[Mac M2 Pro 12CPU, Sonoma 14.3.1, clang++ 15.0.0]
実行方法:llama.cpp
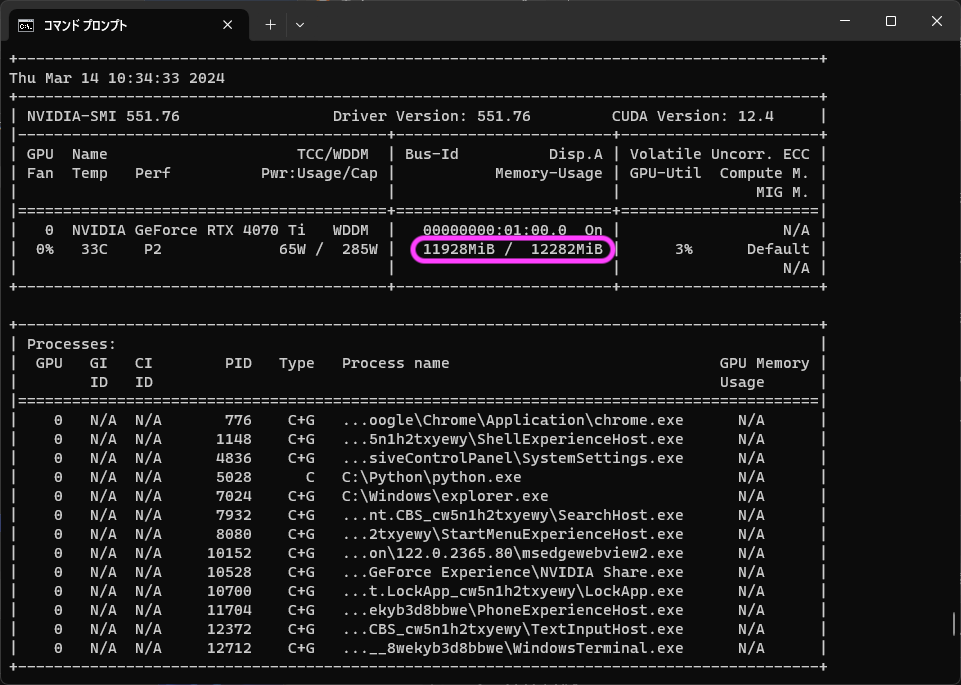
記事その1ではWindows11PCで検証しましたが、GGUF形式であればMacでも動作可能なので早速試してみました。Metalを使用しています。
4bit量子化したGGUF形式のモデルはサイズが4.08GBですから、RAM16GBでも問題なさそうです。
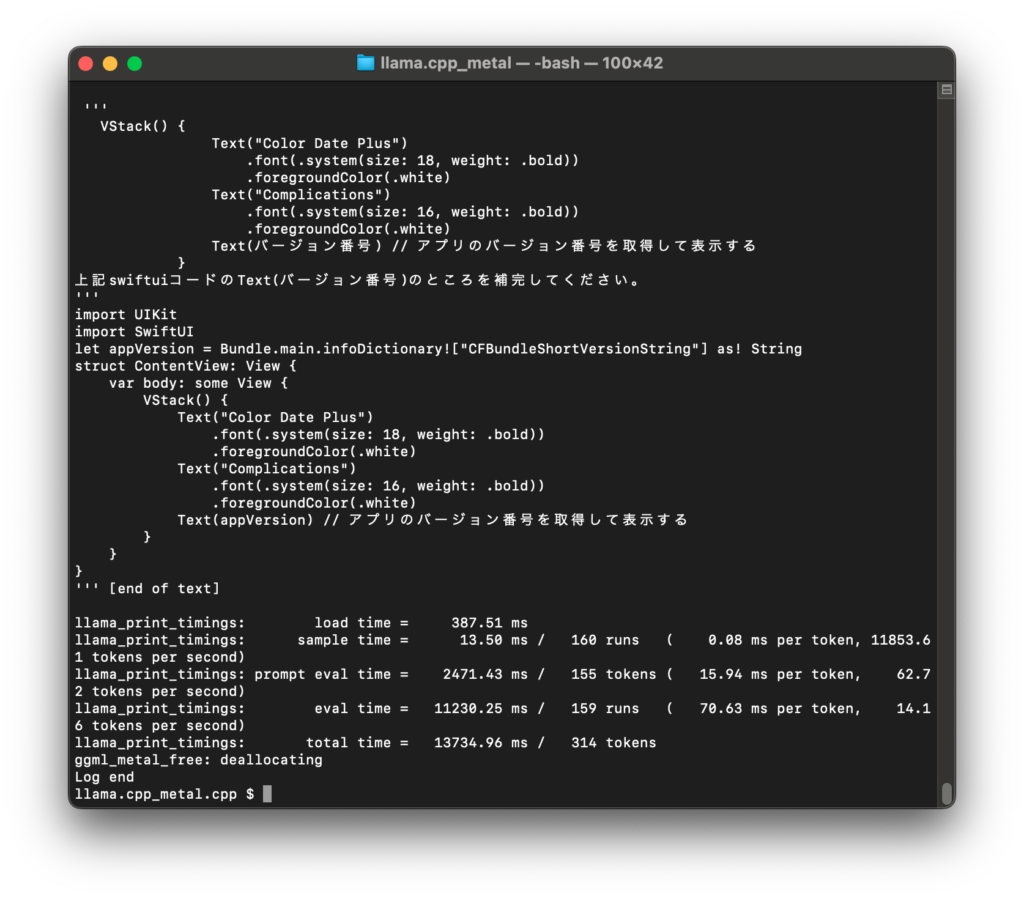
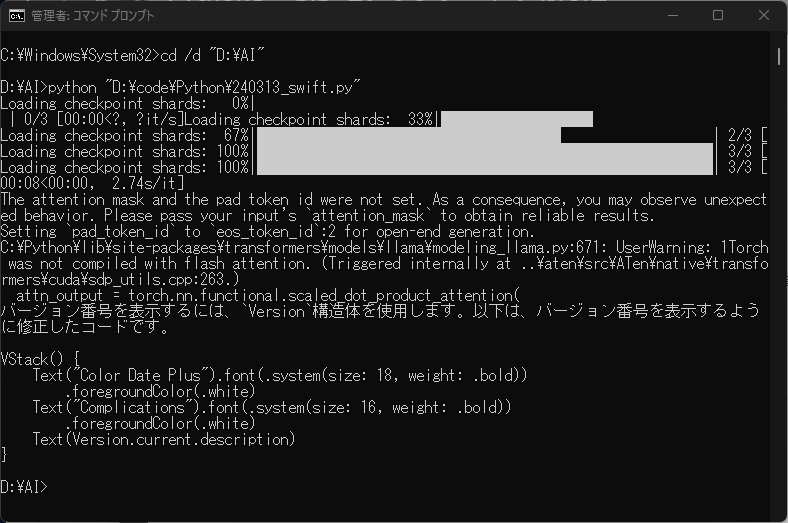
質問によっては無回答で終了することもあるものの、それなりに考えたプロンプトであればSwiftUIの簡単なコードについては正しい答えが返ってきました。
ただし量子化の影響なのか、下図のような簡潔な正答になることもあれば、勝手にチャットのようになったり、誤答を返すことも多く、結構不安定です。
量子化していないGGUF形式のモデルで検証したいところです。
./main -m models/ELYZA-japanese-CodeLlama-7b-instruct-q4_K_M.gguf --temp 1.0 -ngl 1 -t 10 -f ./prompt_jp.txt