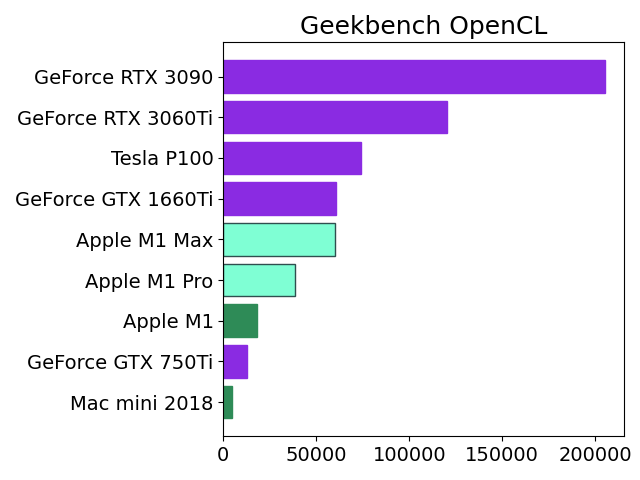
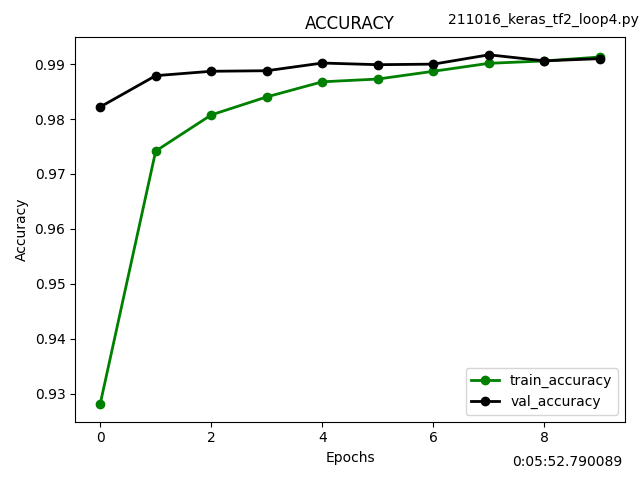
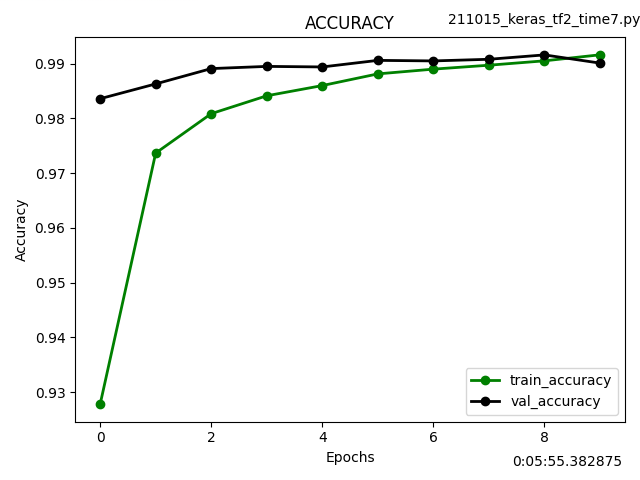
先日発表されたApple M1 ProとMaxのAI学習性能をざっくり推定してみました。
Apple M1のベンチスコアをGPUコア数の比率から2倍(Pro)、4倍(Max)にしてNVIDIAの人気機種と比較しました。
この見立てが正しければ、M1 MaxはGoogle Colab Pro(有料)でレンタル可能なTesla P100と同レベルのようです。
私の場合はたまに学習モデルを作成する程度なので、それだけのために新型MacBook Proを購入するよりもGTX 1660Tiを購入して自作PCに装着する方がリーズナブルな感じがします。もっとも価格が発売当初の3万円から倍近くに高騰していて、今すぐ買おうとは思いませんが。
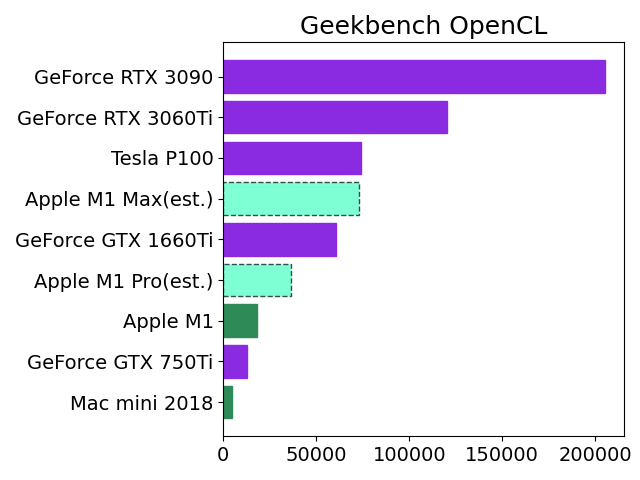
# M1 MaxとM1 Proは枠線の種類を破線にする。
# linestyleのリストは使用不可のためfor文とif文で設定。
import matplotlib.pyplot as plt
x = [1, 2, 3, 4, 5, 6, 7, 8, 9]
y = [4868, 12765, 18260, 36520, 60396, 73040, 73986, 120247, 205239]
label_x = ["Mac mini 2018","GeForce GTX 750Ti","Apple M1","Apple M1 Pro(est.)","GeForce GTX 1660Ti","Apple M1 Max(est.)","Tesla P100","GeForce RTX 3060Ti","GeForce RTX 3090"]
image ='test.png'
fig = plt.figure()
color_list = ['#2e8b57','#8a2be2','#2e8b57','#7fffd4','#8a2be2','#7fffd4','#8a2be2','#8a2be2','#8a2be2']
edgecolor_list = ['#2e8b57','#8a2be2','#2e8b57','#2f4f4f','#8a2be2','#2f4f4f','#8a2be2','#8a2be2','#8a2be2']
for i,j,k,l in zip(x,y,color_list,edgecolor_list):
if i==4 or i==6:
plt.barh(i, j,color=k,align="center",edgecolor=l,linestyle='dashed')
else:
plt.barh(i, j,color=k,align="center",edgecolor=l,linestyle='solid')
plt.yticks(x, label_x)
plt.title('Geekbench OpenCL', fontsize=18)
plt.tick_params(labelsize=14)
plt.tight_layout()
plt.show()
fig.savefig(image)
参考サイト(ベンチマーク)