[M1 Mac, Monterey 12.6.3, Python 3.10.4]
以前LangChainライブラリにあるOpenAIクラスの設定でmax_tokensを3500以上の大きな数値にして不具合が生じていましたが、2048以下にすると正常動作しました。上限はまだ調べていません。
デフォルトでは256になっていて回答が尻切れになるケースがあり困っていましたが、これで解決です。
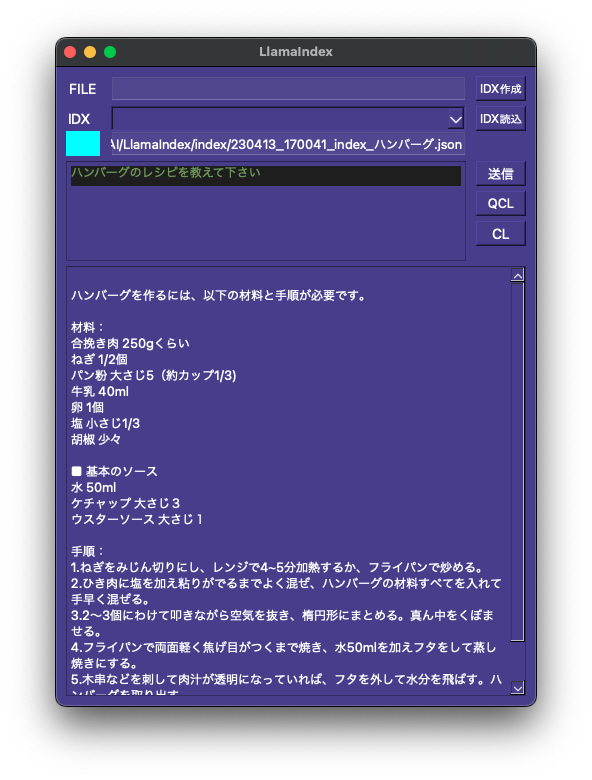
ネットで収集した料理レシピを1つのPDFファイルにまとめてインデックスファイルにするつもりです。ただ広告も取り込んでいるためそれらを消去する必要があり、下準備に結構時間が掛かりそうです。あと似たような料理でレシピの内容が混ざらないかチェックが必要ですね。
def loadIDX(self):
# インデックスの読込
llm_predictor = LLMPredictor(llm=OpenAI(temperature=0, model_name="text-davinci-003", max_tokens=2048))
service_context = ServiceContext.from_defaults(llm_predictor=llm_predictor)
choice = self.choice.currentText()
if choice == "C++逆引き":
index_path = "/AI/LlamaIndex/index/index_C++逆引き.json"
elif choice == "Python逆引き":
index_path = "/AI/LlamaIndex/index/index_Python逆引き.json"
else:
index_path = self.input2.text()
try:
self.index = GPTSimpleVectorIndex.load_from_disk(save_path= index_path, service_context=service_context)
except Exception as e:
print('エラーが発生しました:', e)
self.output.setText(str(e))
self.box.setStyleSheet('background-color: #ff00ff')
return
else:
self.box.setStyleSheet('background-color: #00ffff')
self.output.setText("IDX読込完了")