# row[1]の値に数字が含まれていればrow[0]と合わせてcsvファイルに書き込む
for row in csv.reader(f1):
if any(chr.isdigit() for chr in row[1]):
writer.writerow([row[0],row[1].replace('\u3000','')])
import glob,csv,datetime,pathlib
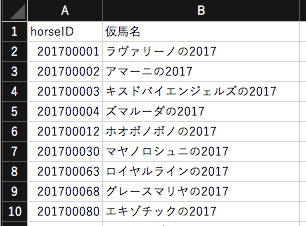
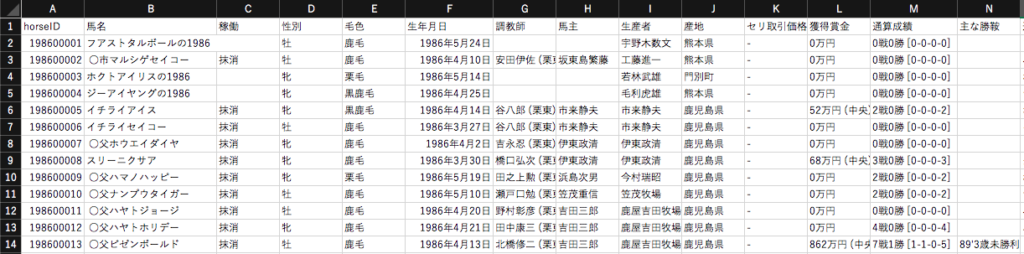
# 2017年から2019年のhorseファイルから仮馬名(誕生年を含む名前)を抽出する
for year in range(2017,2020):
for f in glob.glob(f'/horse_racing/horse/horse{year}.csv'):
# ファイルのメタデータから作成日時を取得
p = pathlib.Path(f)
dt = datetime.datetime.fromtimestamp(p.stat().st_birthtime)
dt_str = dt.strftime('%y%m%d%H%M')
# 新ファイルの先頭に元ファイルの作成日時を付ける
file_new = f'/horse_racing/test/{dt_str}_horse{year}_check.csv'
# 馬名に数字を含む場合、horseIDと仮馬名を抽出してCSVファイルを作成する
with open (f, mode="r", encoding="shift_jis") as f1:
with open(file_new, mode="w", encoding="shift_jis") as f2:
writer = csv.writer(f2)
writer.writerow(['horseID','仮馬名'])
for row in csv.reader(f1):
if any(chr.isdigit() for chr in row[1]):
writer.writerow([row[0],row[1].replace('\u3000','')])
import os
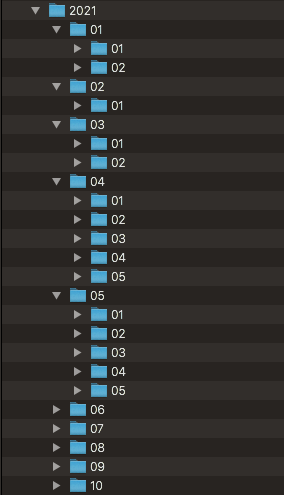
# 2021年各競馬場フォルダを各開催分作成する。競馬場コード、開催回は2桁表記。
l=[2,1,2,5,5,5,6,0,6,4]
for i,e in enumerate(l):
os.mkdir(f'/horse_racing/race/2021/{i+1:02}')
for c in range(e):
os.mkdir(f'/horse_racing/race/2021/{i+1:02}/{c+1:02}')
# file1,file2の設定は省略
with open(file1, 'r', encoding='shift_jis') as f1:
with open(file2, 'w', encoding='shift_jis') as f2:
rows = []
reader = csv.reader(f1)
for row in reader:
for i,v in enumerate(row):
row[i] = v.replace('\n', '')
rows.append(row)
writer = csv.writer(f2)
for row in rows:
writer.writerow(row)
import glob,os,shutil
for year in range(1986,2021):
for f in glob.glob(f'/horse_racing/race_name/{year}/*'):
if os.path.isdir(f):
shutil.rmtree(f)
年フォルダ内のファイルを全て消去
import glob,os
for year in range(1986,2021):
for f in glob.glob(f'/Volumes/DATA_HR/horse_racing/race_name/{year}/*'):
if os.path.isfile(f):
os.remove(f)
import glob,csv
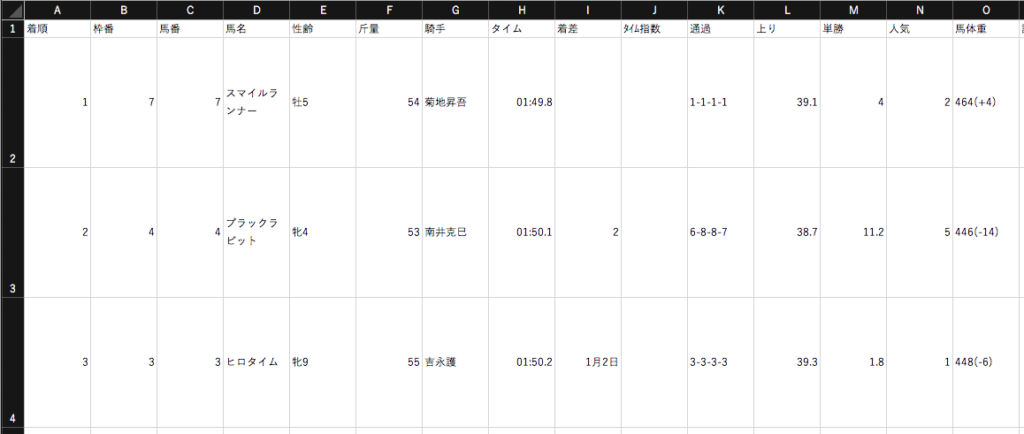
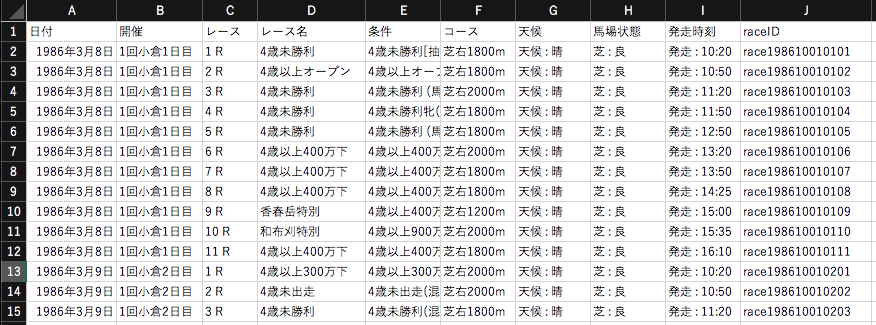
# 1986年から2020年のレースファイルからレース名他を抽出して競馬場毎にまとめる
for year in range(1986,2021):
for f in glob.glob(f'/horse_racing/race/{year}/*/*/*.csv', recursive=True):
file_new = f.split('race/')[0] + 'race_name/' + f.split('race/')[1][:-26] + f'race_n_{year}' + f.split('race/')[1][-26:-24] + '.csv'
with open (f, mode="r", encoding="shift_jis") as f1:
with open(file_new, mode="a", encoding="shift_jis") as f2: # 追記モード
writer = csv.writer(f2)
for i,row in enumerate(csv.reader(f1)):
if i != 0: # 行0の列インデックスは削除
if '010101' == f[-10:-4]: # 1回1日1Rだけ列タイトルを書き込み
if i == 1: # 列タイトル
rows = [e[2:] for e in row[21:30]] + ['raceID']
writer.writerow(rows)
if '年' in row[21]: # 列21に'年'がある行を書き込み
rows = row[21:30] + [f[-20:-4]]
writer.writerow(rows)