[macOS Catalina 10.15.7]
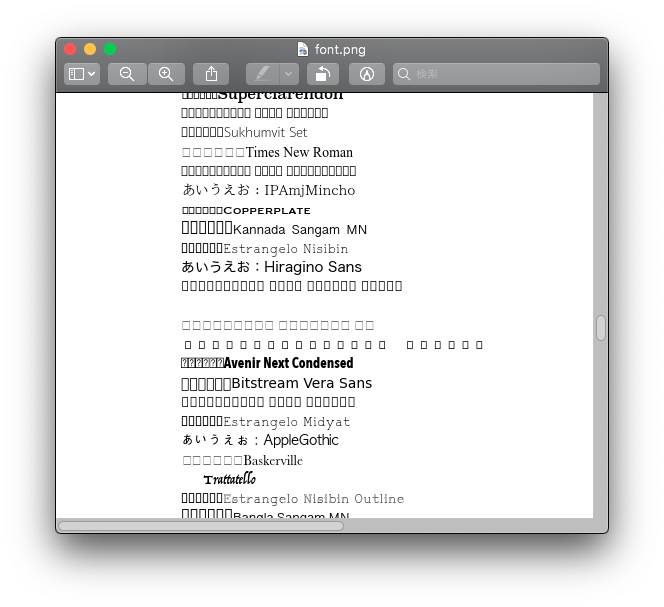
Macに入っている日本語フォント名を抽出するコードを書きました。平仮名の”あ”に該当するグリフ(字体)の有無で判定しています。私の環境には24種類以上あることが分かりました。
ttcファイルおよびotfファイルについては中に入っている最初のフォントを判定しています。
Last Resort Fontというフォールバック用フォントの存在を初めて知りました。
from fontTools import ttLib
from pathlib import Path
import glob
import pprint
HOME = Path.home()
print(str(HOME))
OSXFontDirectories = [
"/Library/Fonts/",
"/Network/Library/Fonts/",
"/System/Library/Fonts/",
"/opt/local/share/fonts/",
str(HOME / "Library/Fonts/"),
]
font_paths = list()
for dir in OSXFontDirectories:
paths_ttf = glob.glob(dir + "*.ttf")
paths_ttc = glob.glob(dir + "*.ttc")
paths_otf = glob.glob(dir + "*.otf")
paths = paths_ttf + paths_ttc + paths_otf
for path in paths:
font_paths.append(path)
list_jfont = {}
for path in font_paths:
font = ttLib.TTFont(path, fontNumber=0)
cmap = font["cmap"]
fontfile = path.split('/')[-1]
for uni, id in cmap.getBestCmap().items():
if uni == 12354:
list_jfont.update({fontfile:id})
pprint.pprint(list_jfont)
print(len(list_jfont))
--------------------------------------------------
出力
--------------------------------------------------
{'AppleSDGothicNeo.ttc': 'cid00852',
'AquaKana.ttc': '.notdef#16152',
'Arial Unicode.ttf': 'uni3042',
'BIZ-UDGothicB.ttc': 'uni3042',
'BIZ-UDGothicR.ttc': 'uni3042',
'BIZ-UDMinchoM.ttc': 'uni3042',
'Hiragino Sans GB.ttc': 'cid00357',
'LastResort.otf': 'lastresorttemplate',
'PingFang.ttc': 'cid00856',
'STHeiti Light.ttc': 'uni3042',
'STHeiti Medium.ttc': 'uni3042',
'ipamjm.ttf': 'aj843',
'ヒラギノ丸ゴ ProN W4.ttc': 'cid00843',
'ヒラギノ明朝 ProN.ttc': 'cid00843',
'ヒラギノ角ゴシック W0.ttc': 'cid00843',
'ヒラギノ角ゴシック W1.ttc': 'cid00843',
'ヒラギノ角ゴシック W2.ttc': 'cid00843',
'ヒラギノ角ゴシック W3.ttc': 'cid00843',
'ヒラギノ角ゴシック W4.ttc': 'cid00843',
'ヒラギノ角ゴシック W5.ttc': 'cid00843',
'ヒラギノ角ゴシック W6.ttc': 'cid00843',
'ヒラギノ角ゴシック W7.ttc': 'cid00843',
'ヒラギノ角ゴシック W8.ttc': 'cid00843',
'ヒラギノ角ゴシック W9.ttc': 'cid00843'}
24