とっくに記事にしていると思い込んでました。
今後も重宝するでしょう。
import pandas as pd
filename = 'horse.csv'
filename_new = 'horse_new.csv'
df = pd.read_csv(filename,encoding='shift_JIS')
with open(filename_new,mode = 'w',encoding='UTF-8') as f:
df.to_csv(f,index=False)とっくに記事にしていると思い込んでました。
今後も重宝するでしょう。
import pandas as pd
filename = 'horse.csv'
filename_new = 'horse_new.csv'
df = pd.read_csv(filename,encoding='shift_JIS')
with open(filename_new,mode = 'w',encoding='UTF-8') as f:
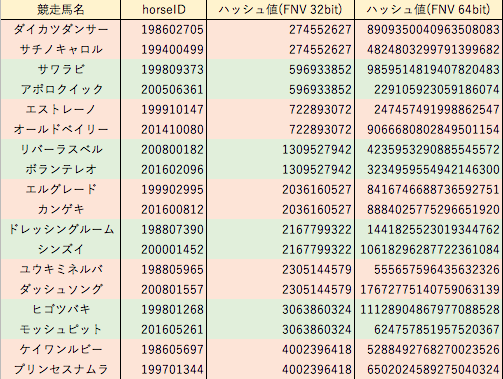
df.to_csv(f,index=False)ハッシュ関数fnvの32bitで競走馬名ハッシュ値の衝突が生じたため、64bitハッシュ値での検索処理時間を計測してみました。
やはり32bitの55秒に対し77秒と遅くなりました。
ハッシュ値検索にこだわるならばFNVでは32bitで運用するしかないですが、同一誕生年内での衝突はないので私の使い方では今のところトラブルになることはありません。
ところで、Excelで表をまとめていて64bit以上の整数を正確に表示できない問題に遭遇しました。仕方ないので文字列扱いにして解決しました。
他にも小数点数と整数の区別ができない、UTF-8のCSVファイルが基本文字化けする、数字とハイフンがあると勝手に日付と解釈する、など何かとプログラマ泣かせのソフトです。
macOSのNumbersでは64bit整数でも問題なく表示できます。今はなきLotus1-2-3はどうだったのか少し気になります。
情報科学においてunsigned long long integerを”符号なし長長整数”などといった日本語に翻訳していないのが不思議です。
ハッシュ関数FNVの32bitで数件衝突が発生したため、64bitでも生成できるようにしました。
PythonのドキュメントにPy_BuildValueの引数について解説があり、unsigned long long intのフォーマットがKであることが分かりました。
unsigned intのフォーマットはiではなく大文字のIなので、32bitの方も修正しました。これでPython側での変換が不要になります。
#define PY_SSIZE_T_CLEAN
#include <Python.h>
extern uint32_t fnv_1_hash_32(const char*);
extern uint64_t fnv_1_hash_64(const char*);
static PyObject* fnv_32(PyObject* self, PyObject* args)
{
const char* s;
unsigned int hash=2166136261U;
if (!PyArg_ParseTuple(args, "s", &s)){
return NULL;
}
else{
while (*s) {
hash*=16777619U;
hash^=*(s++);
}
return Py_BuildValue("I", hash);
}
}
static PyObject* fnv_64(PyObject* self, PyObject* args)
{
const char* s;
unsigned long long hash=14695981039346656037U;
if (!PyArg_ParseTuple(args, "s", &s)){
return NULL;
}
else{
while (*s) {
hash*=1099511628211LLU;
hash^=*(s++);
}
return Py_BuildValue("K", hash);
}
}
static PyMethodDef fnvmethods[] = {
{"fnv_1_hash_32", fnv_32, METH_VARARGS},
{"fnv_1_hash_64", fnv_64, METH_VARARGS},
{NULL,NULL,0}
};
static struct PyModuleDef fnv = {
PyModuleDef_HEAD_INIT,
"fnv",
"Python3 C API Module(Sample 1)",
-1,
fnvmethods
};
PyMODINIT_FUNC PyInit_fnv(void)
{
return PyModule_Create(&fnv);
}from c_module import fnv
name_list = ['シャフリヤール']
for name in name_list:
hash = fnv.fnv_1_hash_64(name)
print(hash)
--------------------------------------------------
出力
--------------------------------------------------
7203286604922561048#include <stdio.h>
#include <stdint.h>
uint32_t fnv_1_hash_32(char *s)
{
unsigned int hash=2166136261U;
while (*s) {
hash*=16777619U;
hash^=*(s++);
}
return hash;
}
uint64_t fnv_1_hash_64(char *s)
{
unsigned long long hash=14695981039346656037U;
while (*s) {
hash*=1099511628211LLU;
hash^=*(s++);
}
return hash;
}from distutils.core import setup, Extension
setup(name='fnv',
version='1.0',
ext_modules=[Extension('fnv', sources = ['fnv.c','fnv_function.c'])]
)<セットアップコマンド>
・自作ライブラリに配置するsoファイルを作成するコマンド "from c_module import fnv"
python setup.py build_ext -i
・既存のライブラリにインストールするコマンド "import fnv"
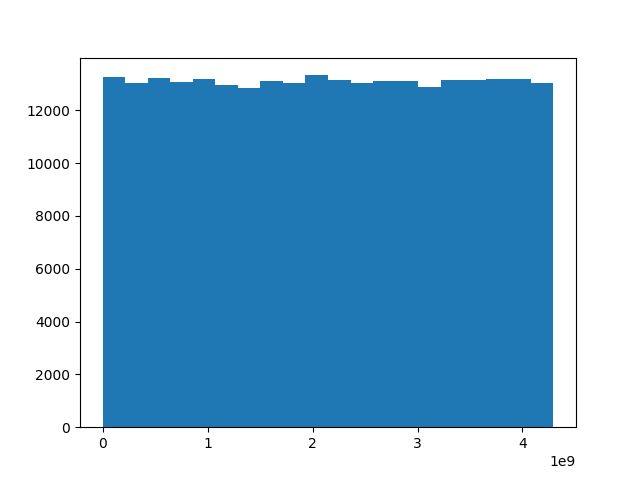
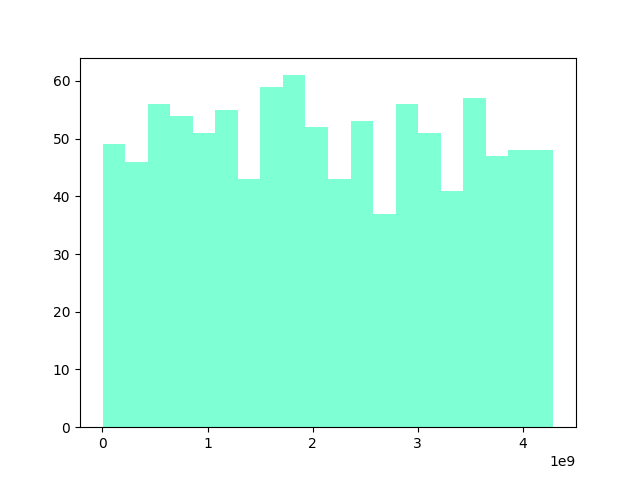
python setup.py installFNV-1により生成されたハッシュ値のばらつきをヒストグラムで確認しました。ハッシュ値は自製のC言語モジュールで生成しました。
上のグラフが1986年以降に生まれた競走馬26.2万頭の馬名ハッシュ値、下のグラフが馬名にシルクが含まれる1000頭のハッシュ値をヒストグラムにしたものです。
満遍なくハッシュ値が生成されており、冠名による偏りもほとんど見られませんでした。
ハッシュ値の重複については調査中です。重複があれば他のハッシュ関数を検討します。
import matplotlib.pyplot as plt
import datetime
import pandas as pd
df = pd.read_csv("name_hash.csv",encoding='UTF-8')
df2 = df[df['馬名'].str.contains('シルク',na=False)]
list = df2['horse_hash'].tolist()
datetime_now = datetime.datetime.now()
datetime_now_str = datetime_now.strftime('%y%m%d%H%M')
plt.hist(list, bins=20,color=['#7fffd4'])
plt.savefig(f"{datetime_now_str}_hist_silk.png")一定の頻度で必要になりそうなので書いておきます。
import csv
print("開始年度を入力してください")
start_year = input()
print("終了年度を入力してください")
end_year = input()
for year in range(int(start_year),int(end_year)+1):
file = f'{year}.csv'
file_new= f'{year}_new.csv'
with open (file, mode="r", encoding="UTF-8") as f1:
with open(file_new, mode="w", encoding="UTF-8") as f2:
writer = csv.writer(f2)
for row in csv.reader(f1):
rows = []
for i in range(0,len(row)):
rows.append(row[i].replace('\n',''))
writer.writerow(rows)Pythonでもハッシュ関数FNVを使えるようにするためC言語モジュール化しました。
モジュールからの戻り値は整数の範囲でしか使えず、32ビットのunsigned intには対応できましたが、64ビットではうまくいきませんでした。
初めはPythonからポインタをどうやって渡すのか見当もつかなくて、戻り値の受け取り方もかなり試行錯誤しました。
これでC言語とPythonで同一文字列から同じハッシュ値を作成できるので色々使い道がありそうです。
2021/7/25追記:コードを改良して以下の記事にアップしています。
#define PY_SSIZE_T_CLEAN
#include <Python.h>
extern uint32_t fnv_1_hash_32(const char*);
static PyObject* fnv_32(PyObject* self, PyObject* args)
{
const char* s;
unsigned int hash=2166136261U;
if (!PyArg_ParseTuple(args, "s", &s)){
return NULL;
}
else{
while (*s) {
hash*=16777619U;
hash^=*(s++);
}
return Py_BuildValue("i", hash);
}
}
static PyMethodDef fnvmethods[] = {
{"fnv_1_hash_32", fnv_32, METH_VARARGS},
{NULL,NULL,0}
};
static struct PyModuleDef fnv = {
PyModuleDef_HEAD_INIT,
"fnv",
"Python3 C API Module(Sample 1)",
-1,
fnvmethods
};
PyMODINIT_FUNC PyInit_fnv(void)
{
return PyModule_Create(&fnv);
}from c_module import fnv
name = 'シャフリヤール'
hash = fnv.fnv_1_hash_32(name)
# int から unsigned int 32bitへ変換
hash_unsigned32 = hash & 0xffffffff
print(hash_unsigned32)
--------------------------------------------------
出力
--------------------------------------------------
3687658616#include <stdio.h>
#include <stdint.h>
uint32_t fnv_1_hash_32(char *s)
{
unsigned int hash=2166136261U;
while (*s) {
hash*=16777619U;
hash^=*(s++);
}
return hash;
}from distutils.core import setup, Extension
setup(name='fnv',
version='1.0',
ext_modules=[Extension('fnv', sources = ['fnv.c','fnv_1.c'])]
)<セットアップコマンド>
・自作ライブラリに配置するsoファイルを作成するコマンド "from c_module import fnv"
python setup.py build_ext -i
・既存のライブラリにインストールするコマンド "import fnv"
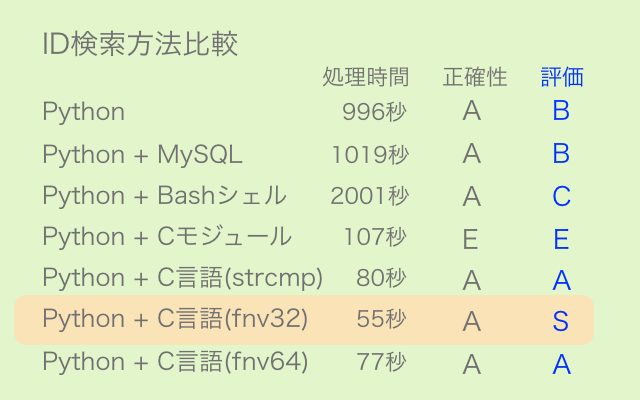
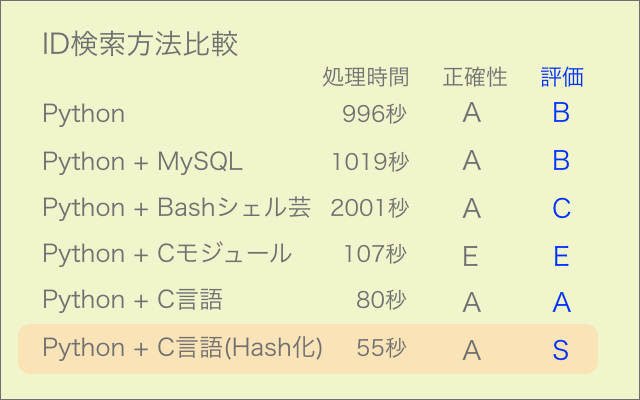
python setup.py installこれまでC言語を学習してきて、この言語は文字列の取り扱いが不得手というのがよく分かりました。そのような仕様でもstrcmp関数は1文字づつの比較しかできないながら相当速くなっていると思います。
さらなる高速化を検討した結果、文字列を数字に変換して加減計算等できるようにすれば処理が速くなるのではと考え、ハッシュ関数によるハッシュ化を試してみました。
データベースに馬名のハッシュ値を格納し検索に用いたところ、24000件の処理を80秒から55秒に短縮しました。
sscanf関数が扱いづらくatoi関数の必要性にもなかなか気がつかなかったため、かなり難航しました。
今回は比較する文字列の片方を前もってハッシュ化しましたが、両方処理していたらさらに速くなるはずです。
<修正箇所>
uint32_t horse_hash_int;
while(fgets(buf,2000,fp ) != NULL ) {
if (i != 0){
ret = sscanf(buf, " %[^,],%[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %[^,], %s",horseID,horse_hash,horse_name,horse_name0,status,gender,hair,birthday,trainer,owner,info,breeder,area,price,prize_money,result,wining_race,relatives) ;
horse_hash_int = atoi(horse_hash);
if(horse_hash_int - fnv_1_hash_32(horse_name_in) == 0){
fp3 = fopen(fname3, "a");
fprintf(fp3," %s,%9s\n",horse_name_in,horseID);
fclose(fp3);
b ++;
break;
}
}
i ++ ;
}
FNVをPythonでも使えるようにするため、まずは外部関数化しました。
64バイトハッシュ値のフォーマット指定子は%luです。
#include <stdio.h>
#include <stdint.h>
uint32_t fnv_1_hash_32(char *s)
{
unsigned int hash=2166136261U;
while (*s) {
hash*=16777619U;
hash^=*(s++);
}
return hash;
}
uint64_t fnv_1_hash_64(char *s)
{
long unsigned int hash=14695981039346656037U;
while (*s) {
hash*=1099511628211LLU;
hash^=*(s++);
}
return hash;
}#include <stdio.h>
#include <stdint.h>
#include "fnv_1.c"
int main(void)
{
char *s = "シャフリヤール";
printf("%u\n",fnv_1_hash_32(s));
printf("%lu\n",fnv_1_hash_64(s));
}
--------------------------------------------------
出力
--------------------------------------------------
3687658616
7203286604922561048[Python] 283の記事あたりまで取り組んでいたデータベース検索の高速化ですが、文字列比較ではなくハッシュ値比較でも試してみました。
ハッシュ関数によるハッシュ値算出の時間が余計に掛かっているものの、これまでの最速記録80秒に対して84秒となかなかの健闘でした。正確性も問題ありません。
その他では機械語変換手前のアセンブリ言語コードをチェックしたりもしましたが初級者にいじれるはずもなく、また最近の文字列比較機能(strcmpなど)は優秀のようで小手先の自作関数では歯が立ちませんでした。
ハッシュ関数についてはスキルアップのための余興みたいなもので、ここらで高速化検討は打ち切りにするつもりです。
#include <stdio.h>
#include <stdint.h>
uint32_t fnv_1_hash_32(char *s)
{
unsigned int hash=2166136261UL;
while (*s) {
hash*=16777619UL;
hash^=*(s++);
}
return hash;
}<該当箇所のみ>
#include "fnv_1.c"
if (i != 0){
if (fnv_1_hash_32(horse_name) - fnv_1_hash_32(horse_name_in) == 0){
fp3 = fopen(fname3, "a");
fprintf(fp3,"%s,%9s\n",horse_name_in,horseID);
fclose(fp3);
b ++;
break;
}
}色々検証してきましたが、htmlのダウンロードについてはRequestsやseleniumを知らなくてもcurlコマンド1つでできるようです。あとはBeautifulSoupで解析すればOKです。
処理時間は私の検証条件ではhtml解析を経てcsv作成まで1件あたり0.23sでした。Requestsやlibcurlが0.35sなのでcurlコマンドが最速になります。
コードも簡潔になりますし、htmlをダウンロードする場合は馴染みのあるRequestsではなくcurlコマンドを採用します。
ただし、これまでと同様ループする場合はtime.sleep等で速度を制御しないとスクレイピング先に迷惑がかかるので要注意です。
ダウンロードせずにhtml解析&テキスト取り出しであれば、これまで通りRequestsになります。
<該当箇所のみ>
proc = subprocess.run("curl 'スクレイピング先のurl' > [出力先ファイル] ; echo '出力完了'", shell=True, stdout= subprocess.PIPE, stderr = subprocess.PIPE)
print(proc.stdout.decode('UTF-8'))
with open(出力先ファイル,encoding='EUC-JP',errors='ignore') as f:
contents= f.read()
soup = BeautifulSoup(contents, "html.parser")