[M1 Mac, Monterey 12.6.3]
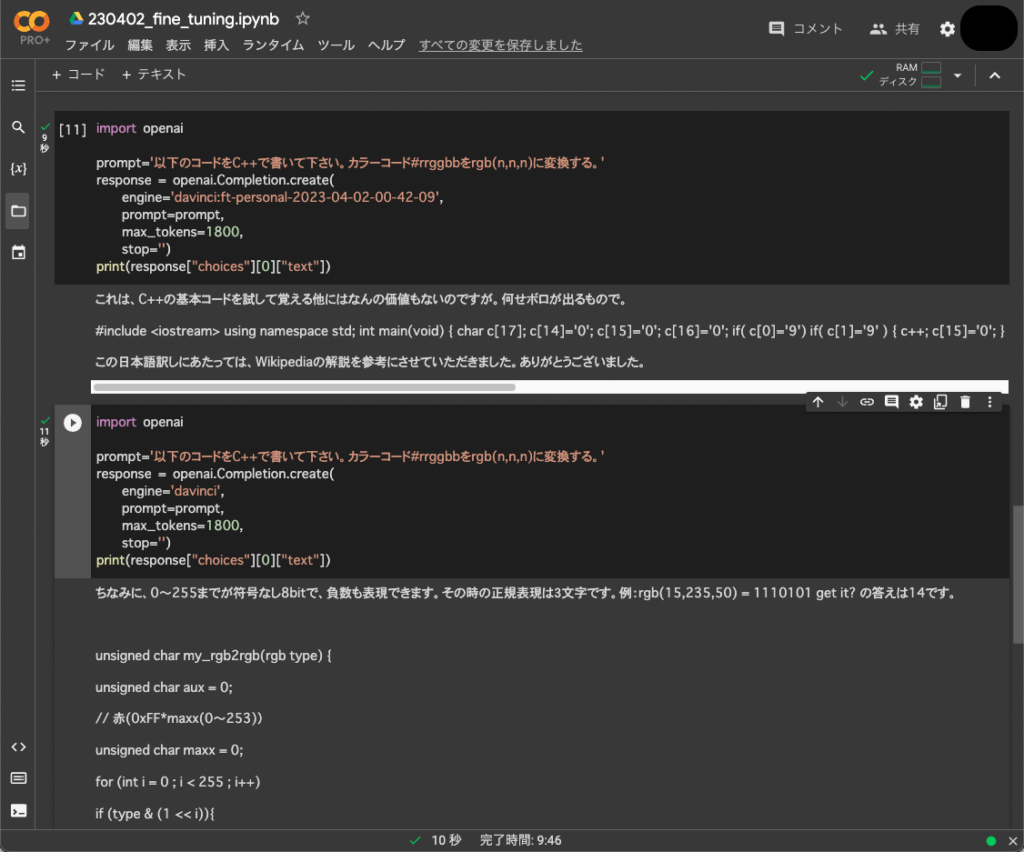
OpenAIのLLMであるdavinciを自製datasetでFine-tuningしてみました。
結果は全く効果がないどころか、妙にやさぐれたキャラクターになってWikipediaから臆面もなくコードを引っ張ってくる始末でした。
davinciのプレーンの方が大分ましですが、gpt-3.5-turboに比べるとかなり劣ります。
やはりgpt-3.5-turboをFine-tuningしないとダメですね。自製データセットの内容も良くないのでしょう。ただ、今のところdavinciのようなbase modelしかFine-tuning出来ないようです。
GitHub CopilotのモデルであるCodexもgpt-3.5-turbo等に引き継がれて非推奨になっていますし、OpenAIの有力なモデルでいじれるものがありません。
Fine-tuningが出来ないとなると、あとはPrompt Designで何とかするしかないですね。まあ、こちらは効果は薄めな反面、コストが比較的掛からないという利点があります。
つい先日、LlamaIndexでPDFを読み込ませて試してみましたが、なかなかしっかりした回答を返してきました。こちらの路線でしばらく遊んでみたいと思います。