[M1 Mac, Monterey 12.6.3, Python 3.10.4]
py2appによるpyファイルのappファイル化がうまくいかないので、LlamaIndexライブラリの内容を分析し、C++への移植を目指すことにしました。
分析にあたりLlamaIndexライブラリを改変し、デバッグ仕様にしています。
思っていたよりも内容が複雑で何度かくじけかけましたが、ようやく光が見えてきました。
Pythonスクリプトを走らせた時の出力の内容とLlamaIndexライブラリの関連がとても見えにくく、printデバッグで細かくスクリプトやライブラリの動作を追跡しないと何が何だか分かりません。
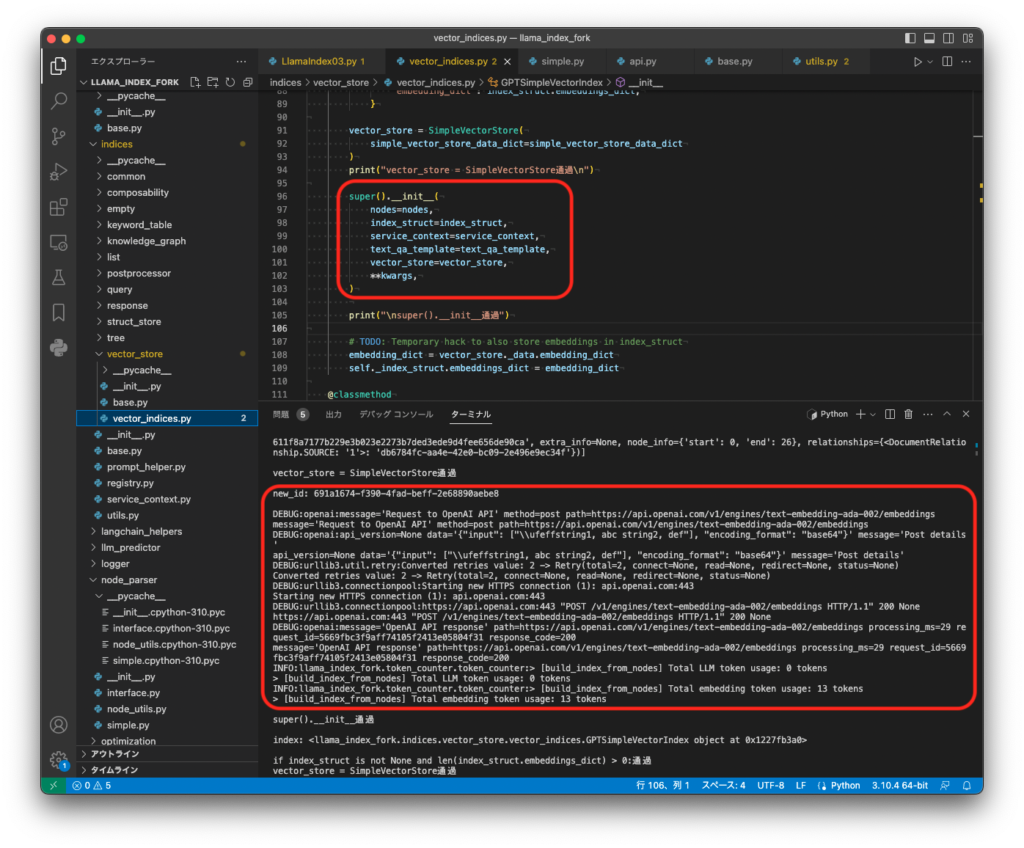
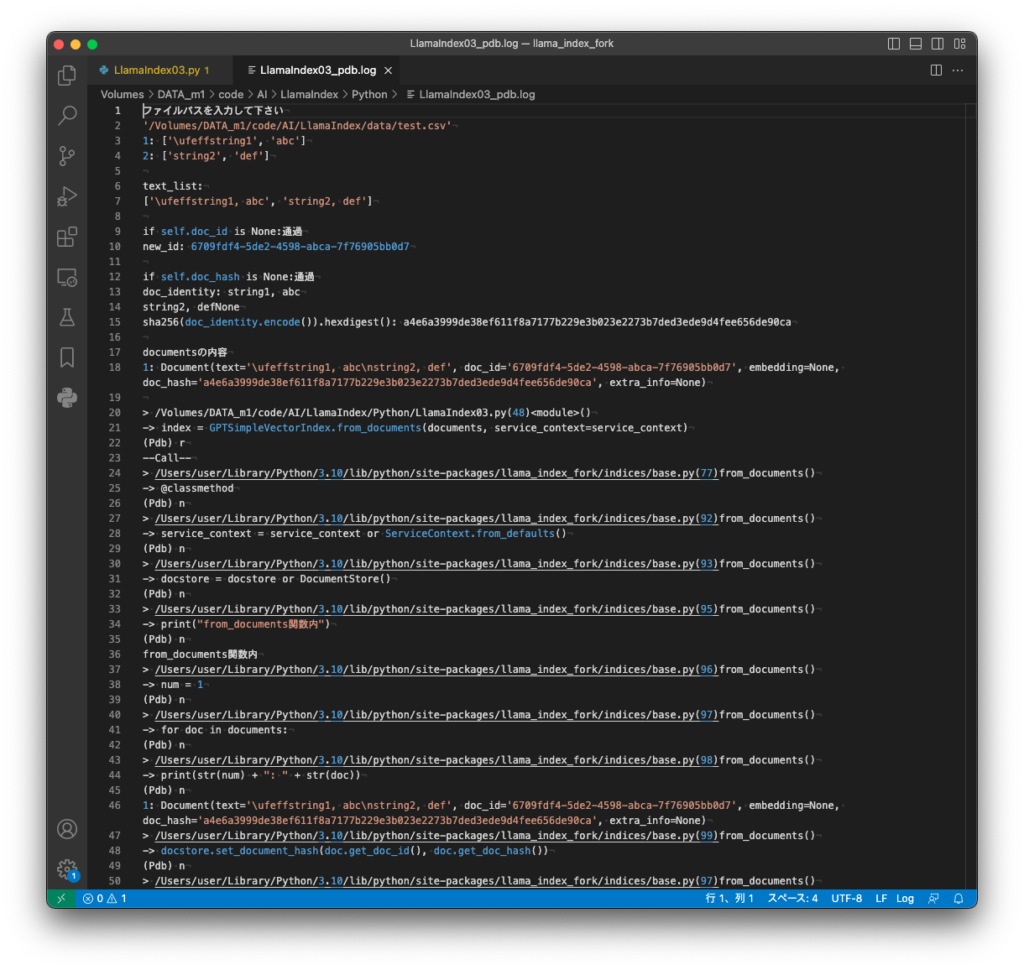
そんなこんなでCSVファイルをindex化する所までたどり着いたものの、ここでいよいよ分からなくなりPython用のデバッガpdbを使いました。
下図赤枠の所をrコマンド、nコマンド、sコマンドで刻んで進めていきましたが、どこまで行っても目的箇所へたどり着けず300行ぐらいで追いかけるのを断念しました。Pythonの標準ライブラリを多用していますし、とてもじゃないですがC++へ移植など工数がいくつあっても足りないです。
Embbedingについては他のアプローチを模索していきます。
import os, logging, sys
from pathlib import Path
# llama_index改変版
from llama_index_fork import download_loader,LLMPredictor, GPTSimpleVectorIndex, ServiceContext
from langchain import OpenAI
from mylib import MySimpleCSVReader
import pdb
# APIキーを環境変数から取得
apiKey = os.getenv("CHATGPT_API_KEY")
os.environ["OPENAI_API_KEY"] = apiKey
# ログレベルの設定(DEBUG)
logging.basicConfig(stream=sys.stdout, level=logging.DEBUG, force=True)
logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))
# インデックスの作成および保存
llm_predictor = LLMPredictor(llm=OpenAI(temperature=0, model_name="text-embedding-ada-002"))
service_context = ServiceContext.from_defaults(llm_predictor=llm_predictor)
print("ファイルパスを入力して下さい")
file_path = input()
file_path2 = file_path.replace("'", "") # 拡張子判定用
file_path3 = Path(file_path2) # loader用
if file_path2.endswith('.csv'):
# SimpleCSVReader = download_loader("SimpleCSVReader")
loader = MySimpleCSVReader.MySimpleCSVReader()
elif file_path2.endswith('.pdf'):
PDFReader = download_loader("PDFReader")
loader = PDFReader()
else:
print('ファイルがcsv,pdfではありません')
sys.exit()
# documentsの型は、List[Document]
documents = loader.load_data(file=file_path3)
print("documentsの内容")
num = 1
for doc in documents:
print(str(num) + ": " + str(doc) + "\n")
num = num + 1
# ブレークポイント設定
pdb.set_trace()
index = GPTSimpleVectorIndex.from_documents(documents, service_context=service_context)
print("\nindex: " + str(index) + "\n")
index.save_to_disk('index.json')
# インデックスの読込
llm_predictor = LLMPredictor(llm=OpenAI(temperature=0, model_name="text-davinci-003", max_tokens=3500))
service_context = ServiceContext.from_defaults(llm_predictor=llm_predictor)
index = GPTSimpleVectorIndex.load_from_disk(save_path="index.json", service_context=service_context)
# 質問(Ctrl+cで終了)
while True :
print("質問を入力して下さい")
question = input()
print(index.query(question))