[Mac M2 Pro 12CPU, Sonoma 14.7.1, clang++ 16.0.0]
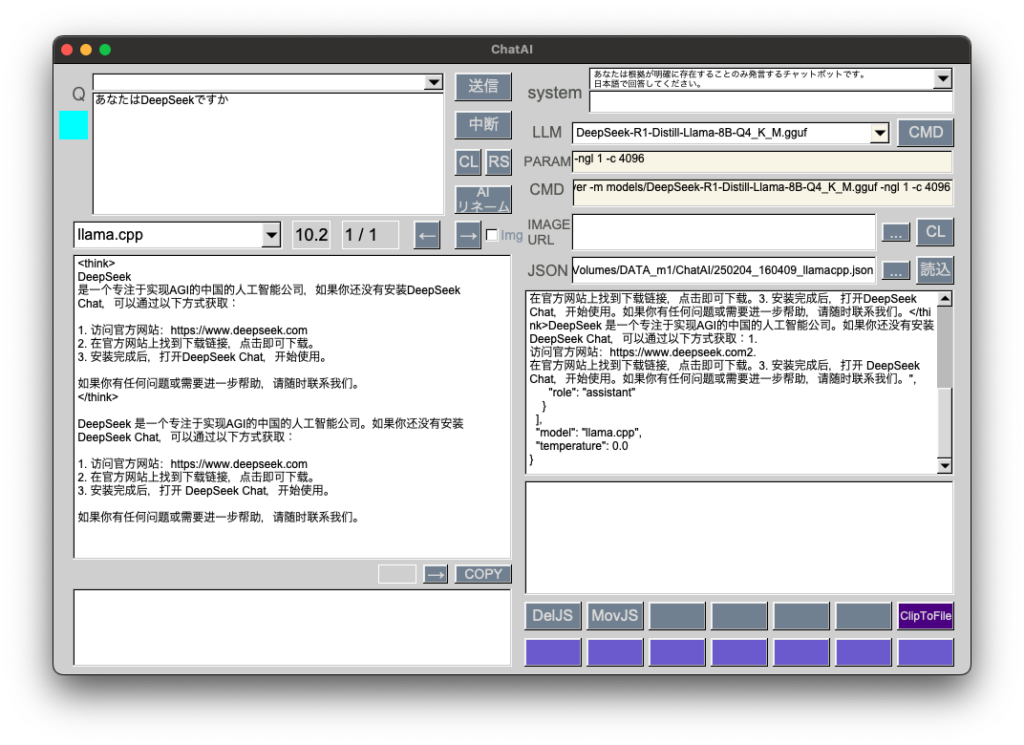
[C++] 383は非公開
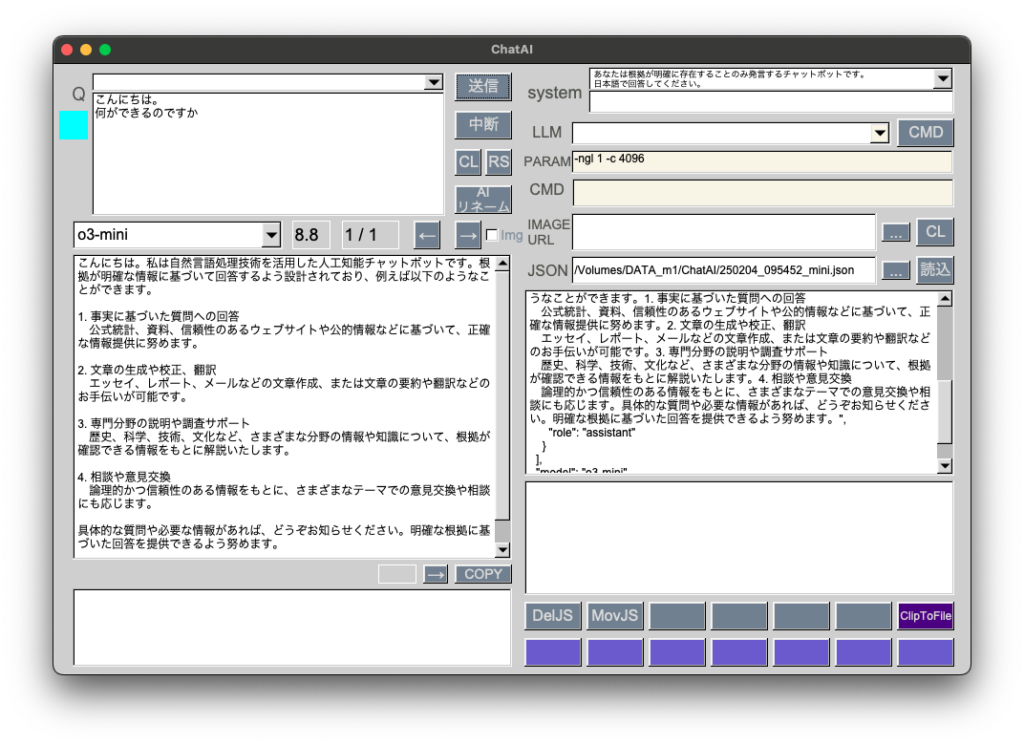
普段はgpt-4oで十分足りていますが、評判がいいようなのでo3-miniも使えるようにしました。temperatureを削除して、reasoning_effortを追加しています。
if(countQ == 0 && load == false){
cout << "question1回目\n" << question << endl;
cout << "model: \n" << model.c_str() << endl;
if (model.find("gpt") != string::npos){
// gpt-4
requestData = "{\"model\":\"" + model + "\", \"messages\":[{\"role\":\"system\",\"content\":\"" + systemStr + "\"},{\"role\":\"user\",\"content\":\"" + question + "\"}], \"temperature\":0.0}";
} else if (model.find("mini") != string::npos){
// o3-mini
requestData = "{\"model\":\"" + model + "\", \"messages\":[{\"role\":\"system\",\"content\":\"" + systemStr + "\"},{\"role\":\"user\",\"content\":\"" + question + "\"}], \"reasoning_effort\":\"medium\"}";
} else if (model.find("llama.cpp") != string::npos){
// llama.cpp
requestData = "{\"model\":\"" + model + "\", \"messages\":[{\"role\":\"system\",\"content\":\"" + systemStr + "\"},{\"role\":\"user\",\"content\":\"" + question + "\"}], \"temperature\":0.0}";
} else if (model.find("sonar") != string::npos){
// perplexity
requestData = "{\"model\":\"" + model + "\", \"messages\":[{\"role\":\"system\",\"content\":\"" + systemStr + "\"},{\"role\":\"user\",\"content\":\"" + question + "\\n日本語で回答してください。" + "\"}], \"temperature\":0.0}";
}