複数のCSVファイルからある行を抽出し、1つのファイルにまとめるコードです。
with文を追記モード(mode = ‘a’)にします。
一連のCSVファイル処理でCSVモジュールの使いやすさを認識しました。
数値データの配列ではなく単なる表として扱うのであれば、pandasよりもこちらの方が適しているように思います。
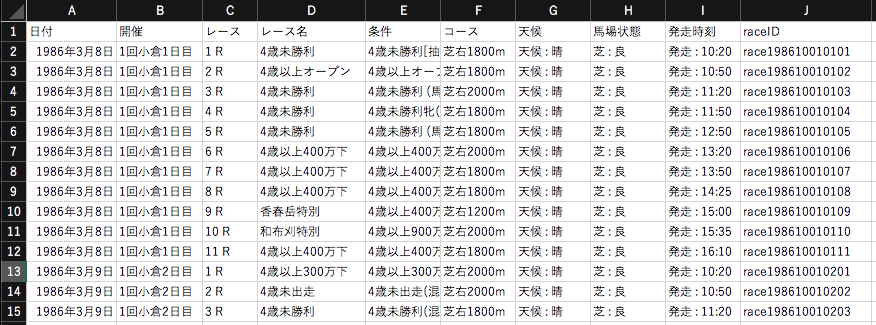
コード例は[Python]215の図にあるレースファイルから図右下のレース名他を抽出します。
import glob,csv
# 1986年から2020年のレースファイルからレース名他を抽出して競馬場毎にまとめる
for year in range(1986,2021):
for f in glob.glob(f'/horse_racing/race/{year}/*/*/*.csv', recursive=True):
file_new = f.split('race/')[0] + 'race_name/' + f.split('race/')[1][:-26] + f'race_n_{year}' + f.split('race/')[1][-26:-24] + '.csv'
with open (f, mode="r", encoding="shift_jis") as f1:
with open(file_new, mode="a", encoding="shift_jis") as f2: # 追記モード
writer = csv.writer(f2)
for i,row in enumerate(csv.reader(f1)):
if i != 0: # 行0の列インデックスは削除
if '010101' == f[-10:-4]: # 1回1日1Rだけ列タイトルを書き込み
if i == 1: # 列タイトル
rows = [e[2:] for e in row[21:30]] + ['raceID']
writer.writerow(rows)
if '年' in row[21]: # 列21に'年'がある行を書き込み
rows = row[21:30] + [f[-20:-4]]
writer.writerow(rows)