#include "cppstd.h" // 自製ライブラリ
#include "FLstd.h" // 自製ライブラリ
#include <WidgetTable.h>
extern vector<tuple<string, string, string, string>> numTitlePostnumID;
extern string id, num, title, postnum;
WidgetTable::WidgetTable(int x, int y, int w, int h, const char *l) : Fl_Table(x,y,w,h,l){
col_header(1);
col_resize(1);
col_header_height(25);
// row_header(1);
row_resize(1);
row_header_width(80);
end();
}
WidgetTable::~WidgetTable(){}
void WidgetTable::SetSize(int newrows, int newcols) {
clear(); // clear any previous widgets, if any
rows(newrows);
cols(newcols);
col_width(0, 50);
col_width(1, 1160-50-50-100);
col_width(2, 50);
col_width(3, 100);
begin(); // start adding widgets to group
{
for ( int r = 0; r<newrows; r++ ) {
for ( int c = 0; c<newcols; c++ ) {
int X,Y,W,H;
find_cell(CONTEXT_TABLE, r, c, X, Y, W, H);
// switch文でも可
if (c == 0) {
char s[20];
num = get<0>(numTitlePostnumID[r]);
sprintf(s, "%s", num.c_str());
Fl_Input *in = new Fl_Input(X,Y,W,H);
in->value(s);
} else if(c == 1) {
char s[200];
title = get<1>(numTitlePostnumID[r]);
sprintf(s, "%s", title.c_str());
Fl_Input *in = new Fl_Input(X,Y,W,H);
in->value(s);
} else if(c == 2){
char s[20];
postnum = get<2>(numTitlePostnumID[r]);
sprintf(s, "%s", postnum.c_str());
Fl_Input *in = new Fl_Input(X,Y,W,H);
in->value(s);
} else if (c == 3){
char s[20];
id = get<3>(numTitlePostnumID[r]);
sprintf(s, "%s", id.c_str());
Fl_Input *in = new Fl_Input(X,Y,W,H);
in->value(s);
}
}
}
}
end();
}
void WidgetTable::draw_cell(TableContext context,
int R, int C, int X, int Y, int W, int H) {
switch ( context ) {
case CONTEXT_STARTPAGE:
fl_font(FL_HELVETICA, 12); // font used by all headers
break;
case CONTEXT_RC_RESIZE: {
int X, Y, W, H;
int index = 0;
for ( int r = 0; r<rows(); r++ ) {
for ( int c = 0; c<cols(); c++ ) {
if ( index >= children() ) break;
find_cell(CONTEXT_TABLE, r, c, X, Y, W, H);
child(index++)->resize(X,Y,W,H);
}
}
init_sizes(); // tell group children resized
return;
}
case CONTEXT_ROW_HEADER:
fl_push_clip(X, Y, W, H);
{
static char s[40];
sprintf(s, "Row %d", R);
fl_draw_box(FL_THIN_UP_BOX, X, Y, W, H, row_header_color());
fl_color(FL_BLACK);
fl_draw(s, X, Y, W, H, FL_ALIGN_CENTER);
}
fl_pop_clip();
return;
case CONTEXT_COL_HEADER:
fl_push_clip(X, Y, W, H);
{
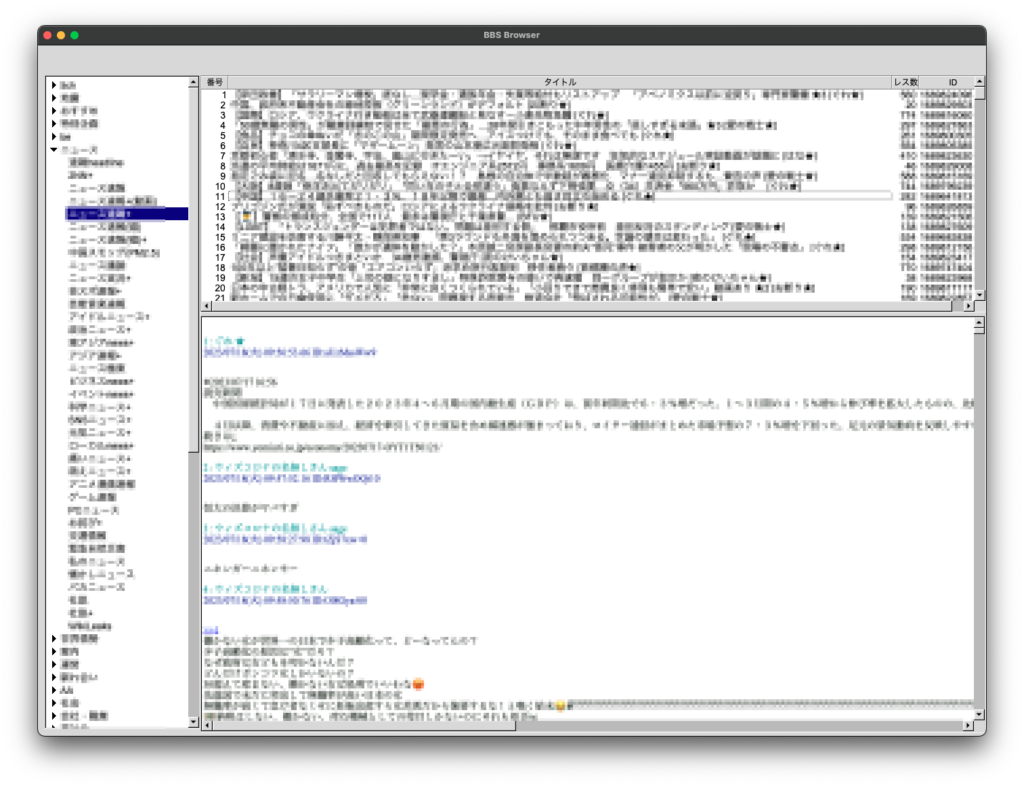
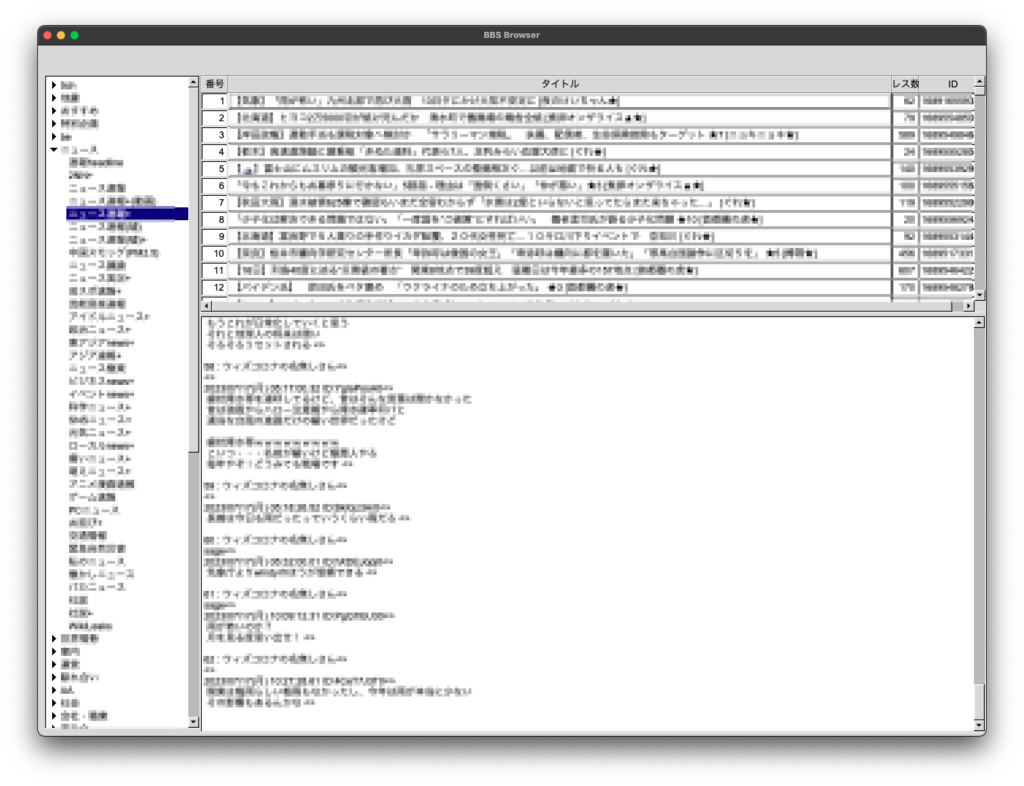
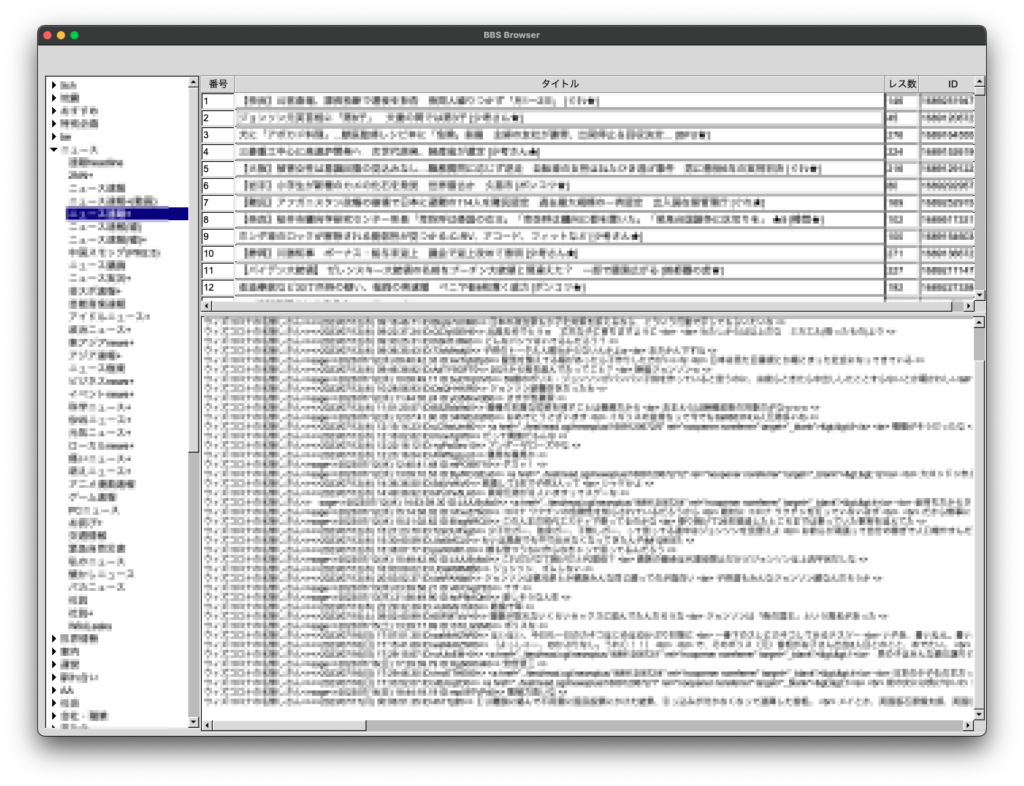
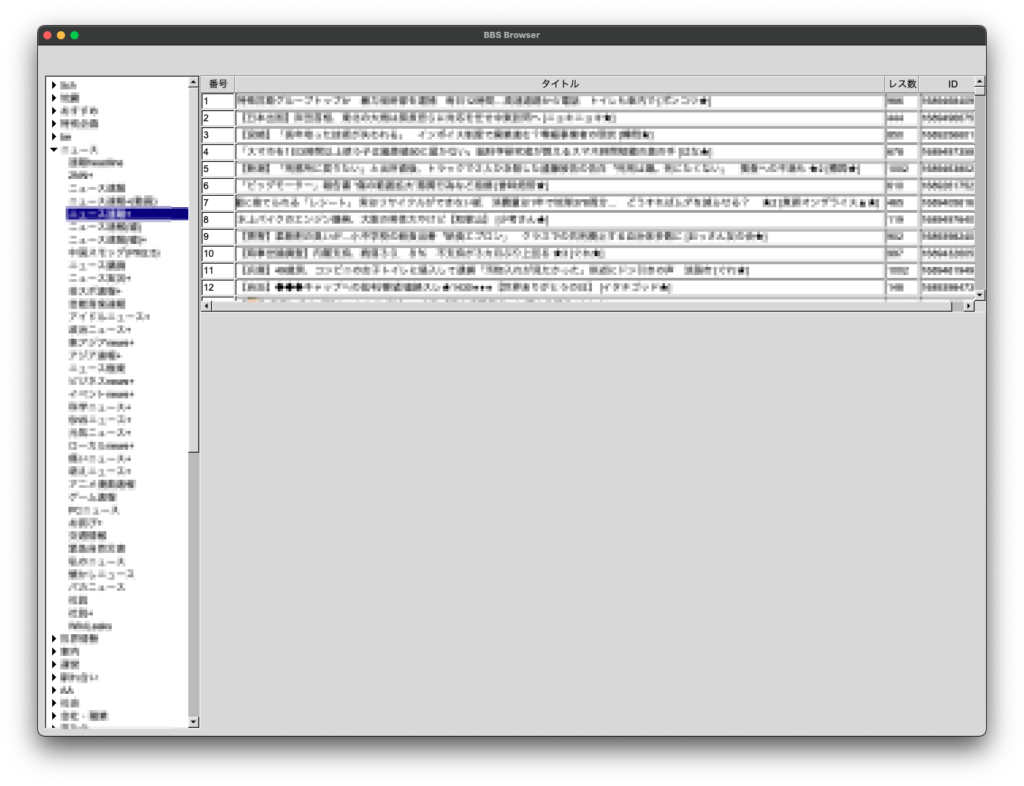
if (C == 0){
static char s[40];
sprintf(s, "番号");
fl_draw_box(FL_THIN_UP_BOX, X, Y, W, H, col_header_color());
fl_color(FL_BLACK);
fl_draw(s, X, Y, W, H, FL_ALIGN_CENTER);
} else if (C == 1){
static char s[40];
sprintf(s, "タイトル");
fl_draw_box(FL_THIN_UP_BOX, X, Y, W, H, col_header_color());
fl_color(FL_BLACK);
fl_draw(s, X, Y, W, H, FL_ALIGN_CENTER);
} else if (C == 2){
static char s[40];
sprintf(s, "レス数");
fl_draw_box(FL_THIN_UP_BOX, X, Y, W, H, col_header_color());
fl_color(FL_BLACK);
fl_draw(s, X, Y, W, H, FL_ALIGN_CENTER);
} else if (C == 3){
static char s[40];
sprintf(s, "ID");
fl_draw_box(FL_THIN_UP_BOX, X, Y, W, H, col_header_color());
fl_color(FL_BLACK);
fl_draw(s, X, Y, W, H, FL_ALIGN_CENTER);
}
}
fl_pop_clip();
return;
case CONTEXT_CELL:
return; // fltk handles drawing the widgets
default:
return;
}
}