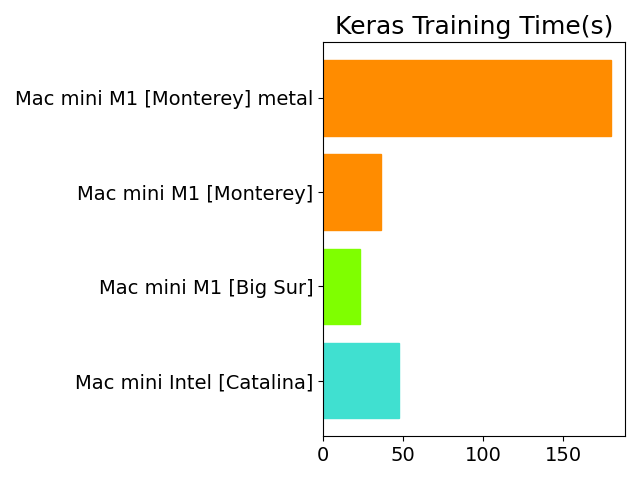
GPUを動かすtensorflow-metalを使うためmacOS Montereyにアップグレードして、学習時間を測定しました。
期待に反してかなり時間が掛かってしまいました。コードの内容によって変わってくるのだと思います。
結局、最速はBig Surでした。何のためにアップグレードしたのか馬鹿らしくなりましたが、新機能を試したいのでこのままにします。
GPUを動かすtensorflow-metalを使うためmacOS Montereyにアップグレードして、学習時間を測定しました。
期待に反してかなり時間が掛かってしまいました。コードの内容によって変わってくるのだと思います。
結局、最速はBig Surでした。何のためにアップグレードしたのか馬鹿らしくなりましたが、新機能を試したいのでこのままにします。
[macOS Big Sur 11.6 (M1 Mac)]
色々検討を重ねた末、M1 Mac miniを購入しました。ネット情報だけではプログラミング開発環境構築の可否が分からなかったので、とりあえず最小限の投資で確認することにしました。
開発環境はAI関連はMiniforge、それ以外はpyenv-virtualenvに分けました。各々でpipの管理ができ、共存は可能のようです。
学習時間はIntel Mac miniの47秒に対し、M1 Mac miniは23秒で半分になりました。ただOpen CLのベンチマーク比較ではおよそ4倍の性能アップなので少し物足りません。次回以降でtensorflow-metalを入れて検証する予定です。
pyenv内にMiniforgeをインストールできますが、仮想環境を入れ子にするとcondaコマンドが使えませんでした。Miniforgeで仮想環境を作らないケースについては未確認です。
またpipからtensorflow-macos 2.6.0と2.5.0のインストールを始められるものの、依存関係云々でエラーになりました。これらはIntel Mac用かもしれません。
# Miniforgeのインストール
wget https://github.com/conda-forge/miniforge/releases/latest/download/Miniforge3-MacOSX-arm64.sh
# yamlファイルのダウンロード(ネット公開されていたものを拝借しました)
wget -P ~/Downloads https://raw.githubusercontent.com/mwidjaja1/DSOnMacARM/main/environment.yml
# 仮想環境 ai_studyの作成
conda env create --file=environment.yml --name ai_study
# tensorflow-macosのインストール
pip install --upgrade --force --no-dependencies https://github.com/apple/tensorflow_macos/releases/download/v0.1alpha3/tensorflow_addons_macos-0.1a3-cp38-cp38-macosx_11_0_arm64.whl https://github.com/apple/tensorflow_macos/releases/download/v0.1alpha3/tensorflow_macos-0.1a3-cp38-cp38-macosx_11_0_arm64.whl
# 仮想環境を有効化する
conda activate ai_study
# 仮想環境を無効にする
conda deactivate
# 仮想環境 ai_studyの削除
conda remove -n ai_study --all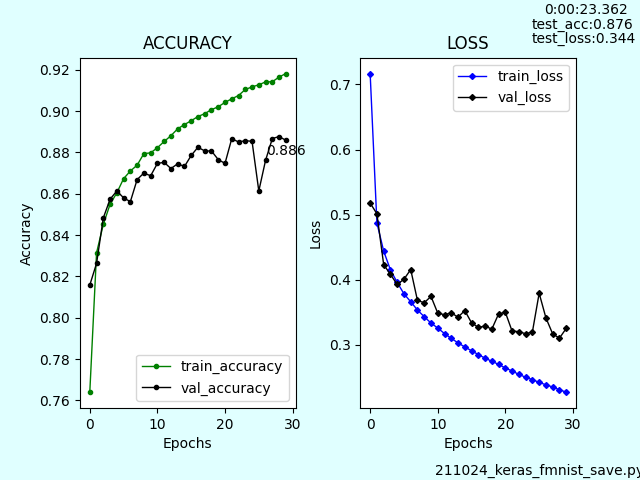
ジェネレータを用いたフィボナッチ数生成関数を走らせてみました。
処理速度は反復法に及びませんでしたが、なかなか面白い手法です。
import time,datetime
def generator(): # ジェネレータ
a, b = 0, 1
while True:
yield b
a, b = b, a + b
def fib_generator(n): # ジェネレータを用いた関数
fib = generator()
fib_list = [next(fib) for i in range(n-1)]
return fib_list[-1]
def fib_iterate(n): # 反復法
a, b = 0, 1
if n == 1:
return a
elif n == 2:
return b
else:
for i in range(n-2):
a, b = b, a + b
return b
def fib_recursion(n, memo={}): # メモ化再帰法
if n == 1:
return 0
elif n == 2:
return 1
elif n in memo:
return memo[n]
else:
memo[n] = fib_recursion(n-1, memo) + fib_recursion(n-2, memo)
return memo[n]
if __name__ == '__main__':
list_time = list()
for function in [fib_generator,fib_iterate,fib_recursion]:
start = time.time()
print(function)
print(function(41))
# 処理時間算出
process_time = time.time() - start
td = datetime.timedelta(seconds = process_time)
list_time.append(td.microseconds)
print(list_time)
--------------------------------------------------
出力
--------------------------------------------------
<function fib_generator at 0x1074070d0>
102334155
<function fib_iterate at 0x107407160>
102334155
<function fib_recursion at 0x107407040>
102334155
[52, 10, 33]フィボナッチ数を生成する関数の計算速度を測定しました。メモ化再帰法が最速でした。
今の私の知識では反復法一択ですが、再帰的手法についてはこれから学んでいきます。
import time,datetime
def fib_A(n): # 反復法
a, b = 0, 1
if n == 1:
return a
elif n == 2:
return b
else:
for i in range(n-2):
a, b = b, a + b
return b
def fib_B(n): # 再帰法
if n == 1:
return 0
elif n == 2:
return 1
else:
return fib_B(n-1) + fib_B(n-2)
def fib_C(n, memo={}): # メモ化再帰法
if n == 1:
return 0
elif n == 2:
return 1
elif n in memo:
return memo[n]
else:
memo[n] = fib_C(n-1, memo) + fib_C(n-2, memo)
return memo[n]
if __name__ == '__main__':
list_time = list()
for function in [fib_A,fib_B,fib_C]:
start = time.time()
print(function)
print(function(40))
# 処理時間算出
process_time = time.time() - start
td = datetime.timedelta(seconds = process_time)
list_time.append(td.microseconds)
print(list_time)
--------------------------------------------------
出力
--------------------------------------------------
<function fib_A at 0x10743cf70>
63245986
<function fib_B at 0x107637040>
63245986
<function fib_C at 0x1076370d0>
63245986
[42, 549224, 35]matplotlibのソースコードを読んでデコレータの存在を知り、自分のスキルがまだまだであることを痛感しました。
Pythonのエキスパートを目指すべく、中級者向けの書籍である”エキスパートPythonプログラミング 改訂3版”を購入しました。
早速、書籍内でも高度な文法と位置付けられているイテレータの章を読んでみました。有限・無限の数値発生器として使えそうです。
最近プログラミング関連本はAmazonや大手ネット書店の電子書籍ではなく、出版社サイトなどからPDFで購入しています。コードのコピーや書き込みができるので学習用途ではこちらの方が便利です。
# 再利用できるイテレータ
from time import sleep
class CounterState:
def __init__(self, step):
self.step = step
def __next__(self):
# カウンタ値を1つずつ0まで減算する
if self.step <= 0:
raise StopIteration
self.step -= 1
return self.step
class CountDown:
def __init__(self, steps):
self.steps = steps
def __iter__(self):
return CounterState(self.steps)
if __name__ == "__main__":
for element in CountDown(10):
symbols = '*' * element
print(symbols)
sleep(0.2)
--------------------------------------------------
出力
--------------------------------------------------
*********
********
*******
******
*****
****
***
**
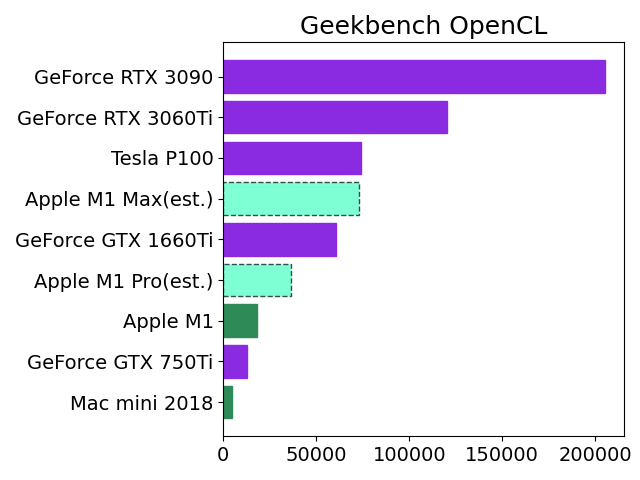
*Apple M1 ProとMaxのベンチスコアが判明しましたので、グラフデータを更新します。OpenCLスコアはあくまでもGPU性能の数ある指標の一つです。
前回記事で予測したスコアと比較してProは少し上、Maxは下でした。Proの方が若干のお得感があります。MaxはTesla P100には及ばず、Google Colabは優位性を固守しています。
そろそろIntel MacからAppleシリコン機へ軸足を移すため、Mac mini M1 Proの10コアCPU、16コアGPUを購入するつもりです。発売が11月になるのか来春以降になるのか分かりませんが、とても待ち遠しいです。
なおAI学習をする上で物足りないようであれば、Windows機でGPUを強化します。
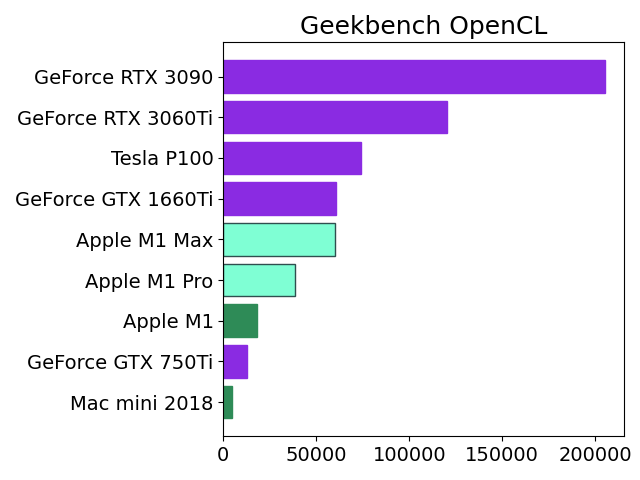
先日発表されたApple M1 ProとMaxのAI学習性能をざっくり推定してみました。
Apple M1のベンチスコアをGPUコア数の比率から2倍(Pro)、4倍(Max)にしてNVIDIAの人気機種と比較しました。
この見立てが正しければ、M1 MaxはGoogle Colab Pro(有料)でレンタル可能なTesla P100と同レベルのようです。
私の場合はたまに学習モデルを作成する程度なので、それだけのために新型MacBook Proを購入するよりもGTX 1660Tiを購入して自作PCに装着する方がリーズナブルな感じがします。もっとも価格が発売当初の3万円から倍近くに高騰していて、今すぐ買おうとは思いませんが。
# M1 MaxとM1 Proは枠線の種類を破線にする。
# linestyleのリストは使用不可のためfor文とif文で設定。
import matplotlib.pyplot as plt
x = [1, 2, 3, 4, 5, 6, 7, 8, 9]
y = [4868, 12765, 18260, 36520, 60396, 73040, 73986, 120247, 205239]
label_x = ["Mac mini 2018","GeForce GTX 750Ti","Apple M1","Apple M1 Pro(est.)","GeForce GTX 1660Ti","Apple M1 Max(est.)","Tesla P100","GeForce RTX 3060Ti","GeForce RTX 3090"]
image ='test.png'
fig = plt.figure()
color_list = ['#2e8b57','#8a2be2','#2e8b57','#7fffd4','#8a2be2','#7fffd4','#8a2be2','#8a2be2','#8a2be2']
edgecolor_list = ['#2e8b57','#8a2be2','#2e8b57','#2f4f4f','#8a2be2','#2f4f4f','#8a2be2','#8a2be2','#8a2be2']
for i,j,k,l in zip(x,y,color_list,edgecolor_list):
if i==4 or i==6:
plt.barh(i, j,color=k,align="center",edgecolor=l,linestyle='dashed')
else:
plt.barh(i, j,color=k,align="center",edgecolor=l,linestyle='solid')
plt.yticks(x, label_x)
plt.title('Geekbench OpenCL', fontsize=18)
plt.tick_params(labelsize=14)
plt.tight_layout()
plt.show()
fig.savefig(image)ネットから入手したファッションアイテム画像について予測してみました。
入手した画像を正方形の背景に埋め込み、リサイズ、グレースケールに変換してから学習モデルに供しました。
正解率は67%でした。Tシャツをシャツと予測ミスしていますが、即席の学習モデルではそんなところでしょう。

import tensorflow.keras as keras
from PIL import Image
import numpy as np
import os,glob,re
labels = ['tshirt','trouser','pullover','dress','coat','sandal','shirt','sneaker','bag','boot']
# 画像ファイル名にはラベル(正解)が含まれている(tshirt1.pngなど)
files = glob.glob('/test/*.png')
print(files)
X = list()
y = list()
for file in files:
image = Image.open(file)
image = image.resize((28, 28))
image = image.convert('L')
data = np.asarray(image)
label1 = re.search(r'[a-z]+',os.path.split(file)[1].replace('.png',''))
label2 = label1.group()
print(label2)
label3 = labels.index(label2)
print(label3)
X.append(data)
y.append(label3)
X_test = np.array(X)
# 白黒を反転させる
X_test2 = 255 - np.array(X)
print(X_test2)
y_test = np.array(y)
print(y_test)
model = keras.models.load_model('keras-fmnist-model.h5', compile=True)
y_prob = model.predict(X_test2)
print(y_prob)
y_pred = [ i for prob in y_prob for i,p in enumerate(prob) if p == max(prob)]
# predict_classesは廃止予定
# y_pred = model.predict_classes(X_test2)
print(y_pred)
y_pred2 = np.array(labels)[y_pred]
y_answer = np.array(labels)[y_test]
print(f'予測 {y_pred2} 正解 {y_answer}')
--------------------------------------------------
出力の一部
--------------------------------------------------
[[0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00 1.0000000e+00]
[0.0000000e+00 1.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
0.0000000e+00 1.0539890e-37 0.0000000e+00 0.0000000e+00 0.0000000e+00]
[3.0448330e-03 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
0.0000000e+00 9.9695516e-01 0.0000000e+00 0.0000000e+00 0.0000000e+00]]
[9 1 6]
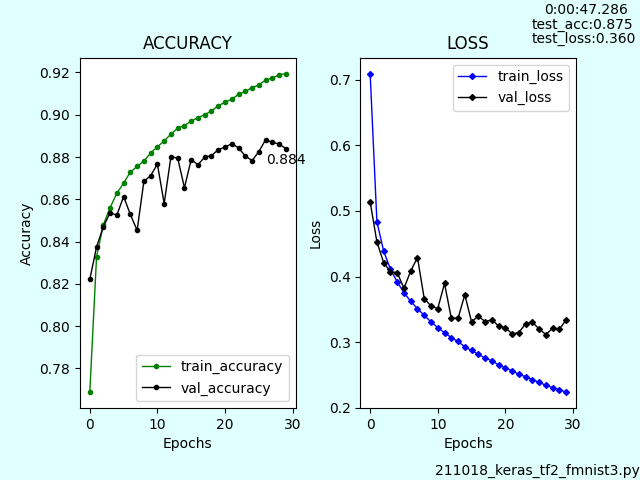
予測 ['boot' 'trouser' 'shirt'] 正解 ['boot' 'trouser' 'tshirt']Fashion-MNISTを使ったKeras学習モデルでテストするところまで作成しました。訓練回数は30回です。テスト結果はグラフの右上に表示しています。
テストの結果データはhistory.historyにtestキーとして追加し、JSONファイルに保存しています。
import tensorflow.keras as keras
from tensorflow.keras import models
from keras.layers import Dense, Flatten
import matplotlib.pyplot as plt
import time,datetime,os,json
def plot_loss_accuracy_graph(history,eval):
<略>
return dt_now_str # グラフ作成日時
def main():
epochs=30
# データセット取得
fashion_mnist = keras.datasets.fashion_mnist
(X_train, y_train), (X_test, y_test) = fashion_mnist.load_data()
print(f'X_train_full.shape {X_train.shape}')
print(f'X_test.shape {X_test.shape}')
X_train = X_train / 255.
X_test = X_test / 255.
# モデル作成
model = models.Sequential()
model.add(Flatten(input_shape=[28, 28]))
model.add(Dense(300, activation="relu"))
model.add(Dense(100, activation="relu"))
model.add(Dense(10, activation="softmax"))
print(f'model.layers {model.layers}')
model.summary()
model.compile(loss="sparse_categorical_crossentropy",
optimizer="sgd",
metrics=["accuracy"])
# 訓練
history = model.fit(X_train, y_train, epochs=epochs,
validation_split=0.1)
print(f'history.history {history.history}')
# 検証結果
val_loss = history.history['val_loss'][-1]
val_accuracy = history.history['val_accuracy'][-1]
print('val_loss:', val_loss)
print('val_accuracy:', val_accuracy)
# テスト
test = model.evaluate(X_test, y_test)
print(f'test {test}')
# グラフ化
ret = plot_loss_accuracy_graph(history,test)
test2 = {"test":test}
history.history.update(**test2)
json_file = f'{ret}_history_data.json'
with open(json_file ,'w' ) as f:
json.dump(history.history ,f ,ensure_ascii=False ,indent=4)
model.save(f'{ret}_keras-mnist-model.h5')
if __name__ == "__main__":
start = time.time()
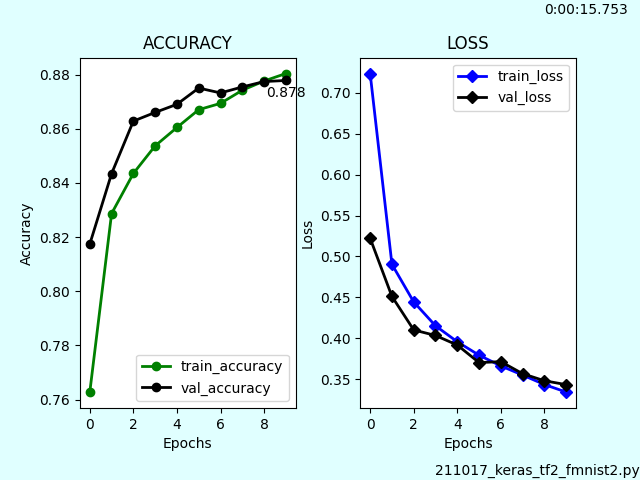
main()matplotlibの設定箇所が間延びした見た目だったのでスッキリさせました。
グラフ内と枠内にテキスト表示させています。val_accuracyの最後の値をグラフ内表示しています。枠内表示は実行時間とファイル名です。
start = time.time()
def plot_loss_accuracy_graph(history):
process_time = time.time() - start
td = datetime.timedelta(seconds = process_time)
image ='accuracy_loss.png'
fig = plt.figure(facecolor='#e0ffff')
fig.subplots_adjust(bottom=0.15,wspace=0.3)
ax = fig.add_subplot(121, title = 'ACCURACY',xlabel = 'Epochs',ylabel = 'Accuracy')
ax.plot(history.history['accuracy'],"-o", color="green", label="train_accuracy", linewidth=2)
ax.plot(history.history['val_accuracy'],"-o",color="black", label="val_accuracy", linewidth=2)
ax.legend(loc="lower right")
# グラフ内テキスト表示
ax.text(len(history.history['val_accuracy']) -1, history.history['val_accuracy'][-1]-0.002, '{:.3f}'.format(history.history['val_accuracy'][-1]),verticalalignment='top',horizontalalignment='center')
ax2 = fig.add_subplot(122, title = 'LOSS',xlabel = 'Epochs',ylabel = 'Loss')
ax2.plot(history.history['loss'], "-D", color="blue", label="train_loss", linewidth=2)
ax2.plot(history.history['val_loss'], "-D", color="black", label="val_loss", linewidth=2)
ax2.legend(loc='upper right')
# 枠内テキスト表示
fig.text(0.68, 0.01, os.path.basename(__file__))
fig.text(0.85, 0.97, str(td)[:11])
fig.savefig(image)