メモ書き。
import time,datetime
start = time.time()
<処理>
# 処理時間算出(秒)
process_time = time.time() - start
td = datetime.timedelta(seconds = process_time).total_seconds()
# 小数点第2位まで表示
td_2f = f'{td:.2f}'メモ書き。
import time,datetime
start = time.time()
<処理>
# 処理時間算出(秒)
process_time = time.time() - start
td = datetime.timedelta(seconds = process_time).total_seconds()
# 小数点第2位まで表示
td_2f = f'{td:.2f}'メモ書き。
num = 123.456
print(f'{num:.1f}')
print(f'{num:.06f}')
--------------------------------------------------
出力
--------------------------------------------------
123.5
123.456000前回の続きです。
htmlファイル内のtableを2次元リストを経て直接データフレームに変換する方法に書き直しました。CSVファイルを作成しない分、スマートかと思います。
# 代替スクリプト改良版
# 文字コードをUTF-8に変換してソース取り込み
html = driver.page_source.encode('utf-8')
# BeautifulSoupでデータ抽出
soup = BeautifulSoup(html, "html.parser")
# soupから3番目のtableを抽出
table = soup.find_all("table",attrs={"cellspacing" : "1"})[2]
rows = table.findAll("tr")
list_rows = []
for row in rows:
list_row = []
for cell in row.findAll(['td', 'th']):
text = cell.get_text()
text2 = text.replace('"','').replace("\n","").replace(" ","").replace(" ","")
list_row.append(text2)
list_rows.append(list_row)
# 2次元リストをヘッダとデータに分割
header = list_rows[0]
data = list_rows[1:]
# データフレームに変換
df = pd.DataFrame(data,columns = header)今のところM1 Macにおいてpipコマンドだけでライブラリを揃える場合、lxmlをインストールできないためpandas.read_htmlを使うケースでは代替スクリプトを考える必要があります。
私のスクリプトは以下のように書き換えました。tableを一旦CSVファイルにしてからデータフレームとして読み込んでいます。まどろっこしいですが仕方ないです。
# 代替スクリプト
# 文字コードをUTF-8に変換してソース取り込み
html = driver.page_source.encode('utf-8')
# BeautifulSoupでデータ抽出
soup = BeautifulSoup(html, "html.parser")
# soupから3番目のtableを抽出
table = soup.find_all("table",attrs={"cellspacing" : "1"})[2]
rows = table.findAll("tr")
filename = "table.csv"
with open(filename, "w", encoding='utf-8') as file:
writer = csv.writer(file)
for row in rows:
csvRow = []
for cell in row.findAll(['td', 'th']):
text = cell.get_text()
text2 = text.replace('"','').replace("\n","").replace(" ","").replace(" ","")
csvRow.append(text2)
writer.writerow(csvRow)
# CSVファイルをデータフレームに変換
df = pd.read_csv(filename)# 旧スクリプト
# 文字コードをUTF-8に変換してソース取り込み
html = driver.page_source.encode('utf-8')
# BeautifulSoupでデータ抽出
soup = BeautifulSoup(html, "html.parser")
# soupから3番目のtableを抽出
table_data = soup.find_all("table",attrs={"cellspacing" : "1"})
df_stock_specific = pd.read_html(str(table_data), header=0)[2]
labels_specific = ['A','B','C','D','E']
df_stock_specific2 = df_stock_specific.reindex(labels_specific, axis=1)globalsおよびlocalsメソッドで変数を辞書型データで取得できます。localsメソッドは関数外で使用するとglobalsメソッドと同じ内容になります。
for文で全local変数がどう変化していくかなど、より詳細なデバッグに使えそうです。
from pprint import pprint
def function():
a = 1
b = 100
c = "Python"
for i in range(10):
print(i)
print(locals())
pprint(locals())
pprint(globals())
pprint(globals()['__file__'])
function()
--------------------------------------------------
出力
--------------------------------------------------
0
{'a': 1, 'b': 100, 'c': 'Python', 'i': 0}
1
{'a': 1, 'b': 100, 'c': 'Python', 'i': 1}
2
{'a': 1, 'b': 100, 'c': 'Python', 'i': 2}
3
{'a': 1, 'b': 100, 'c': 'Python', 'i': 3}
4
{'a': 1, 'b': 100, 'c': 'Python', 'i': 4}
5
{'a': 1, 'b': 100, 'c': 'Python', 'i': 5}
6
{'a': 1, 'b': 100, 'c': 'Python', 'i': 6}
7
{'a': 1, 'b': 100, 'c': 'Python', 'i': 7}
8
{'a': 1, 'b': 100, 'c': 'Python', 'i': 8}
9
{'a': 1, 'b': 100, 'c': 'Python', 'i': 9}
{'a': 1, 'b': 100, 'c': 'Python', 'i': 9}
{'__annotations__': {},
'__builtins__': <module 'builtins' (built-in)>,
'__cached__': None,
'__doc__': None,
'__file__': 'var_test.py',
'__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x104508ca0>,
'__name__': '__main__',
'__package__': None,
'__spec__': None,
'function': <function function at 0x104551f70>,
'pprint': <module 'pprint' from '/Users/[ユーザー名]/.pyenv/versions/3.9.7/lib/python3.9/pprint.py'>}
'var_test.py'PyPIのpandasはようやくM1 Macに対応しましたが、関連するライブラリであるlxmlは2021年11月6日現在、未対応です。lxmlはpandas.read_htmlを使う際に必要になります。
そのためBeautifulSoupで取り込んだデータからの抽出ができません。pandasでhtmlを扱わないようコードを書き換える必要があります。なおminiforge環境ではcondaコマンドでインストール可能です。
今回はpyenvにminiforgeの仮想環境を作成し、そこにcondaでlxml等をインストールしました。crontabによりpythonスクリプトを定時実行する場合はシェルスクリプトファイルに以下のように記述しています。pyenvでなくても直接homeディレクトリにminiforgeをインストールして問題ないでしょう。
# pyenv内miniforge環境 miniforge3-4.10.1-5の場合
/Users/[ユーザー名]/.pyenv/versions/miniforge3-4.10.1-5/bin/python [pyファイルのフルパス]
# miniforge内仮想環境 mini_3.10.0の場合
/Users/[ユーザー名]/miniforge3/envs/mini_3.10.0/bin/python [pyファイルのフルパス]どうもpandas関連の開発元はAppleに対してあまり協力的ではないようです。同様に配列を扱うライブラリであるnumpyは2021年6月には対応していて比較的親Appleです。
私自身、使い勝手の良いpandasに依存している状況は良くないと感じています。昨年11月、M1 Macを早々に手放した原因にもなりましたから。今後のことを考え、numpyをメインに据えて今使っているコードを書き換えられないか模索してみます。
自作モジュール内で実行スクリプト名により条件分岐するif文を作ってみました。
os.path.basename(__file__)を使っています。
from my_library import moduleA
from os
# 実行スクリプト名の取得
source_file = str(os.path.basename(__file__))
print(f"source_file: {source_file}")
# moduleAに実行スクリプト名を渡す
moduleA.main(source_file)
--------------------------------------------------
出力
--------------------------------------------------
source_file: test.py# 自作モジュールの一例
def main(file):
if "test" in file:
profit = ws.cell(column=5,row=maxrow -1).value
else:
profit = ws.cell(column=5,row=maxrow).value以前Homebrew編を書きましたが、pipでもchromedriverをインストール可能です。
PyPIは誰でも登録可能で有志の方がアップしてくれているようです。ざっと探したところchromedriver-pyとchromedriver-binaryが見つかりました。
ただ仮想環境ごとにインストールしなければならず、pyenvユーザーには面倒かつ使い道が少ないように思います。Chromeをバージョンで使い分けるケースがあれば便利でしょう。
pip install chromedriver-py==95.0.4638.17
# インストール先(pyenvの場合)
/Users/[ユーザ名]/.pyenv/versions/3.9.7/lib/python3.9/site-packages/chromedriver_py/chromedriver_mac64
# インストール可能なバージョン確認(わざとエラーにする方法)
pip install chromedriver-py==
--------------------------------------------------
出力
--------------------------------------------------
ERROR: Could not find a version that satisfies the requirement chromedriver-py== (from versions: 2.38, 2.45.2, 2.45.3, 2.46, 78.0.3904.11, 78.0.3904.70, 79.0.3945.16, 79.0.3945.36, 80.0.3987.16, 81.0.4044.20, 81.0.4044.69, 83.0.4103.14, 83.0.4103.39, 84.0.4147.30, 85.0.4183.38, 85.0.4183.83, 85.0.4183.87, 86.0.4240.22, 87.0.4280.20, 87.0.4280.88, 88.0.4324.27, 88.0.4324.96, 89.0.4389.23, 90.0.4430.24, 91.0.4472.19, 92.0.4515.43, 92.0.4515.107, 93.0.4577.15, 93.0.4577.63, 94.0.4606.41, 95.0.4638.10, 95.0.4638.17)[macOS Monterey 12.0.1]
これまでM1 Macにpipでpandasをインストールしようとしてもエラーになり、Miniforge環境でしかインストールできない状況が続いていました。
ようやくpandas開発元が昨日2021年10月30日にpandas1.3.4のM1 Mac用whlファイルをアップしてくれました。Python3.10にインストールできます。
以下に手順を書いておきます。
1. PyPIサイトから以下のwhlファイルをダウンロードする。
pandas-1.3.4-cp310-cp310-macosx_11_0_arm64.whl (10.3 MB)
2. pipコマンドでインストールする。
ファイルへのアクセスが拒否される場合はシステム環境設定でアクセスを許可するか、ファイルを適当な所に移動させてください。前者の場合、”セキュリティとプライバシー”でターミナルがダウンロードフォルダにアクセスできるようにします。
pip install pandas-1.3.4-cp310-cp310-macosx_11_0_arm64.whl
--------------------------------------------------
出力
--------------------------------------------------
Successfully installed numpy-1.21.3 pandas-1.3.4 python-dateutil-2.8.2 pytz-2021.3 six-1.16.0whlファイルをダウンロードせずにいきなりpip install pandasを実行するとソースコードのtarファイルをダウンロードしますが、必ずビルドに失敗します。
昨年M1 MacBook Airを購入した際、pandasがどうしてもインストールできず、Rosetta2のもっさり感も気になってやむなく返品しました。11ヶ月後に今度はM1 Mac miniを購入して、相変わらずpandasがpipでインストールできずにがっかりしたんですが、3日後にwhlファイルがリリースされ本当に感謝の一言です。これでpyenvでの開発環境をM1 Macでも再現できそうです。
matplotlibを使ってCSVから複数系列の棒グラフを作成しました。
df.plotからplt.suptitleへの流れに唐突感がありますが、pandasからmatplotlibへグラフデータがしっかり引き継がれています。
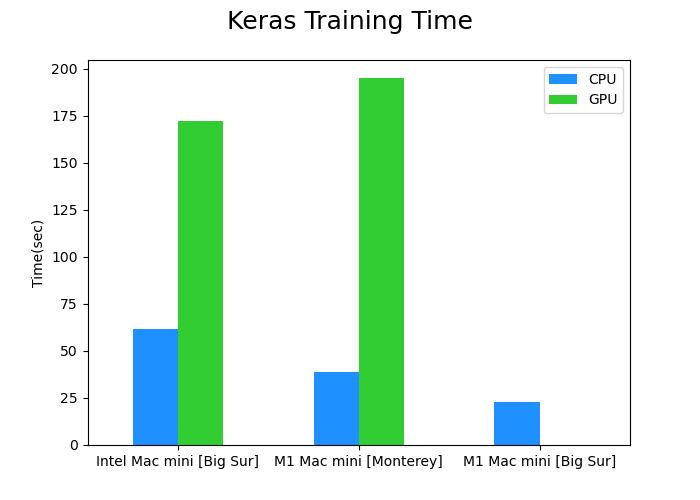
import pandas as pd
import matplotlib.pyplot as plt
import datetime
df = pd.read_csv('tensorflow_macos_graph.csv',index_col=0,encoding = 'UTF8')
color_list = ['#1e90ff','#32cd32']
df.plot(kind='bar',color = color_list,figsize = (7,5),ylabel = 'Time(sec)',rot=0)
plt.suptitle('Keras Training Time', fontsize=18)
dt_now = datetime.datetime.now()
dt_now_str = dt_now.strftime('%y%m%d%H%M')
image ='{}_tensorflow_macos.png'.format(dt_now_str)
plt.savefig(image)
plt.show(),CPU,GPU
Intel Mac mini [Big Sur],61.5,172.1
M1 Mac mini [Monterey],39,194.9
M1 Mac mini [Big Sur],23.1,0