よく使うのでメモ書き。
# url取得時の例外処理および内容出力
try:
driver.get(url)
except Exception as e:
print(e)
break
else:
time.sleep(1)よく使うのでメモ書き。
# url取得時の例外処理および内容出力
try:
driver.get(url)
except Exception as e:
print(e)
break
else:
time.sleep(1)Excelで作成したCSVファイルの先頭にBOM(byte order mark)が付いていたのでこれを削除する方法も併せて以下に記します。
with open(CSVファイルのパス,encoding='utf-8-sig') as f:
reader = csv.reader(f)
l = [row for row in reader]
# ネストになっているため平滑化
keys = [e for ele in l for e in ele]
print(keys)以下のコードでも可能ですが、野暮ったい感じになります。
with open(CSVファイルのパス) as f:
reader = csv.reader(f)
l = [row for row in reader]
keys = [e.replace('\ufeff','') for ele in l for e in ele]
print(keys)ネスト(入れ子)になっていない普通のリストのCSVファイル化です。
ネストになったリストはよくCSV化していましたが、普通のリストは意外と扱っていませんでした。
writerowをwriterowsにすると、文字列が1字ずつバラバラになります。
datetime_now = datetime.datetime.now()
datetime_now_str = datetime_now.strftime('%y%m%d%H%M')
filename = f"/{datetime_now_str}_{key}.csv"
with open(filename, "w", encoding="shift_jis") as f:
writer = csv.writer(f)
writer.writerow(list)ネストになったリストの場合は以下の通りです。
with open(filename, "w", encoding="shift_jis") as f:
writer = csv.writer(f, lineterminator='\n')
writer.writerows(list)知識の整理も兼ねてまとめてみました。
seleniumによるURL取得
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("URL")selenium ヘッドレスモード
from selenium.webdriver.chrome.options import Options
option = Options()
option.add_argument('--headless')
driver = webdriver.Chrome('/usr/local/bin/chromedriver',options=option)selenium 要素をクリック
driver.find_element_by_xpath("XPATH").click()selenium 要素が現れるまで30秒待機
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
WebDriverWait(driver,30).until(EC.presence_of_element_located((By.ID, "ID")))selenium 要素がクリックできるまで30秒待機
WebDriverWait(driver, 30).until(EC.element_to_be_clickable((By.ID, "ID")))selenium 文字列を入力
driver.find_element_by_xpath("XPATH").send_keys("STRING")selenium 要素の文字列を取得
textA = driver.find_element_by_xpath("XPATH").textselenium 他のタブへ移動
handle_array = driver.window_handles
driver.switch_to.window(handle_array[NUMBER])selenium カーソルでホバリング
from selenium.webdriver.common.action_chains import ActionChains
actions = ActionChains(driver)
actions.move_to_element(driver.find_element_by_xpath("XPATH")).perform()久々のスクレイピングネタです。
万能だと思っていた構文解析器 lxmlがそうでもなかったのでメモ書き。
from bs4 import BeautifulSoup
<中略>
# webページのソースコードを取得
html = driver.page_source.encode('utf-8')
# 基本的にはlxmlを使っています
try:
soup = BeautifulSoup(html, "lxml")
# うまくいかない場合はデフォルトのhtml.parserを使ってみる
except:
soup = BeautifulSoup(html, "html.parser")
# 要素を抽出(例)
elements = soup.find_all("td",{"class":"txt_l"})
href_l = [str(e) for e in elements if 'href="/race' in str(e)]pandasの機能の中でも特に使い出があります。
私製競馬DBの検索結果はCSVよりもHTMLの方が断然見やすいです。
CSVをExcelで開くと通過順を日付にしようとする悪癖が出るので、HTMLをデフォルトにしたいです。
クロノジェネシスの検索結果を見て改めて感じたのですが、グランアレグリア、ラヴズオンリーユー、カレンブーケドールなど、2019年クラシック牝馬のレベルはものすごく高いですね。
# リストをデータフレームに変換する
df_index_columns = pd.DataFrame(race_l[1:], columns=race_l[0])
# 結果ファイル名の作成
datetime_now = datetime.datetime.now()
datetime_now_str = datetime_now.strftime('%y%m%d%H%M')
filename = f"/{datetime_now_str}_{name}.csv"
filename_html = f"/{datetime_now_str}_{name}.html"
with open(filename, 'w',encoding = 'shift_jis') as f:
df_index_columns.to_csv(f,index=False)
with open(filename_html, 'w',encoding = 'shift_jis') as f2:
df_index_columns.to_html(f2,index=False)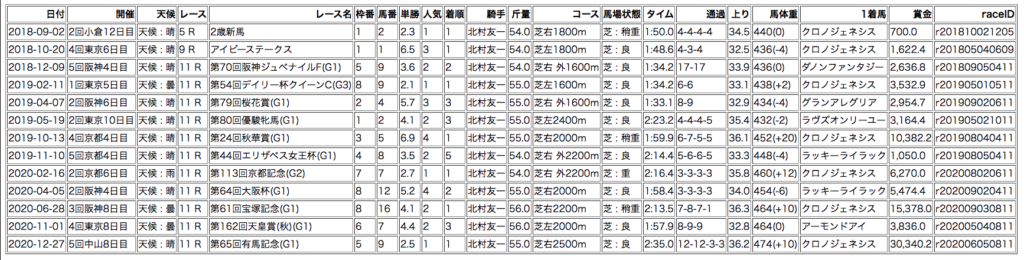
よく使うのでメモ書きしておきます。
import datetime
import locale
today = datetime.date.today()
this_month = today.month
this_year = today.year
print(f'今日 {today})
print(f'今月 {this_month})
print(f'今年 {this_year})
locale.setlocale(locale.LC_TIME, 'ja_JP.UTF-8')
youbi = today.strftime('%a')
print(f'曜日 {youbi}')
--------------------------------------------------
出力
--------------------------------------------------
今日 2021-04-28
今月 4
今年 2021
曜日 水
期間指定でレース検索ができるようになりました。
日付文字列をハイフン付きに変換してWHERE条件式に代入しました。
検索条件は日付だけでなく、距離、競馬場、条件戦なども追加するつもりです。
使っていて感じるのですが、もしかしたらTARGET Frontierよりも断然早いのでは。
今のところ機能面では話にならないものの、検索速度自体はMySQLに分がありそうです。まあ操作している人間は初学者ですが、一応本式のデータベースですから。
TARGET Frontierは久しく使っていないので、期間限定で再契約しノウハウを学びたいです。
<コードの一部を掲載。なお入力値は自作ライブラリmysql_searchにて処理>
# フレームの作成
frameA = FrameA(master=horse)
# IntVarの初期化
var = tk.IntVar()
for i in range(1000):
print(f'var for文先頭 {var.get()}')
children = frameA.winfo_children()
if var.get() == 0 or var.get() == 1:
print('分岐A')
# 馬名の入力を待機
children[2].wait_variable(var)
# 入力した馬名を取得
name = children[1].get()
print(f'name {name}')
if name != '':
# 競走馬成績を検索
mysql_search.Mysql_search().horse_result(name)
else:
print(f'分岐B')
childrenB = frameB.winfo_children()
childrenB2 = frameB2.winfo_children()
childrenB3 = frameB3.winfo_children()
print(f'frameB_info\n{childrenB}\n')
print(f'frameB2_info\n{childrenB2}\n')
print(f'frameB3_info\n{childrenB3}\n')
# レース名の入力を待機
childrenB[1].wait_variable(var)
# 入力したレース名を取得
race = childrenB[1].get()
start = childrenB2[0].get()
if start == '':
start = '860101'
end = childrenB3[0].get()
if end == '':
end = (datetime.date.today()).strftime("%y%m%d")
print(f'race {race}')
print(f'開始日 {start}')
print(f'終了日 {end}')
if race != '':
# レース結果を検索
mysql_search.Mysql_search().race_result(race,start,end)
frame.mainloop()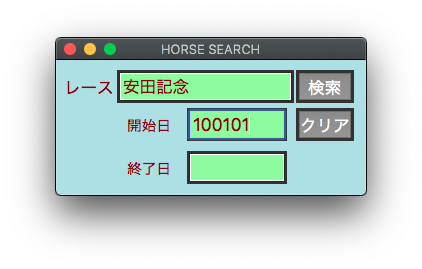
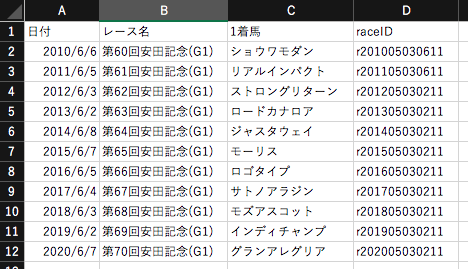
Y年m月d日と表記された文字列はそのままではdate型として取り込めないため、YYYY-mm-dd表記に変換する必要があります。
<前後は省略>
for file,table,sql in zip(file_l,table_l,sql_l):
try:
cur.execute(sql)
except:
pass
else:
cur.execute('BEGIN')
# CSVファイルを読み込み、各行をtableに挿入する
with open(file, 'rt', encoding='Shift-JIS') as f:
reader = csv.reader(f)
for i,row in enumerate(reader):
print(f'row {row}')
if i != 0:
# 年月日の文字列からdatetimeに変換
row_str_date_pre = datetime.datetime.strptime(str(row[0]),\
'%Y年%m月%d日')
# datetimeからハイフン入り年月日の文字列に変換
row_str_date = row_str_date_pre.strftime("%Y-%m-%d")
# 日付とその他を結合してタプルにする
row_str = tuple([row_str_date] + row[1:])
sql = f'INSERT INTO horse_race_name.{table} VALUES {row_str}'
cur.execute(sql)
cur.execute('COMMIT')
前回の記事ではSELECT文で作成したテーブルをデータフレームにして加工し、またテーブルに戻しました。しかし、この方法ではデータ型が全てtextになってしまいました。
そこでテーブルのまま加工してからデータ全てを置き換える方法でやってみました。
できることはできましたがかなり難航しました。結構泥臭い内容です。
import glob,mysql.connector
<接続設定は省略>
# 対象ファイルパスのリストを作成
file_l = [path for path in glob.glob('/horse_racing/race_name/*/*.csv')]
# ファイルパスから拡張子なしのファイル名を抽出
table_l = [path[-17:-4] for path in file_l]
print(table_l)
# mysqlに接続
con = mysql.connector.connect(**config)
cur = con.cursor()
# データベースhorse_race_nameとhorse_race_winnerを結合して不要な列を削除した一時
# テーブルhorse_race_name.tmpを作成し元のテーブルに上書きする
for table in table_l:
cur.execute('BEGIN')
year = table[-6:-2]
sql = f'CREATE TEMPORARY TABLE horse_race_name.tmp SELECT 日付,開催,レース,\
レース名,条件,コース,天候,馬場状態,発走時刻,horse_race_winner.{year}_1着馬リスト.\
1着馬,horse_race_name.{table}.raceID FROM horse_race_name.{table} \
INNER JOIN horse_race_winner.{year}_1着馬リスト \
ON horse_race_name.{table}.raceID = horse_race_winner.{year}_1着馬リスト.\
raceID'
cur.execute(sql)
cur.execute(f'DROP TABLE horse_race_name.{table}')
cur.execute(f'CREATE TABLE horse_race_name.{table} LIKE horse_race_name.tmp')
cur.execute(f'INSERT INTO horse_race_name.{table} SELECT * from horse_race_name.tmp')
cur.execute('DROP TABLE horse_race_name.tmp')
cur.execute('COMMIT')
con.close()