[M1 Mac, Ventura 13.3.1, Python 3.10.4, PyTorch 2.0.0]
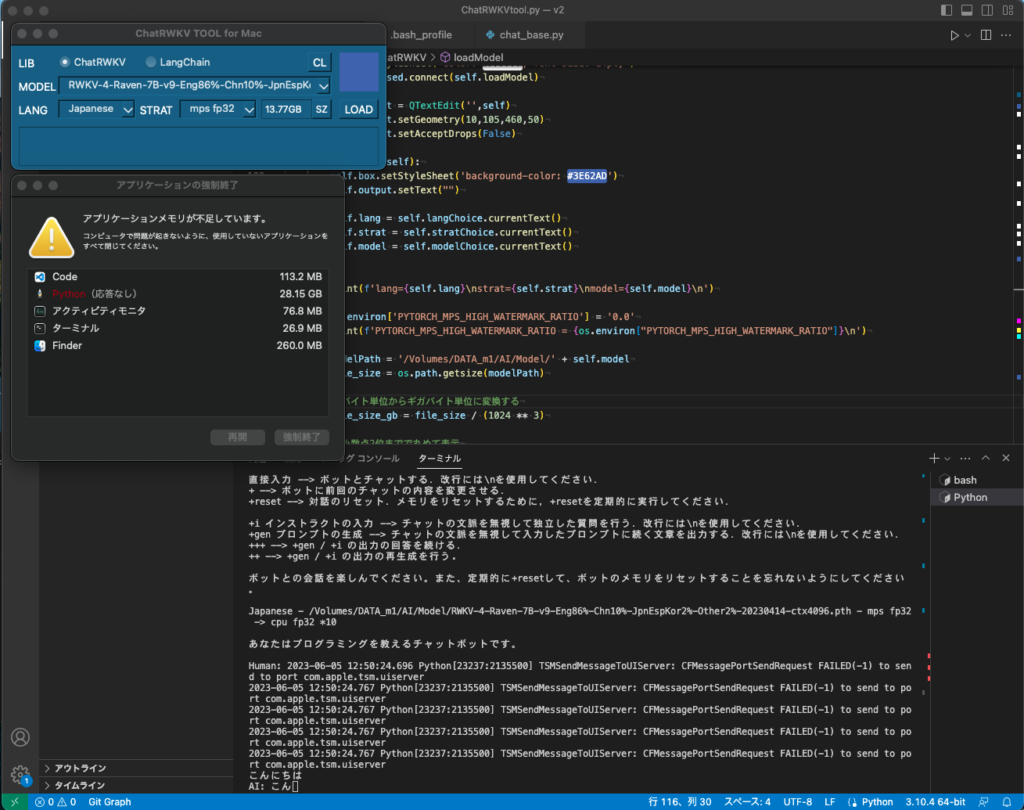
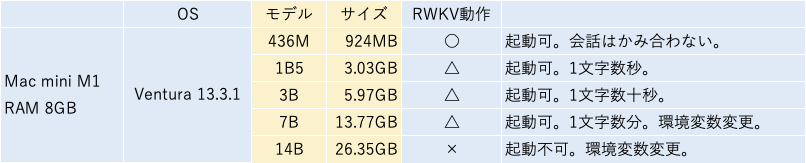
ChatRWKVの設定により7Bサイズのモデルを読み込めるようになりました。
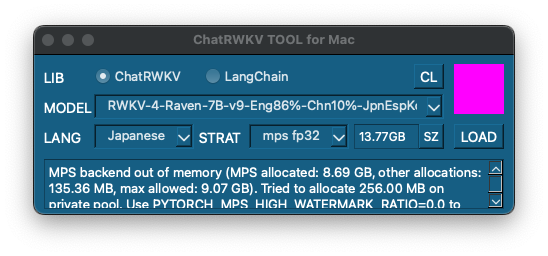
環境変数 PYTORCH_MPS_HIGH_WATERMARK_RATIOをゼロに設定しメモリ使用の上限を撤廃することで読込が可能になります。ただしシステムが不安定になる可能性があるため要注意です。
動作はかなり遅く実用にはほど遠いですが、RAMメモリ強化でどこまで速くなるのか興味深いです。
ところでAppleのイベントWWDCが今晩開催されますが(日本時間6/6 午前2時)、AIについてどのような発信があるのか楽しみです。
またグランフロント大阪にApple Storeを出店する計画があるとか。実現したらヨドバシ梅田と同様に売り上げ日本一になるのでは。
import os
# PyTorch環境変数設定
os.environ['PYTORCH_MPS_HIGH_WATERMARK_RATIO'] = '0.0'
print(f'PYTORCH_MPS_HIGH_WATERMARK_RATIO = {os.environ["PYTORCH_MPS_HIGH_WATERMARK_RATIO"]}\n')self.stratChoice = QComboBox(self)
self.stratChoice.setGeometry(215,70,100,25)
self.stratChoice.addItem('mps fp32 -> cpu fp32 *10')
self.stratChoice.addItem('mps fp32')
self.stratChoice.addItem('cpu fp32')
self.stratChoice.addItem('cuda fp16')