[M1 Mac, Big Sur 11.7.2, Python 3.10.4, MAMP 6.7, MySQL 5.7.39]
数千万件の巨大データベースを作成するため久しぶりにMySQLをいじっています。MAMPの設定は2021年4月以来なので1年9ヶ月ぶりになります。
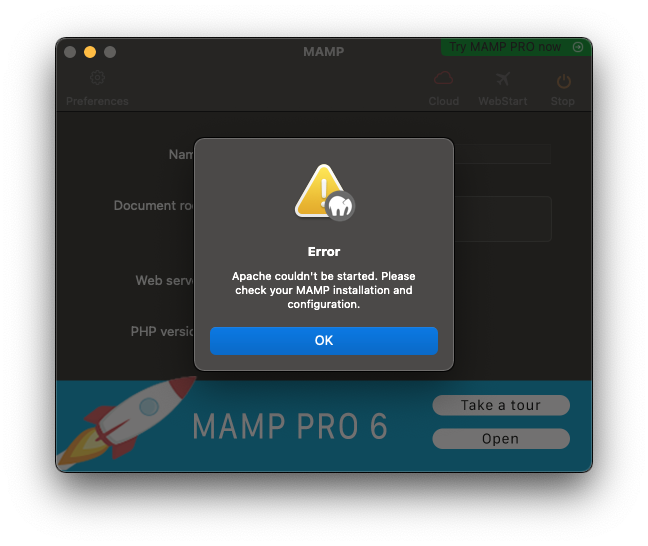
Intel Macでは問題なかったMAMPのポート設定(Apache:80, MySQL:3306)では下図のエラーになるためデフォルト設定(Apache:8888, MySQL:8889)で使っています。
phpMyAdminで管理していますが、データが大きすぎるからか動作が重いように感じます。オラクルが開発しているMySQL Workbenchを試してみたいです。
# /etc/apache2/httpd.confに以下を追記
ServerName localhost:80~ $ sudo httpd -k restart
~ $ sudo lsof -i:80
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
httpd 37303 root 4u IPv6 0xf22e6e946f960a71 0t0 TCP *:http (LISTEN)
httpd 41597 _www 4u IPv6 0xf22e6e946f960a71 0t0 TCP *:http (LISTEN)
# httpdは正常に動作しているがMAMPはエラー。MAMPの不具合?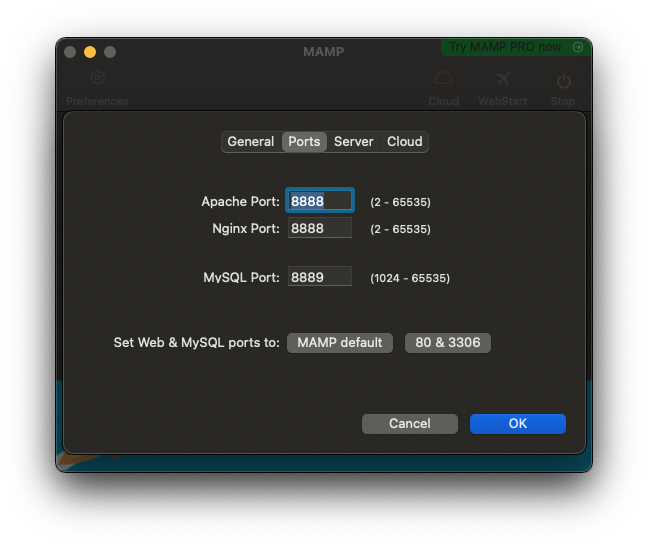
import csv, mysql.connector
import pandas as pd
import time,datetime,glob
# 処理時間を測定
start = time.time()
config = {
'user': 'root',
'password': 'root',
'host': 'localhost',
'port': 8889,
'raise_on_warnings': True
}
num = 1
for file in glob.glob(f'/*.csv'):
# CSVファイル名を抽出しtable名にする
tablename = file[-12:-4]
# print(tablename)
column_title = ['A', 'B', 'C', 'D', 'E']
column_type = ['varchar(256)','varchar(512)','varchar(512)','int(9)','int(8)']
# SQL文に使う列名&データ型の文字列を作成する
column_l = []
for ti,ty in zip(column_title,column_type):
column = ti + ' ' + str(ty)
column_l.append(column)
# print(column_l)
# SQL仕様に整形
column_l_str = str(column_l).replace('[','(').replace(']',')').replace("'",'')
# print(column_l_str)
# MySQLに接続
conn = mysql.connector.connect(**config)
cur = conn.cursor()
# データベース名dataにtableを作成する(4バイト文字対応)
sql = f"create table data.{tablename} {column_l_str} CHARACTER SET utf8mb4"
cur.execute(sql)
cur.execute('begin')
# CSVファイルを読み込み、各行をtableに挿入する
with open(file, 'rt', encoding='UTF-8') as f:
reader = csv.reader(f)
for i,row in enumerate(reader):
# print(f'row {row}')
if i != 0:
row_str = str(row).replace('[','(').replace(']',')')
# print(f'{i+1}:{row_str}')
sql = f'insert into data.{tablename} values {row_str}'
cur.execute(sql)
cur.execute('commit')
conn.close()
# 処理時間算出(秒)
process_time = time.time() - start
td = datetime.timedelta(seconds = process_time).total_seconds()
# 小数点第2位まで表示
td_2f = f'{td:.2f}'
print(f'{num}:{td_2f}')
num = num + 1