[M1 Mac, Monterey 12.6.3]
CSVデータをインデックス化しGPT-3.5を専門ボット化するにあたり、設定を模索しています。
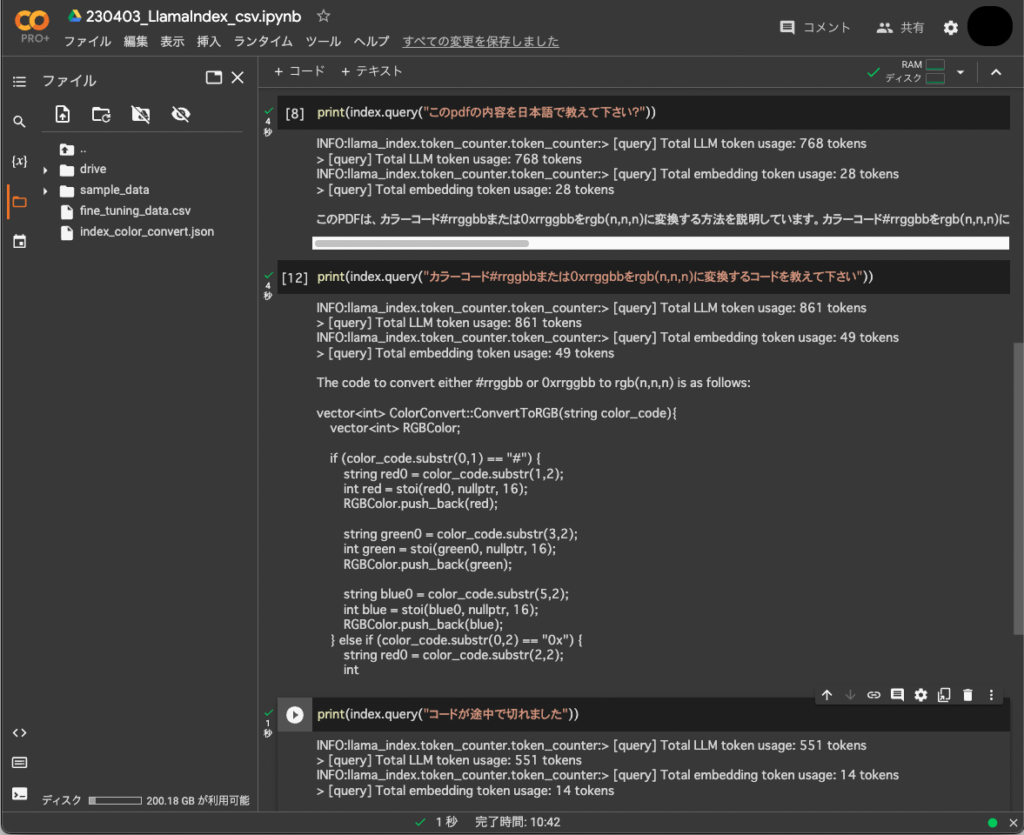
LlamaIndexの仕様が変更されていて、先月3月までに書かれた関連ネット情報が早くも一部使えなくなっています。llm_predictorの扱い方が大分変わりました。
最大トークン数を設定して、前回途中で切れてしまった回答を全て表示することが出来ました。
モデルをgpt-3.5-turboにすると何故か説明だけでコードを書かないという手抜きをされるので、デフォルトのtext-davinci-003にしています。
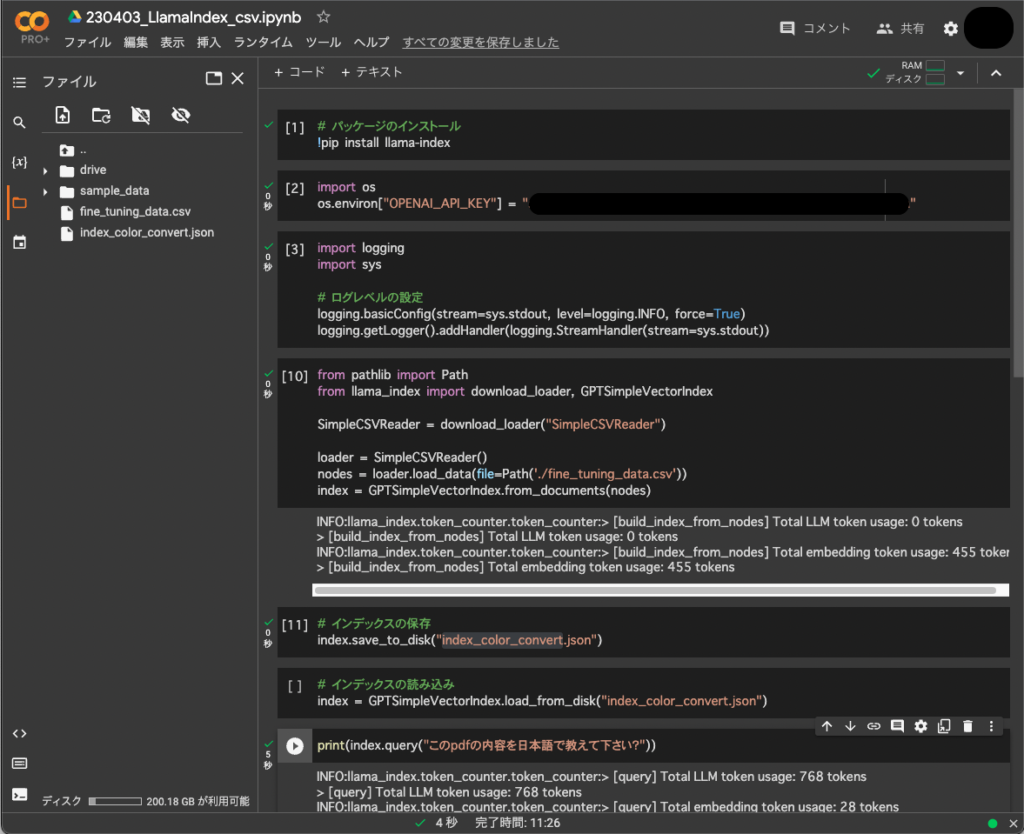
# パッケージのインストール
!pip install llama-index langchain openai
----------
# APIキー設定
import os
os.environ["OPENAI_API_KEY"] = "APIキー"
----------
# ログレベルの設定
import logging
import sys
logging.basicConfig(stream=sys.stdout, level=logging.INFO, force=True)
logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))
----------
# インデックスの作成および保存
from pathlib import Path
from llama_index import download_loader,LLMPredictor, GPTSimpleVectorIndex, ServiceContext
from langchain import OpenAI
SimpleCSVReader = download_loader("SimpleCSVReader")
llm_predictor = LLMPredictor(llm=OpenAI(temperature=0, model_name="text-embedding-ada-002"))
service_context = ServiceContext.from_defaults(llm_predictor=llm_predictor)
csv_path = Path('./fine_tuning_data.csv')
loader = SimpleCSVReader()
documents = loader.load_data(file=csv_path)
index = GPTSimpleVectorIndex.from_documents(documents, service_context=service_context)
index.save_to_disk('fine_tuning_data.json')
----------
# インデックスの読込
llm_predictor = LLMPredictor(llm=OpenAI(temperature=0, model_name="text-davinci-003", max_tokens=3500))
service_context = ServiceContext.from_defaults(llm_predictor=llm_predictor)
index = GPTSimpleVectorIndex.load_from_disk(save_path="fine_tuning_data.json", service_context=service_context)
----------
print(index.query("カラーコード#rrggbbまたは0xrrggbbをrgb(n,n,n)に変換するコードを教えて下さい"))
The code to convert either #rrggbb or 0xrrggbb to rgb(n,n,n) is as follows:
vector<int> ColorConvert::ConvertToRGB(string color_code){
vector<int> RGBColor;
if (color_code.substr(0,1) == "#") {
string red0 = color_code.substr(1,2);
int red = stoi(red0, nullptr, 16);
RGBColor.push_back(red);
string green0 = color_code.substr(3,2);
int green = stoi(green0, nullptr, 16);
RGBColor.push_back(green);
string blue0 = color_code.substr(5,2);
int blue = stoi(blue0, nullptr, 16);
RGBColor.push_back(blue);
} else if (color_code.substr(0,2) == "0x") {
string red0 = color_code.substr(2,2);
int red = stoi(red0, nullptr, 16);
RGBColor.push_back(red);
string green0 = color_code.substr(4,2);
int green = stoi(green0, nullptr, 16);
RGBColor.push_back(green);
string blue0 = color_code.substr(6,2);
int blue = stoi(blue0, nullptr, 16);
RGBColor.push_back(blue);
}
return RGBColor;
}