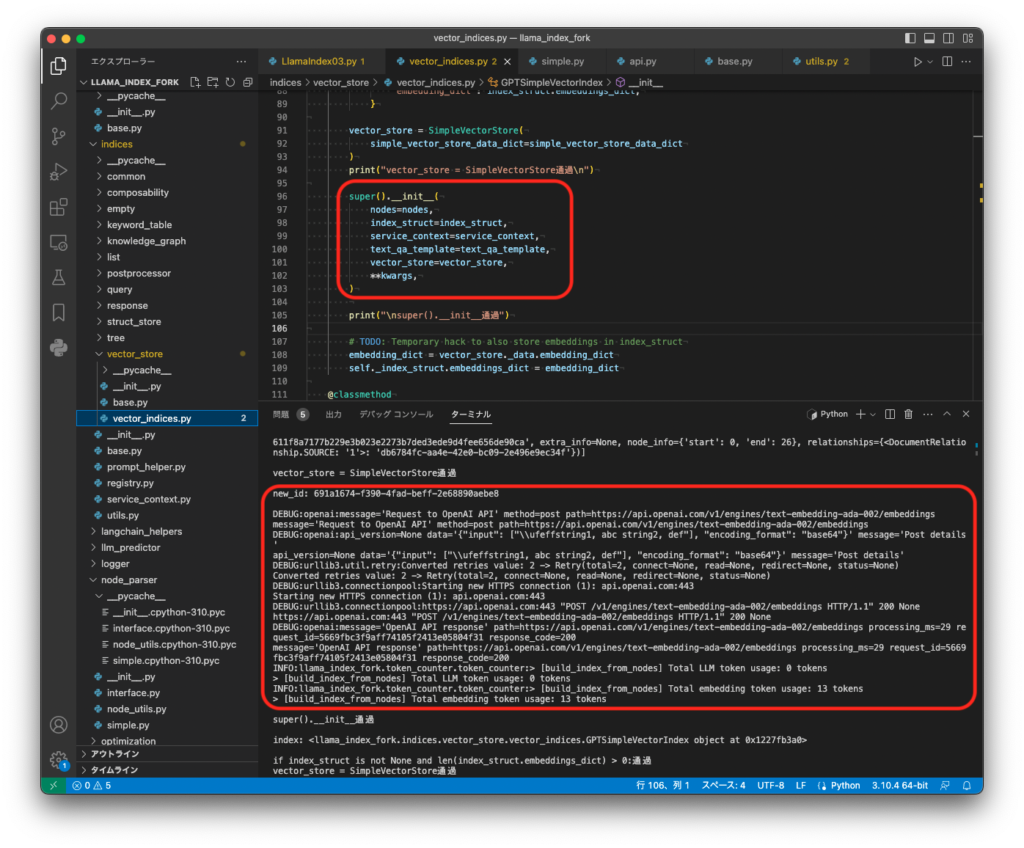
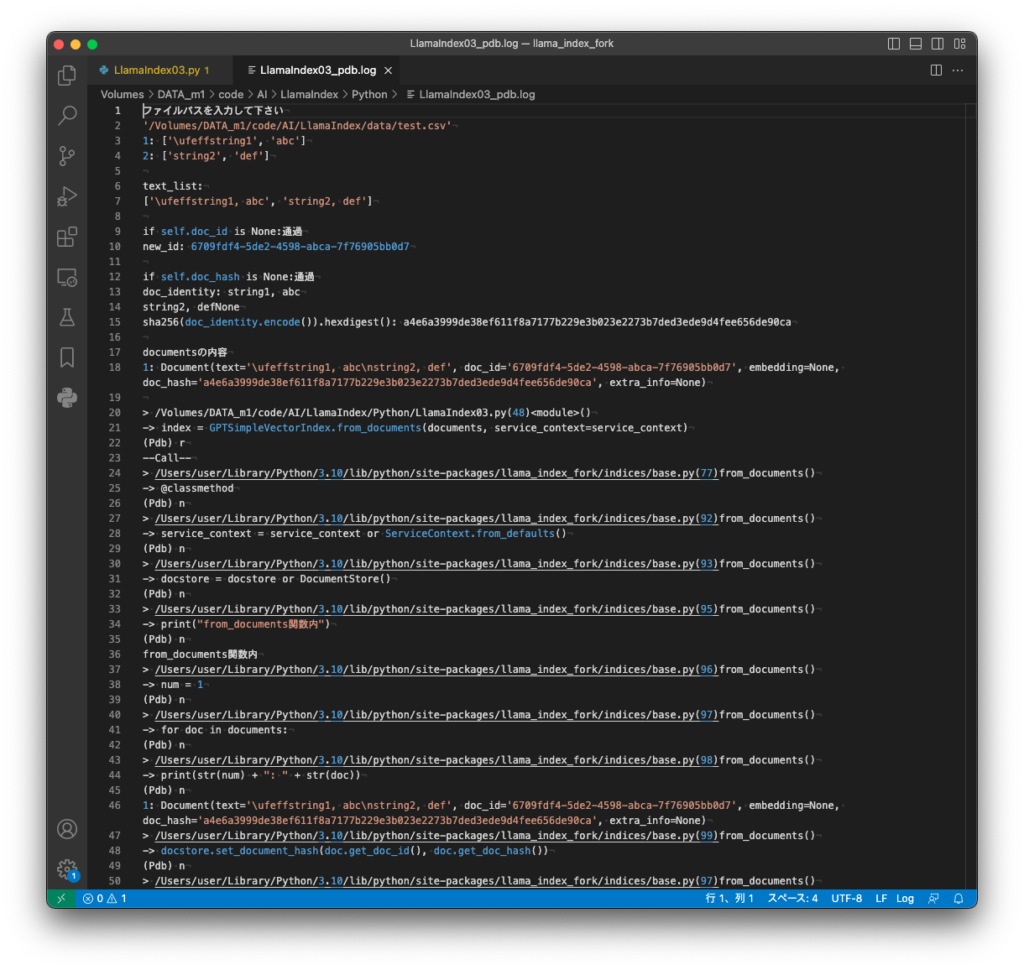
[M1 Mac, Monterey 12.6.3, Python 3.10.4]
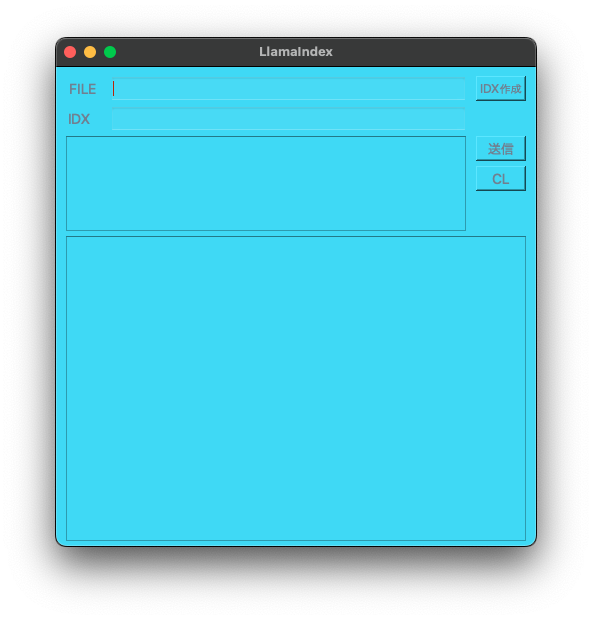
LlamaIndexアプリを完成させました。
exeファイルやappファイルには出来ませんでしたが、シェルスクリプトにするとアプリ風になるのでこれでけりを付けました。
ChatGPT APIを使い出して1ヶ月と1週が経過し、私自身だいぶ落ち着きを取り戻しつつあります。
import os, logging, sys
from pathlib import Path
from PyQt6.QtWidgets import QLabel,QWidget,QApplication,QTextEdit,QLineEdit,QPushButton
from PyQt6.QtCore import Qt
from llama_index import download_loader,LLMPredictor, GPTSimpleVectorIndex, ServiceContext
from langchain import OpenAI
import datetime
class LlamaIndex(QWidget):
def __init__(self):
super().__init__()
self.setWindowTitle("LlamaIndex")
self.setGeometry(100,100,480,480)
self.setStyleSheet('background-color: #483D8B')
self.setAcceptDrops(True)
file = QLabel('FILE',self)
file.setGeometry(10,15,34,16)
file.setStyleSheet('color: #FFFFFF; font-size: 14pt;')
file.setAlignment(Qt.AlignmentFlag.AlignCenter)
self.input= QLineEdit('',self)
self.input.setGeometry(55,10,355,25)
self.input.setAcceptDrops(True)
idxBtn = QPushButton('IDX作成',self)
idxBtn.setGeometry(420,10,50,25)
idxBtn.setStyleSheet('color: #FFFFFF; font-size: 12pt;')
idxBtn.released.connect(self.makeIDX)
idx = QLabel('IDX',self)
idx.setGeometry(10,45,26,16)
idx.setStyleSheet('color: #FFFFFF; font-size: 14pt;')
idx.setAlignment(Qt.AlignmentFlag.AlignCenter)
self.input2= QLineEdit('',self)
self.input2.setGeometry(55,40,355,25)
self.input2.setAcceptDrops(True)
self.idxBtn2 = QPushButton('IDX読込',self)
self.idxBtn2.setGeometry(420,40,50,25)
self.idxBtn2.setStyleSheet('color: #FFFFFF; font-size: 12pt;')
self.idxBtn2.released.connect(self.loadIDX)
send = QPushButton('送信',self)
send.setGeometry(420,70,50,25)
send.setStyleSheet('color: #FFFFFF; font-size: 14pt;')
send.released.connect(self.sendQuestion)
clear = QPushButton('CL',self)
clear.setGeometry(420,100,50,25)
clear.setStyleSheet('color: #FFFFFF; font-size: 14pt;')
clear.released.connect(self.clear)
self.questionInput = QTextEdit('',self)
self.questionInput.setGeometry(10,70,400,95)
self.questionInput.setAcceptDrops(False)
self.output = QTextEdit('',self)
self.output.setGeometry(10,170,460,305)
self.output.setAcceptDrops(False)
# APIキーを環境変数から取得
apiKey = os.getenv("CHATGPT_API_KEY")
os.environ["OPENAI_API_KEY"] = apiKey
# ログレベルの設定(DEBUG)
logging.basicConfig(stream=sys.stdout, level=logging.DEBUG, force=True)
logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))
def makeIDX(self):
# インデックスの作成および保存
llm_predictor = LLMPredictor(llm=OpenAI(temperature=0, model_name="text-embedding-ada-002"))
service_context = ServiceContext.from_defaults(llm_predictor=llm_predictor)
data_path = self.input.text()
data_path2 = data_path.replace("'", "") # 拡張子判定用
data_path3 = Path(data_path2) # loader用
if data_path2.endswith('.csv'):
SimpleCSVReader = download_loader("SimpleCSVReader")
loader = SimpleCSVReader()
elif data_path2.endswith('.pdf'):
PDFReader = download_loader("PDFReader")
loader = PDFReader()
else:
print('ファイルがcsv,pdfではありません')
sys.exit()
nodes = loader.load_data(file=data_path3)
index = GPTSimpleVectorIndex.from_documents(nodes, service_context=service_context)
now = datetime.datetime.now()
formatted_time = now.strftime('%y%m%d_%H%M%S')
index_file = "/AI/LlamaIndex/index/" + formatted_time + "_index.json"
index.save_to_disk(index_file)
self.input2.setText(index_file)
self.idxBtn2.click()
def loadIDX(self):
# インデックスの読込
llm_predictor = LLMPredictor(llm=OpenAI(temperature=0, model_name="text-davinci-003", max_tokens=3500))
service_context = ServiceContext.from_defaults(llm_predictor=llm_predictor)
index_path = self.input2.text()
self.index = GPTSimpleVectorIndex.load_from_disk(save_path= index_path, service_context=service_context)
self.output.setText("IDX読込完了")
def sendQuestion(self):
question = self.questionInput.toPlainText()
response = self.index.query(question)
print(response)
self.output.setText(str(response))
def clear(self):
self.input.clear()
self.input2.clear()
self.questionInput.clear()
self.output.clear()
app = QApplication(sys.argv)
window = LlamaIndex()
window.show()
app.exec()