[M1 Mac, Monterey 12.6.3, Python 3.10.4]
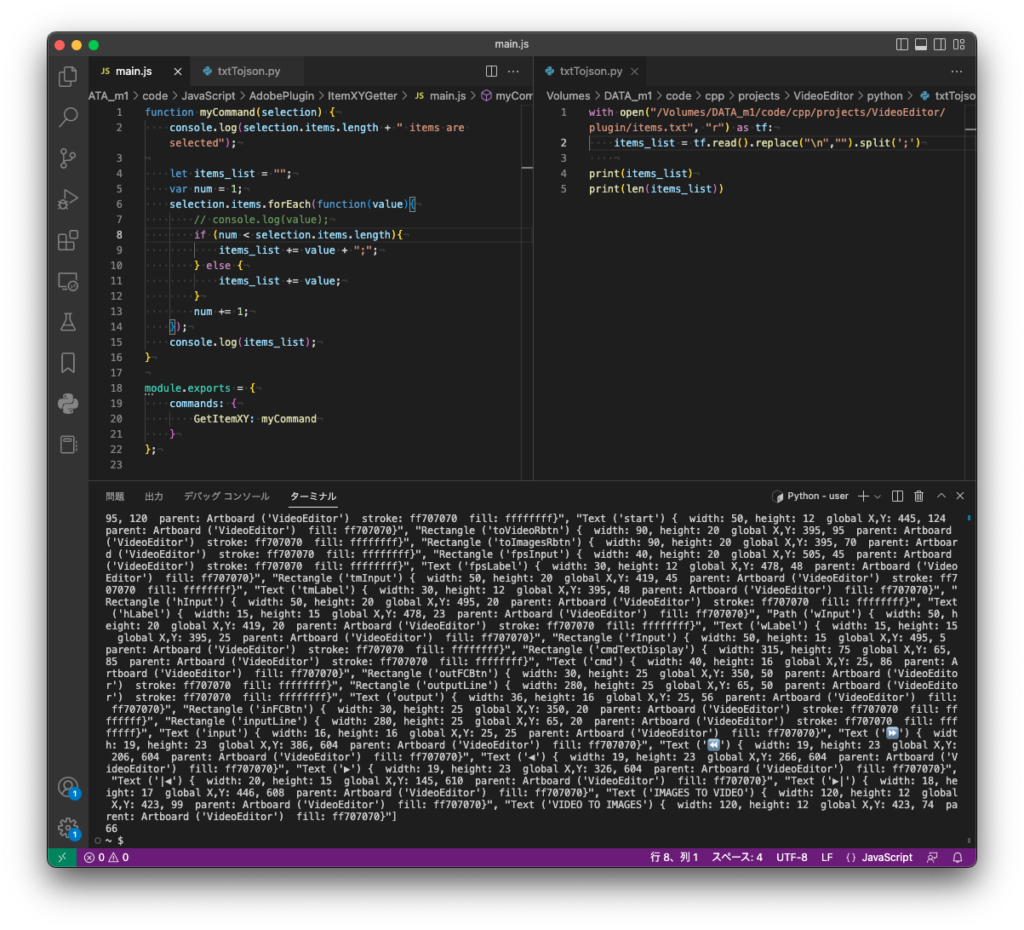
C++ソースコードを読み込み、JSON要素との照合を行い、その結果をBool値で返すスクリプトを書きました。
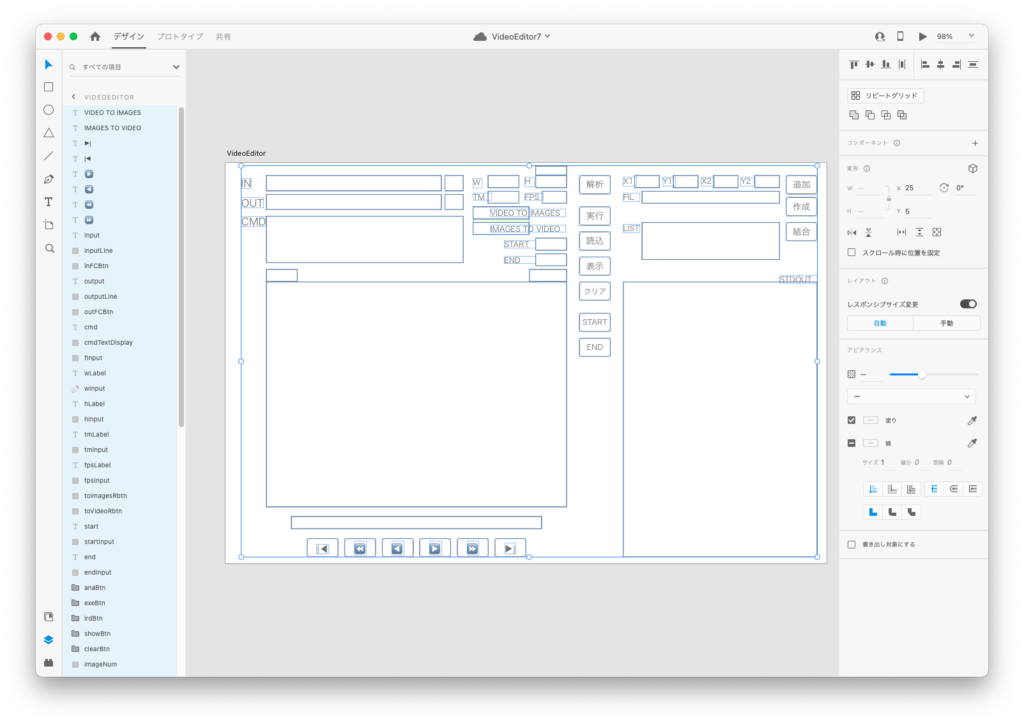
具体的にはFLTKウィジェットの新しいオブジェクトを作成する行の座標、幅、高さがAdobe XDのデータと一致しているかどうか判定します。
一致していなければAdobe XDのデータに書き換えます。この部分については次回以降記事にする予定です。
久々にpandasの出番でした。相変わらずの高機能です。
import pandas as pd
file = '/VideoEditor/src/VideoEditor.cpp'
with open(file) as f:
lines = f.readlines()
# 改行コードを削除
lines_strip = [line.strip() for line in lines]
df = pd.read_json('items.json')
print(df)
columns = df.columns.values
print(columns)
for col in columns:
data = df.loc[:, col]
# print(data.values)
data2 = str(data.values[0]) + "," + str(data.values[1]) + "," + str(data.values[2]) + "," + str(data.values[3])
print(data2)
var_str = col + " = new"
print(var_str)
line_str = [line for line in lines_strip if var_str in line]
try:
line_str2 = line_str[0]
print(line_str)
str_exist = data2 in line_str2
print(str_exist)
except Exception as e:
print(e)395,70,90,45
convertArea = new
list index out of range
885,180,60,12
STDOUT = new
list index out of range
635,190,310,440
browser = new
['browser = new Fl_Browser(635,190,310,440,"STDOUT");']
True
895,95,50,30
comBtn = new
['comBtn = new Fl_Button(895,95,50,30,"結合");']
True
895,55,50,30
filBtn = new
['filBtn = new Fl_Button(895,55,50,30,"モザイク\\n作成");']
True
895,20,50,30
culcBtn = new
['culcBtn = new Fl_Button(895,20,50,30,"モザイク\\n追加");']
True