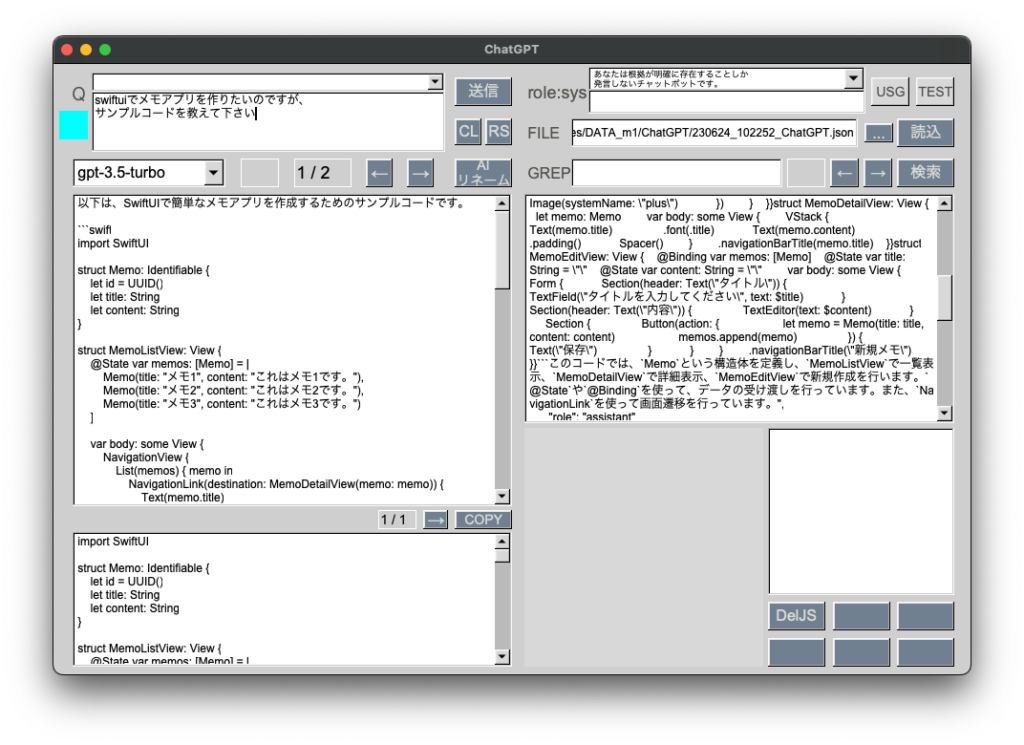
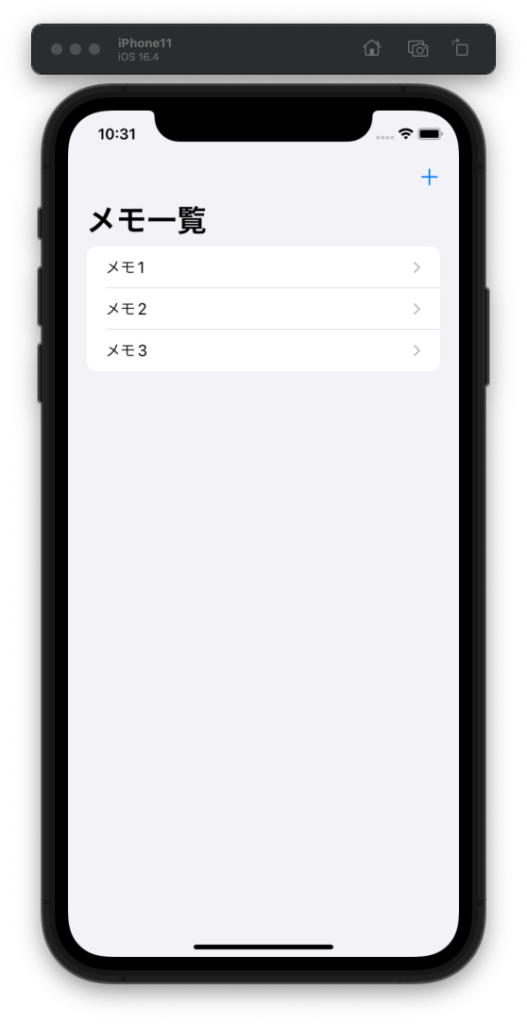
XcodeのUIといいSwiftの言語仕様といい、相変わらずの使いにくさで愛着が生まれそうにありません。特にforEach文のinの後に置くべき反復変数を省略できる、というまぎらわしい仕様にはあきれました。C#のようにforeach(int num in numbers)にして欲しいです。inの後に続く単語が何も関係ないと知り、少しキレそうになりました。Flutterで作ったらこのようなストレスとは無縁になるのでしょうか。
次はコンプリケーションに対応させて、文字盤からアプリを呼び出せるようにします。
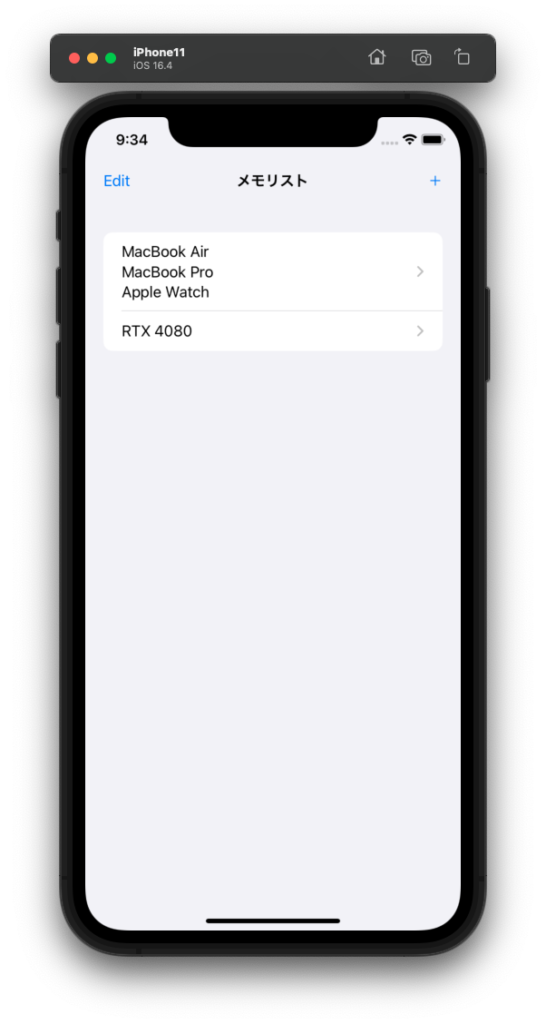
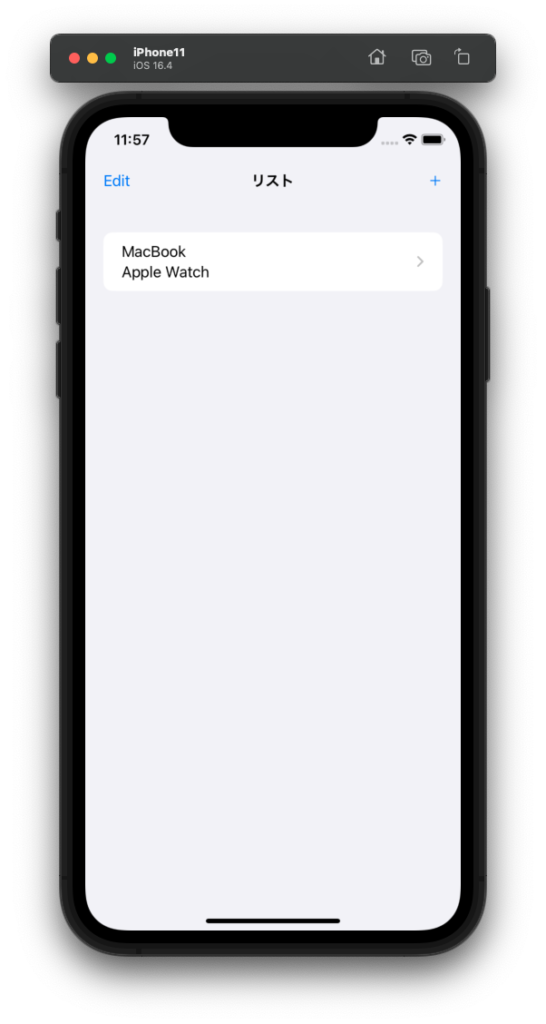
watchOS版 実機
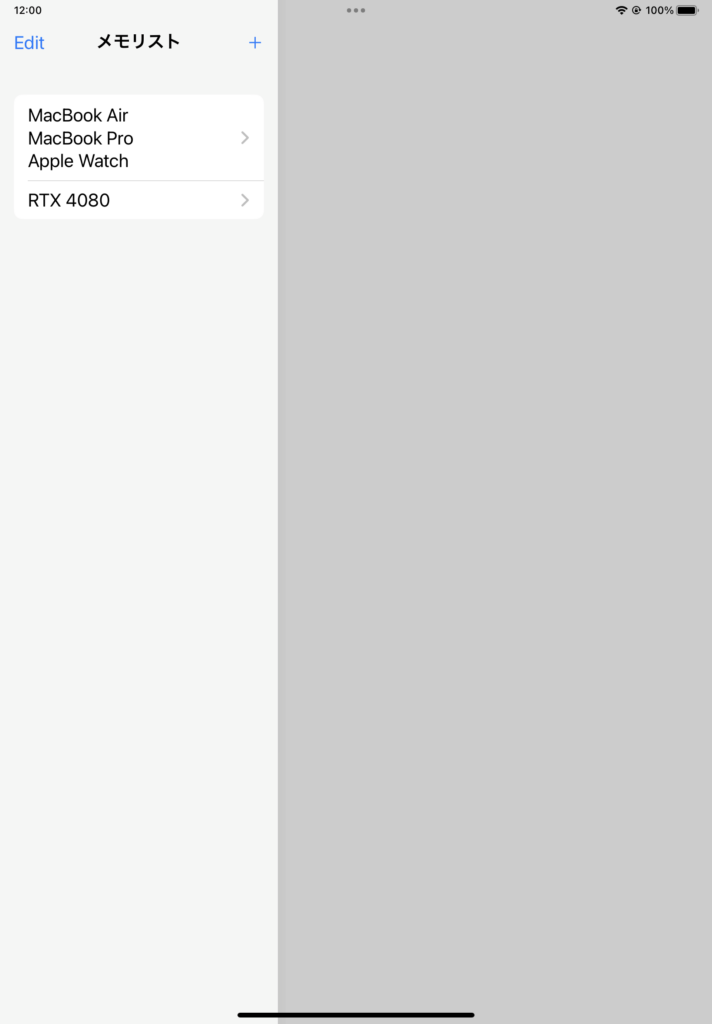
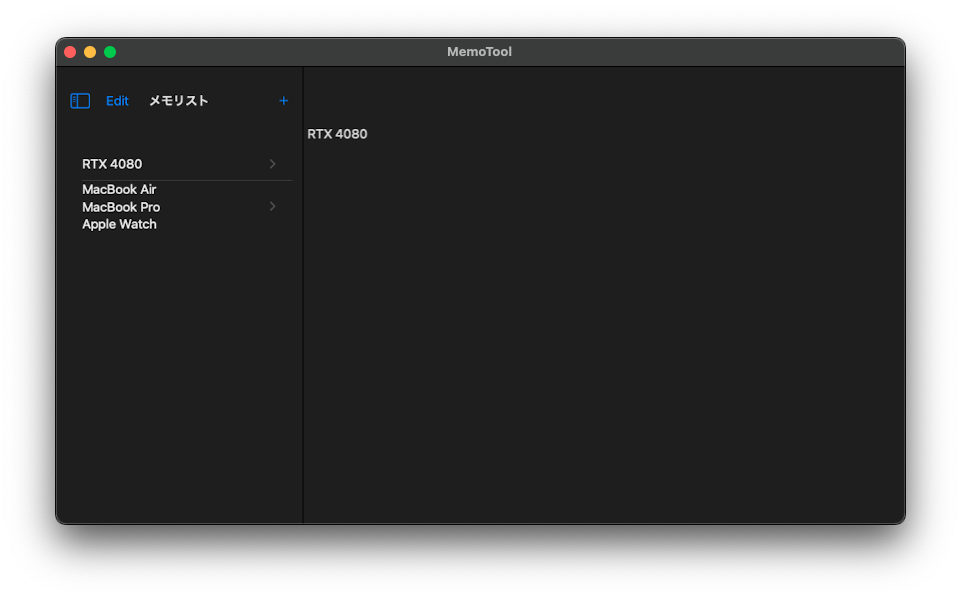
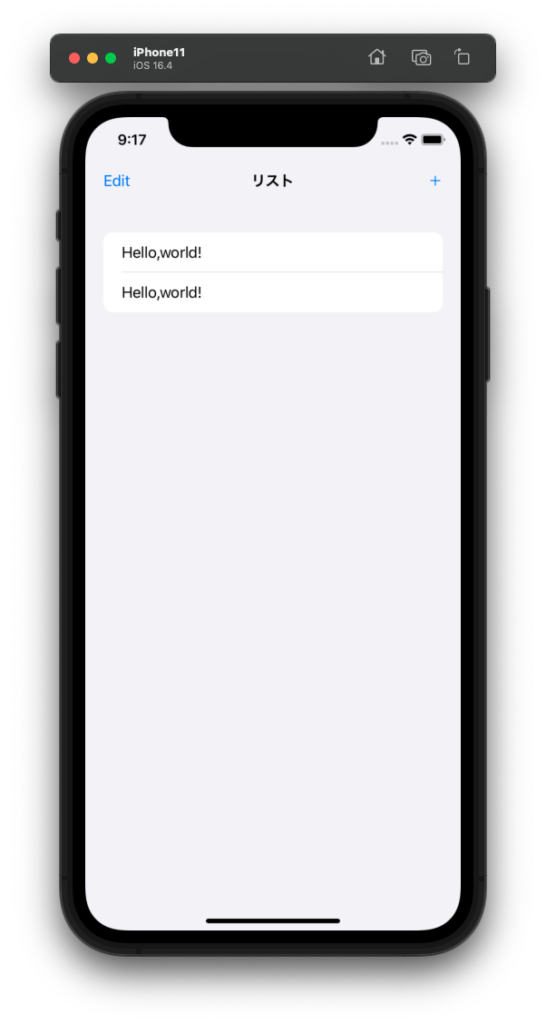
iOS版
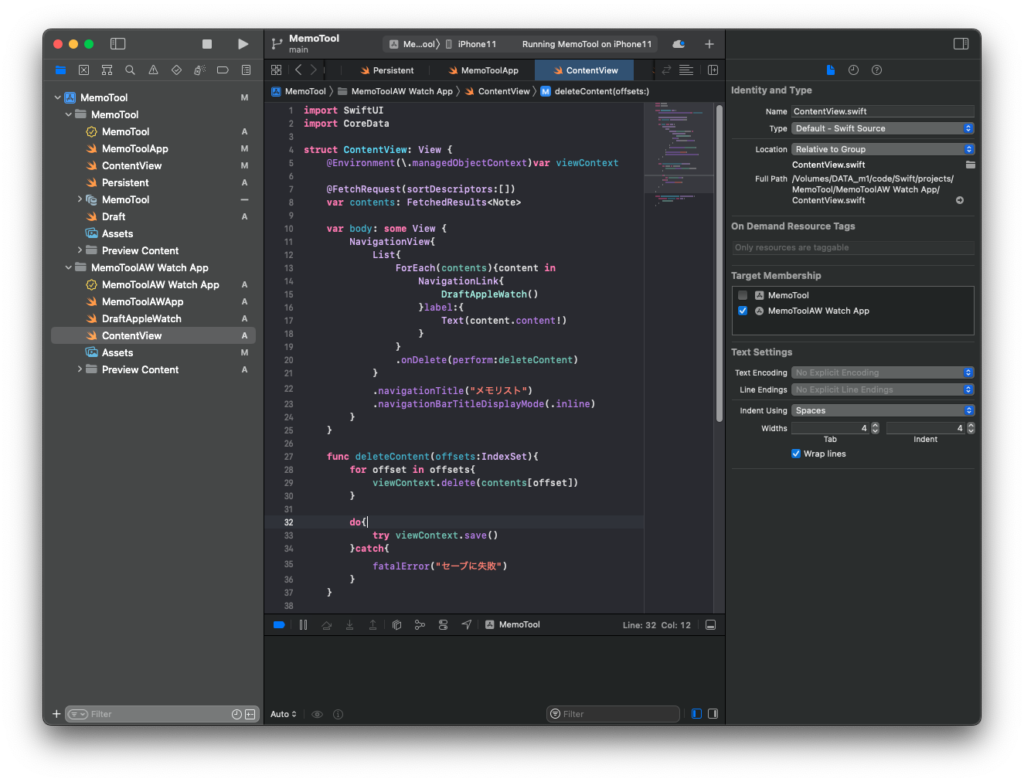
import SwiftUI
import CoreData
struct ContentView: View {
@Environment(\.managedObjectContext)var viewContext
@FetchRequest(sortDescriptors:[])
var contents: FetchedResults<Note>
var body: some View {
NavigationView{
List{
ForEach(contents){content in
NavigationLink{
DraftAppleWatch()
}label:{
Text(content.content!)
}
}
.onDelete(perform:deleteContent)
}
.navigationTitle("メモリスト")
.navigationBarTitleDisplayMode(.inline)
}
}
func deleteContent(offsets:IndexSet){
for offset in offsets{
viewContext.delete(contents[offset])
}
do{
try viewContext.save()
}catch{
fatalError("セーブに失敗")
}
}
}
struct ContentView_Previews: PreviewProvider {
static var previews: some View {
ContentView()
}
}