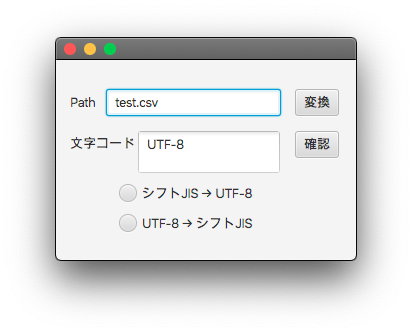
[macOS Catalina 10.15.7]
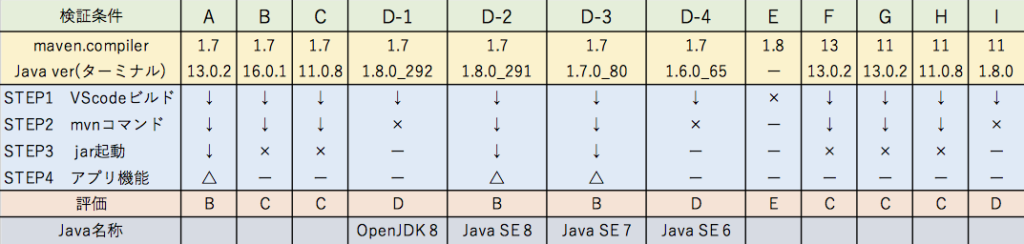
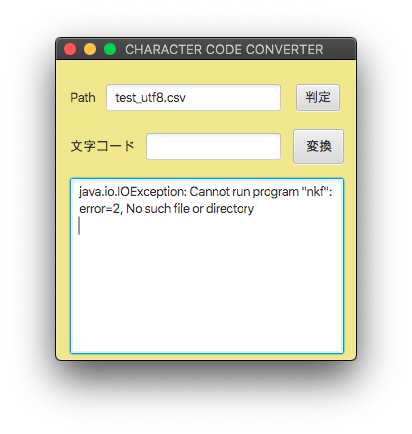
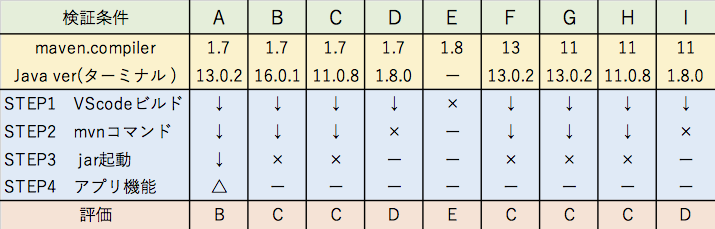
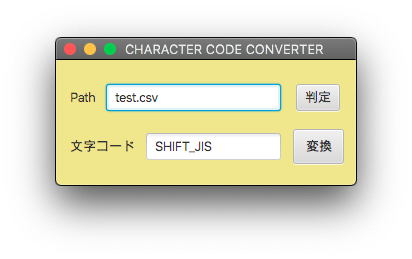
VScodeでnkfコマンドを使った文字コード変換ツールはうまく作れましたが、universalchardetを使ったコードはjar実行ファイルにすると正常に動作しません。
macOSの影響かもしれないと考え、Mojave搭載機で試してみたものの結果はNGでした。
どうイジってもダメなので、EclipseでMavenではなく普通のJavaプロジェクトを作成してみるとあっさり成功しました。VScodeの軽量環境が気に入っていただけに残念です。
ところで未だにEclipseでまともなMavenプロジェクトを作れないでいます。今後の課題です。
自分の開発環境を確立するまではARMアーキテクチャのAppleシリコンMacへの移行はしない方がいいと考えています。リーク情報ではM1XやM2の開発状況がはかばかしくない、というのもありますが大丈夫なんでしょうか。
開発環境の脱RosettaやUSBポート等の拡張性に進歩がないのであれば、今年の購入は見送ってIntel Macを当面使い続けるつもりです。
package application;
import java.io.IOException;
import org.mozilla.universalchardet.UniversalDetector;
public class FileCharDetector {
// コンストラクタ
public FileCharDetector(){
}
public String main(String path) throws IOException {
byte[] buf = new byte[4096];
java.io.FileInputStream fis = new java.io.FileInputStream(path);
UniversalDetector detector = new UniversalDetector(null);
// 判定開始
int nread;
while ((nread = fis.read(buf)) > 0 && !detector.isDone()) {
detector.handleData(buf, 0, nread);
}
// 判定終了
detector.dataEnd();
// 判定結果取得
final String detectedCharset = detector.getDetectedCharset();
// 判定の初期化
detector.reset();
fis.close();
return detectedCharset;
}
}