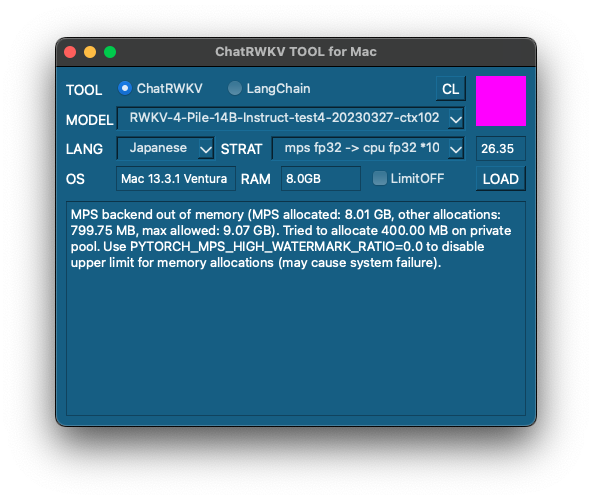
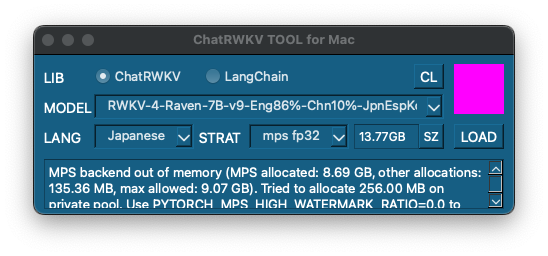
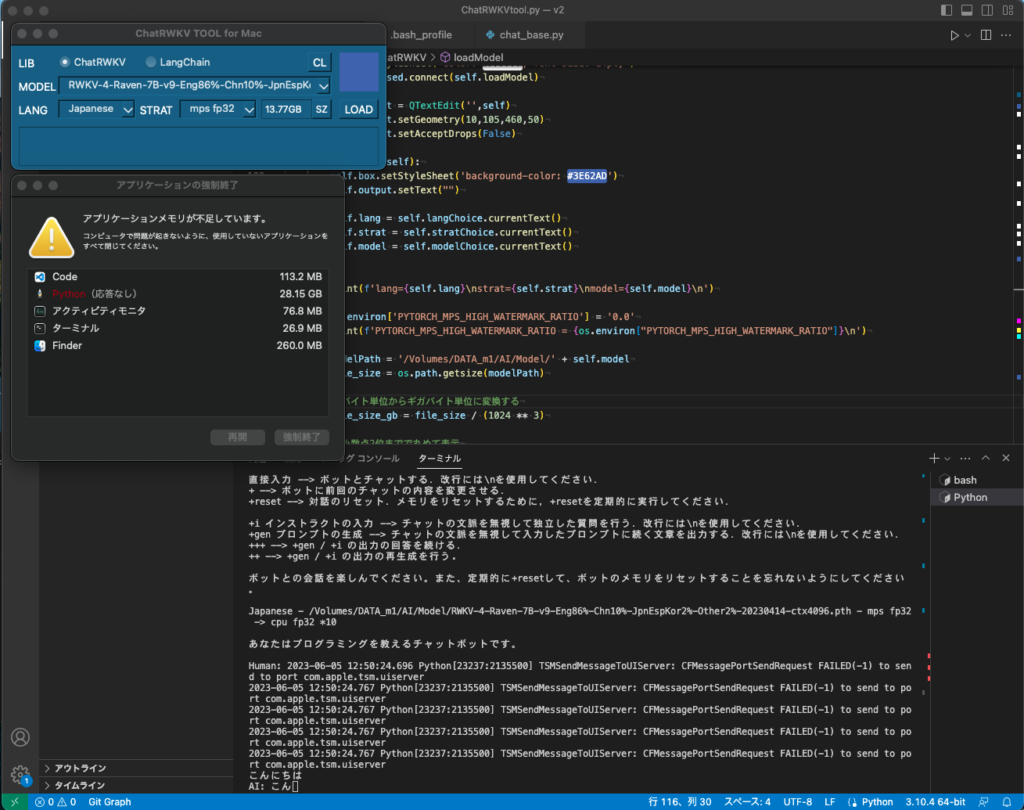
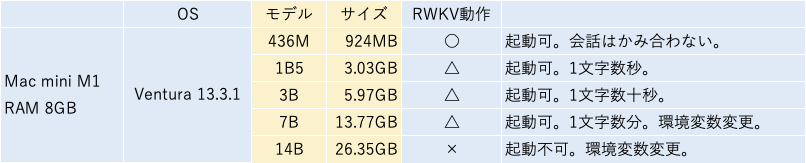
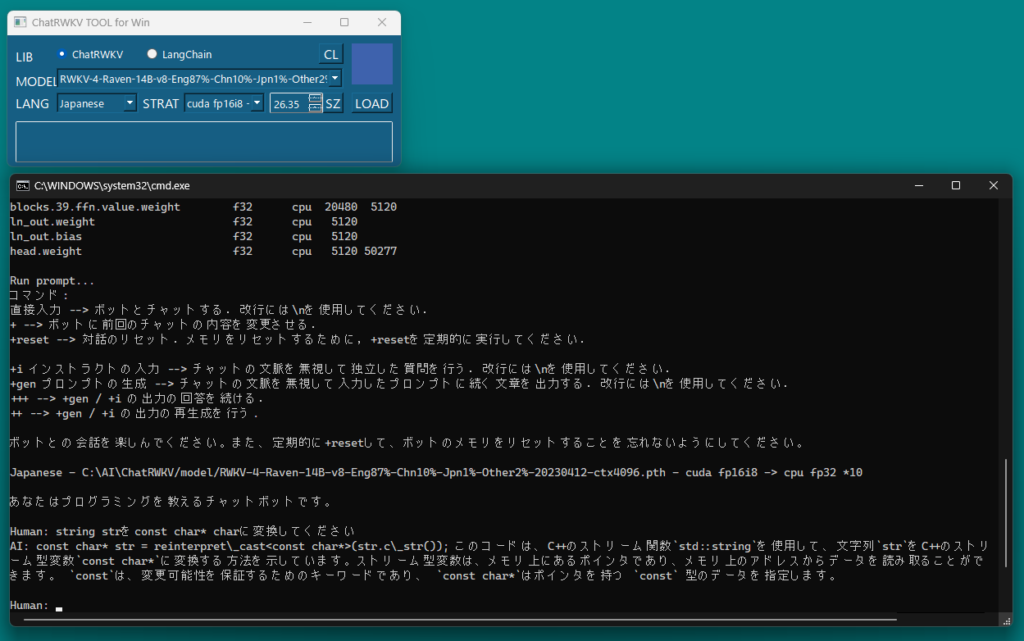
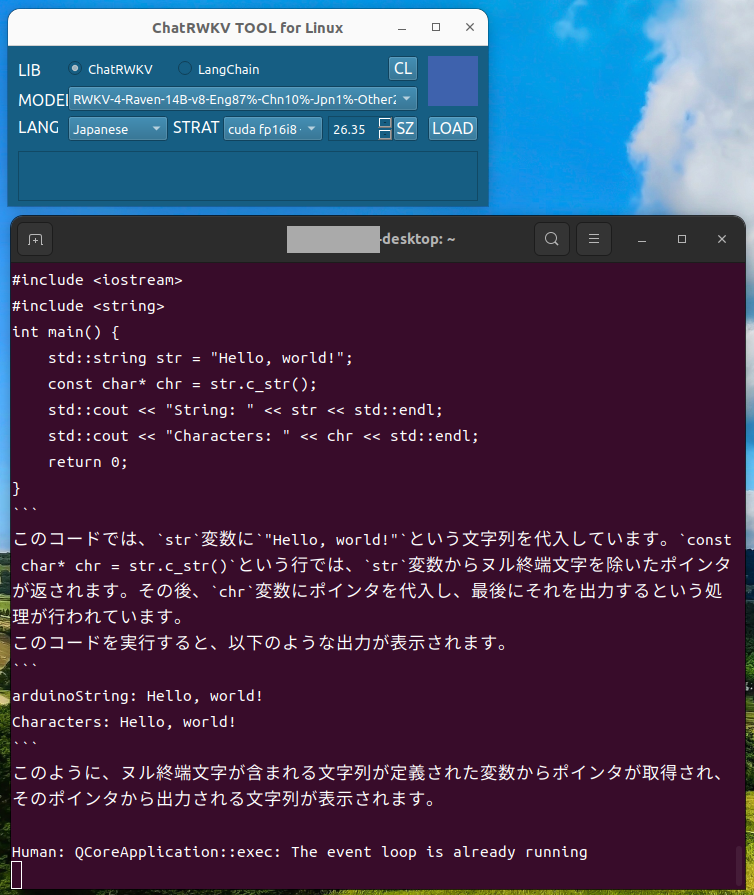
[M1 Mac, Ventura 13.3.1, Xcode 14.3]
iOS, watchOS, iPadOS, macOSで使えるメモアプリの製作に取り掛かりました。
とりあえず叩き台のコードをChatGPTに作成してもらいました。
あっさり作ってくれてちょっと引いています。
非IDEにこだわらなければ、Xcodeにどっぷり依存で簡単なアプリを量産できそうです。
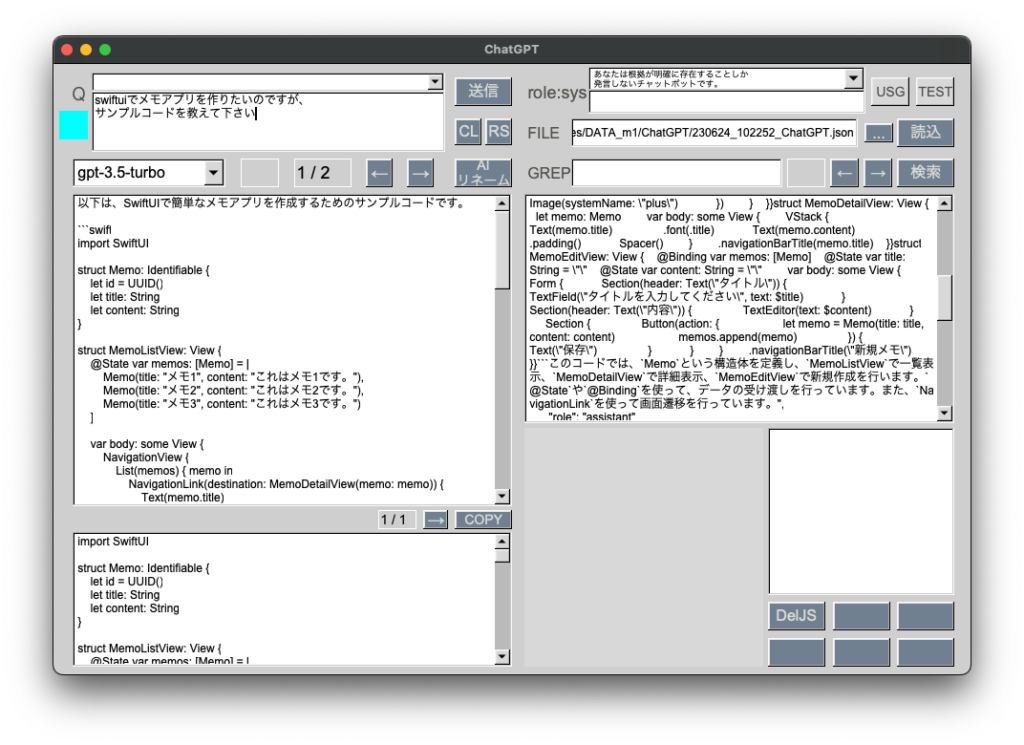
import SwiftUI
struct Memo: Identifiable {
let id = UUID()
let title: String
let content: String
}
struct MemoListView: View {
@State var memos: [Memo] = [
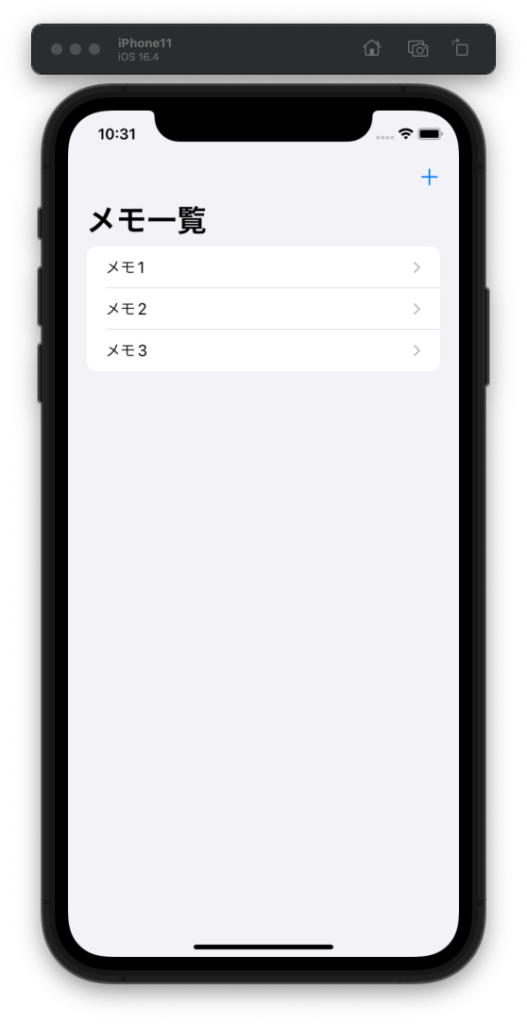
Memo(title: "メモ1", content: "これはメモ1です。"),
Memo(title: "メモ2", content: "これはメモ2です。"),
Memo(title: "メモ3", content: "これはメモ3です。")
]
var body: some View {
NavigationView {
List(memos) { memo in
NavigationLink(destination: MemoDetailView(memo: memo)) {
Text(memo.title)
}
}
.navigationBarTitle("メモ一覧")
.navigationBarItems(trailing: NavigationLink(destination: MemoEditView(memos: $memos)) {
Image(systemName: "plus")
})
}
}
}
struct MemoDetailView: View {
let memo: Memo
var body: some View {
VStack {
Text(memo.title)
.font(.title)
Text(memo.content)
.padding()
Spacer()
}
.navigationBarTitle(memo.title)
}
}
struct MemoEditView: View {
@Binding var memos: [Memo]
@State var title: String = ""
@State var content: String = ""
var body: some View {
Form {
Section(header: Text("タイトル")) {
TextField("タイトルを入力してください", text: $title)
}
Section(header: Text("内容")) {
TextEditor(text: $content)
}
Section {
Button(action: {
let memo = Memo(title: title, content: content)
memos.append(memo)
}) {
Text("保存")
}
}
}
.navigationBarTitle("新規メモ")
}
}