[M1 Mac, Ventura 13.3.1, Python 3.10.4]
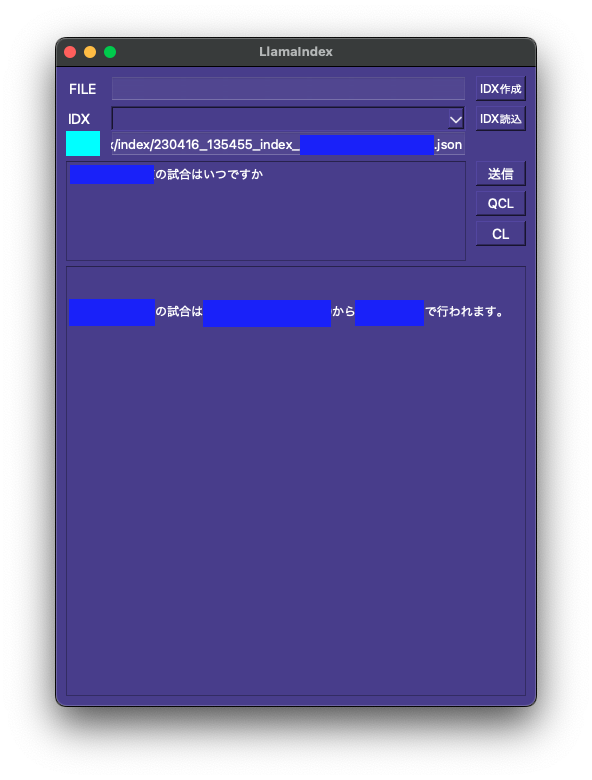
表題の2方法について、PDFを読み込ませた上で質問に対して正確に答えられるかどうか評価しました。
結果はLlamaIndexの圧勝でした。LangChain(Chroma)ではPDFにあるはずのデータを存在しないと返してきました。これでは話になりません。
LangChain(Chroma)では有力なベクトルDBであるChromaを使っていますが、苦手な処理だったのか正確性ではLlamaIndexとは比較になりませんでした。要約力であればまた結果が違ってくるのかもしれません。
import os
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.text_splitter import CharacterTextSplitter
from langchain.chat_models import ChatOpenAI
from langchain.chains import ConversationalRetrievalChain
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("試合日程表.pdf")
pages = loader.load_and_split()
# print(pages[1].page_content)
apiKey = os.getenv("CHATGPT_API_KEY")
os.environ["OPENAI_API_KEY"] = apiKey
llm = ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo")
embeddings = OpenAIEmbeddings()
vectorstore = Chroma.from_documents(pages, embedding=embeddings, persist_directory=".")
vectorstore.persist()
pdf_qa = ConversationalRetrievalChain.from_llm(llm, vectorstore.as_retriever(), return_source_documents=True)
query = "XXXの試合はいつですか"
chat_history = []
result = pdf_qa({"question": query, "chat_history": chat_history})
print(result['answer'])