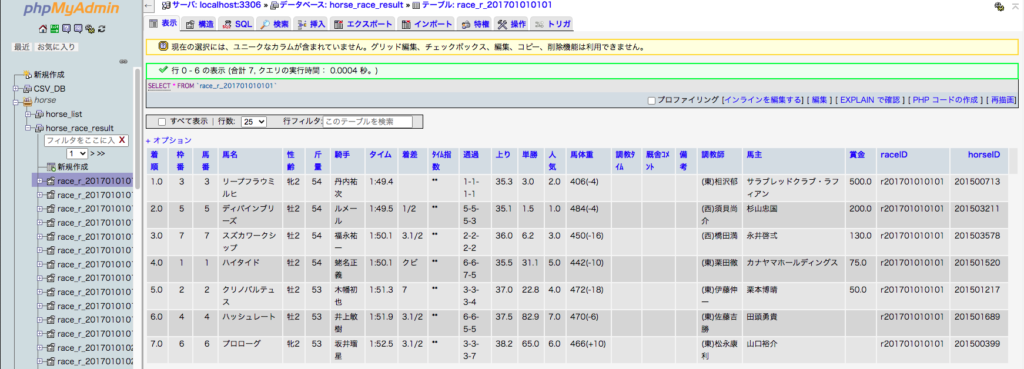
下のコードでは登録外の外国馬が出走するジャパンカップ2走分が漏れてしまいます。レースファイルの馬名IDに’該当なし’が含まれているとおかしくなるようです。これを00000など適当な数字に変えればまともに動くと思います。
import glob,csv,re,datetime,sys
import pandas as pd
print('検索したい馬名を入力してください')
name = input()
horseID_l = list()
for year in range(1986,2019 +1):
namefile = f'/horse_racing/horse_list/horse{year}.csv'
df = pd.read_csv(namefile,encoding="shift_jis")
# 馬名ファイルの馬名と検索馬名が完全一致した場合にTrueとする縦向き配列を作成
b_array = df[df.columns[1]]==name
# ブール値の横向き配列として取り出しリスト化
b_array_v = b_array.values.tolist()
# Trueのインデックス値を算出しhorseIDを取得
try:
i = b_array_v.index(True)
except:
pass
else:
print(f'year {year} index {i}')
horseID = df.iloc[i,0]
horsename = df.iloc[i,1]
horseID_l.append([year,horseID,horsename])
print(f'{name} {horseID_l}')
if len(horseID_l) >= 2:
print('該当する馬が複数います。番号を入力してください。')
for i,data in enumerate(horseID_l):
print(f'{i+1} {data}')
num = input()
id = horseID_l[int(num)-1][1]
year = horseID_l[int(num)-1][0]
elif len(horseID_l) == 0:
print('該当する馬はいません')
sys.exit()
else:
id = horseID_l[0][1]
year = horseID_l[0][0]
print(f'検索馬のID {id} 誕生年 {year}')
raceID_l = list()
start_year = year + 2
print(f'推定デビュー年 {start_year}')
for y in range(start_year,2021 +1):
for f in glob.glob(f'/horse_racing/race_result/{y}/*/*/*.csv'):
df = pd.read_csv(f,encoding="shift_jis")
b_array = df[df.columns[22]]== id
# ブール値の横向き配列として取り出しリスト化
b_array_v = b_array.values.tolist()
# Trueのインデックス値を算出しraceIDを取得
try:
i = b_array_v.index(True)
except:
pass
else:
raceID = df.iloc[i,21]
raceID_l.append(raceID)
print(raceID_l)
race_l = list()
for id in raceID_l:
for y in range(start_year,2021 +1):
for f in glob.glob(f'/horse_racing/race_name/{y}/*.csv'):
df = pd.read_csv(f,encoding="shift_jis")
b_array = df[df.columns[9]]== id
# ブール値の横向き配列として取り出しリスト化
b_array_v = b_array.values.tolist()
# Trueのインデックス値を算出しレース名を取得
try:
i = b_array_v.index(True)
except:
pass
else:
date = df.iloc[i,0]
racename = df.iloc[i,3]
date_d = datetime.datetime.strptime(date,'%Y年%m月%d日')
race_l.append([id,date,racename,date_d])
print(f'出走数 {len(race_l)}')
print(sorted(race_l, key=lambda x: x[3]))
--------------------------------------------------
出力
--------------------------------------------------
検索したい馬名を入力してください
キタサンブラック
year 2012 index 3012
キタサンブラック [[2012, 201202013, 'キタサンブラック']]
検索馬のID 201202013 誕生年 2012
推定デビュー年 2014
['r201505010105', 'r201505010807', 'r201505021210', 'r201506020811', 'r201506030811', 'r201506040511', 'r201506050810', 'r201508040711', 'r201606050910', 'r201608030411', 'r201608040311', 'r201609020411', 'r201609030811', 'r201705040911', 'r201706050811', 'r201708030411', 'r201709020411', 'r201709030811']
出走数 18
[['r201505010105', '2015年1月31日', '3歳新馬', datetime.datetime(2015, 1, 31, 0, 0)], ['r201505010807', '2015年2月22日', '3歳500万下', datetime.datetime(2015, 2, 22, 0, 0)], ['r201506020811', '2015年3月22日', '第64回フジTVスプリングS(G2)', datetime.datetime(2015, 3, 22, 0, 0)], ['r201506030811', '2015年4月19日', '第75回皐月賞(G1)', datetime.datetime(2015, 4, 19, 0, 0)], ['r201505021210', '2015年5月31日', '第82回東京優駿(G1)', datetime.datetime(2015, 5, 31, 0, 0)], ['r201506040511', '2015年9月21日', '第69回朝日セントライト記念(G2)', datetime.datetime(2015, 9, 21, 0, 0)], ['r201508040711', '2015年10月25日', '第76回菊花賞(G1)', datetime.datetime(2015, 10, 25, 0, 0)], ['r201506050810', '2015年12月27日', '第60回有馬記念(G1)', datetime.datetime(2015, 12, 27, 0, 0)], ['r201609020411', '2016年4月3日', '第60回産経大阪杯(G2)', datetime.datetime(2016, 4, 3, 0, 0)], ['r201608030411', '2016年5月1日', '第153回天皇賞(春)(G1)', datetime.datetime(2016, 5, 1, 0, 0)], ['r201609030811', '2016年6月26日', '第57回宝塚記念(G1)', datetime.datetime(2016, 6, 26, 0, 0)], ['r201608040311', '2016年10月10日', '第51回京都大賞典(G2)', datetime.datetime(2016, 10, 10, 0, 0)], ['r201606050910', '2016年12月25日', '第61回有馬記念(G1)', datetime.datetime(2016, 12, 25, 0, 0)], ['r201709020411', '2017年4月2日', '第61回大阪杯(G1)', datetime.datetime(2017, 4, 2, 0, 0)], ['r201708030411', '2017年4月30日', '第155回天皇賞(春)(G1)', datetime.datetime(2017, 4, 30, 0, 0)], ['r201709030811', '2017年6月25日', '第58回宝塚記念(G1)', datetime.datetime(2017, 6, 25, 0, 0)], ['r201705040911', '2017年10月29日', '第156回天皇賞(秋)(G1)', datetime.datetime(2017, 10, 29, 0, 0)], ['r201706050811', '2017年12月24日', '第62回有馬記念(G1)', datetime.datetime(2017, 12, 24, 0, 0)]]