3);
fclose(fp);
}
fclose(fp2);
printf("C言語実行しました");
}