[M1 Mac, Ventura 13.3.1, Xcode 14.3]
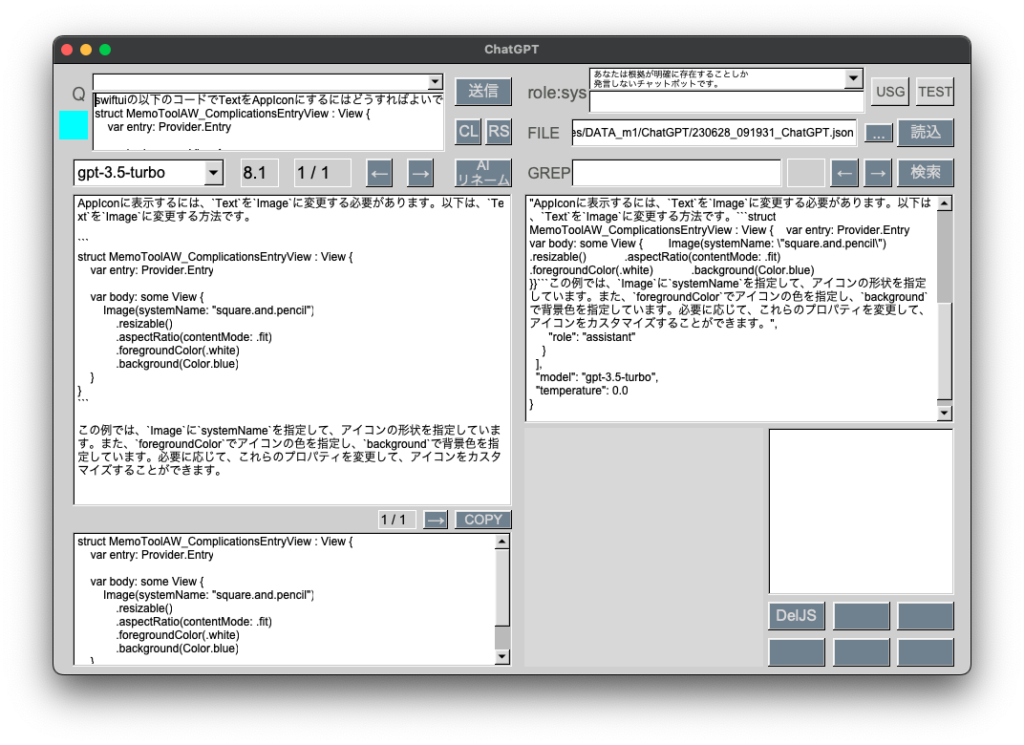
GPT-3.5のAPIとやりとりできるようになりました。
ChatGPTの力を借り色々試行錯誤しながらで約半日掛かりました。取りあえず送受信を1往復できるようにしています。
チャットのように交互に表示させるのは難しいため、上下段に振り分けました。
次回以降、複数回の送受信に対応させます。
OpenAIがiOS, iPadOSアプリを5/26にリリースしているので、比較しながら機能を増やしていきたいです。
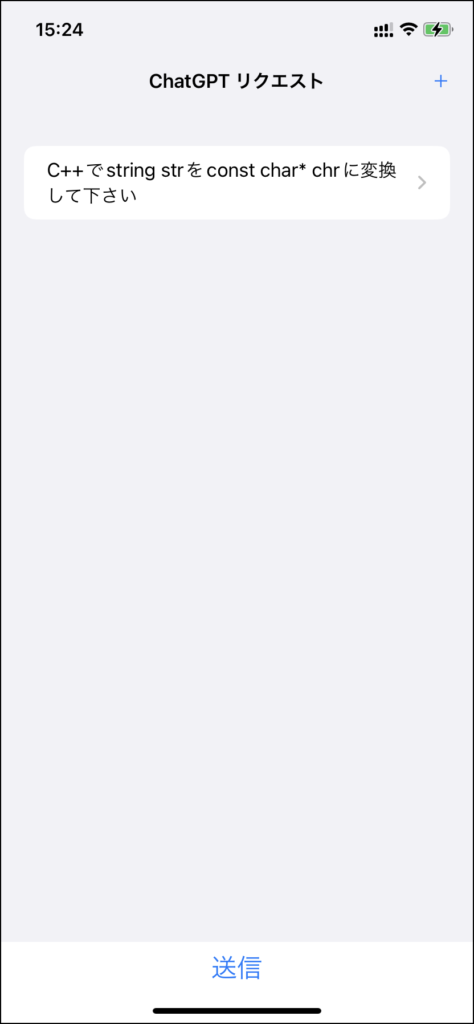
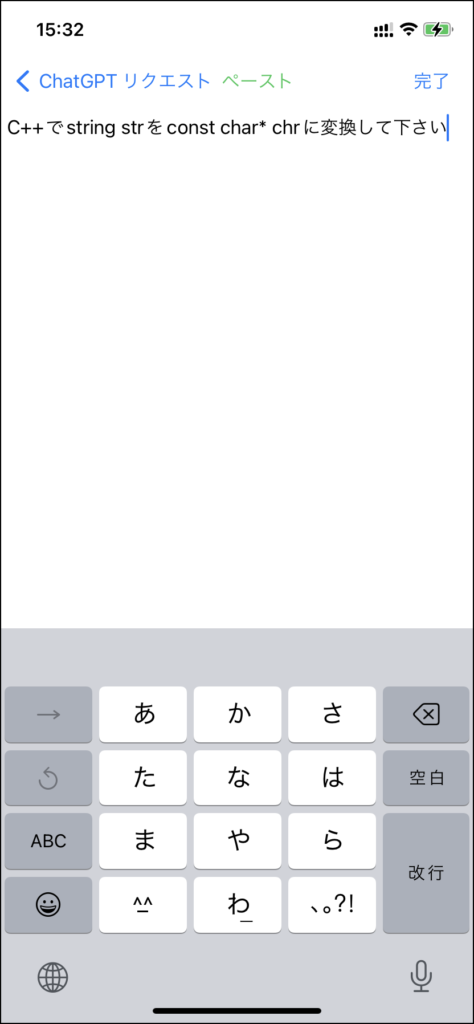
 iOS版
iOS版
 iPadOS版
iPadOS版
import SwiftUI
import CoreData
struct ContentView: View {
@Environment(\.managedObjectContext) private var viewContext
@FetchRequest(sortDescriptors:[])
private var pairs: FetchedResults<Interaction>
var body: some View {
NavigationView {
VStack{
List {
ForEach(pairs) { pair in
NavigationLink{
if((pair.instruction?.isEmpty) == false){
Draft(text:pair.instruction!, interaction: pair)
}
}
label:{
if((pair.instruction?.isEmpty) == false){
Text(pair.instruction!)
}
}
}
.onDelete(perform: deleteInteraction)
}
.navigationTitle("ChatGPT リクエスト")
.navigationBarTitleDisplayMode(.inline)
.toolbar{
// 新規リクエスト作成
ToolbarItem(placement:.navigationBarTrailing){
NavigationLink{
Draft()
}label:{
Text("+")
}
}
}
List {
ForEach(pairs, id: \.self) { pair in
if let res = pair.res, !res.isEmpty {
Text(res)
.foregroundColor(.white)
.background(Color.blue)
}
}
.onDelete(perform: deleteInteraction)
}
Button(action:{
if pairs.last != nil{
sendRequest()
}else{
print("pairsは空です")
}
}){
Text("送信")
.font(.system(size: 24))
}
}
}
}
func deleteInteraction(offsets:IndexSet){
for offset in offsets{
viewContext.delete(pairs[offset])
}
do{
try viewContext.save()
}catch{
fatalError("セーブに失敗")
}
}
func sendRequest(){
let urlAPI = "https://api.openai.com/v1/chat/completions";
let apiKey = "API key";
let model = "gpt-3.5-turbo"
let systemStr: String = "あなたは根拠が明確に存在することのみ発言するチャットボットです。"
let authHeader = "Bearer \(apiKey)"
var headers = [String: String]()
headers["Authorization"] = authHeader
headers["Content-Type"] = "application/json"
guard let url = URL(string: urlAPI) else {
fatalError("Invalid URL")
}
var request = URLRequest(url: url)
request.httpMethod = "POST"
request.allHTTPHeaderFields = headers
// requestData作成・送受信
if let lastInteraction = pairs.last {
if let instruction:String? = lastInteraction.instruction {
print("instruction:")
print(instruction)
let requestData:String = "{\"model\":\"\(model)\", \"messages\":[{\"role\":\"system\",\"content\":\"\(systemStr)\"},{\"role\":\"user\",\"content\":\"\(instruction!)\"}], \"temperature\":0.0}";
print(requestData)
var responseData: [String: Any] = [:]
responseData = sendHTTPRequest(url: url, headers: headers, requestData: requestData)
print(responseData)
if let choices = responseData["choices"] as? [[String: Any]],
let message = choices.first?["message"] as? [String: Any],
var content = message["content"] as? String {
print(content)
lastInteraction.res = content
}
} else {
print("instruction is nil")
return
}
} else {
print("pairs is empty")
return
}
}
func sendHTTPRequest(url: URL, headers: [String: String], requestData: String) -> [String: Any] {
var responseData: [String: Any] = [:]
var timeoutBool = false
let semaphore = DispatchSemaphore(value: 0)
var request = URLRequest(url: url)
request.httpMethod = "POST"
request.allHTTPHeaderFields = headers
request.httpBody = requestData.data(using: .utf8) // requestDataをData型に変換
let task = URLSession.shared.dataTask(with: request) { (data, response, error) in
if let error = error {
timeoutBool = true
print("HTTP request failed: \(error)")
return
}
if let data = data {
do {
responseData = try JSONSerialization.jsonObject(with: data, options: []) as? [String: Any] ?? [:]
} catch {
print("Failed to parse response data: \(error)")
}
}
semaphore.signal()
}
task.resume()
_ = semaphore.wait(timeout: DispatchTime.now() + 90)
if timeoutBool {
<中略>
return [:]
}
return responseData
}
}
struct ContentView_Previews: PreviewProvider {
static var previews: some View {
ContentView()
}
}
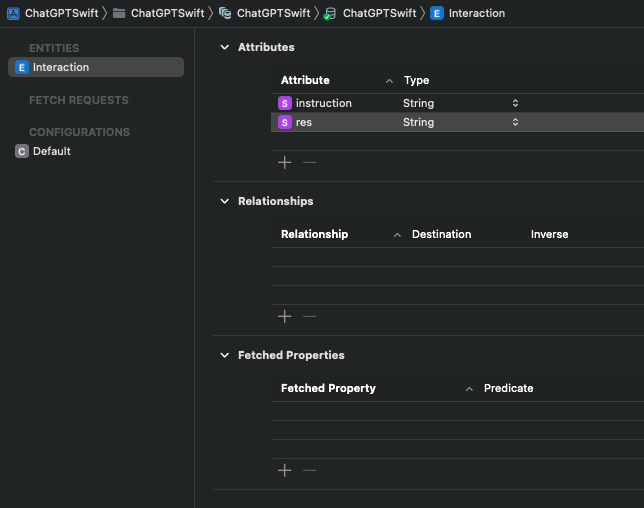 Core Data(Data Model)の内容
Core Data(Data Model)の内容