『Cプログラミングの落とし穴』(A.コーニグ, 1990)
[M1 Mac, Big Sur 11.6.8, clang 13.0.0, NO IDE]
前回の続きです。
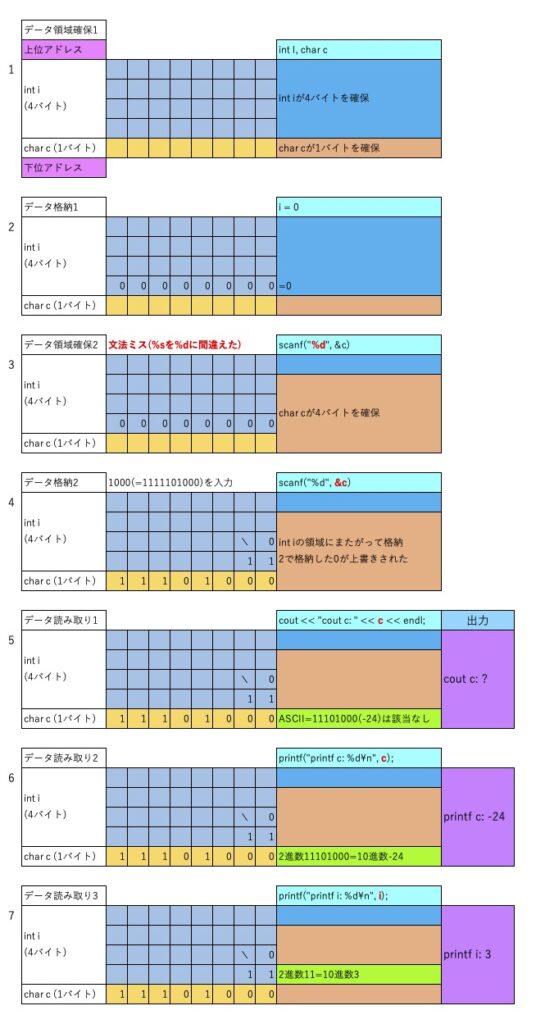
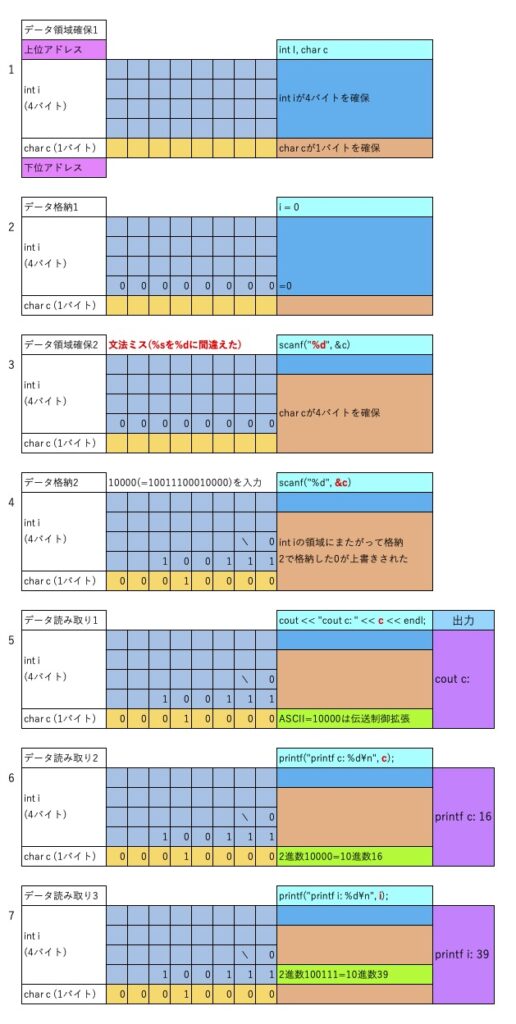
不出来なコードにscanfで1000を入力した場合は、以下のようになります。
coutでは格納されたデータはASCIIコードとして認識し、printfでは%dなので整数として認識しています。
%dは符号あり整数(8ビットなので-128以上127以下)です。入力値によってはマイナスになったりします。
2進数 11101000の符号あり整数への変換(マイナスと仮定)
1を減算 11100111
反転 00011000
10進数へ変換 24
したがって 2進数 11101000は-24
ASCIIコードは0から127までの128文字ですから、-24の場合は該当文字がありません。
結局メモリに格納された2進数をどのように解釈するか、どのデータ型として読み出すかで出力内容が変わってきます。
%sを%dとしてしまうのをエラーにしないと前回、今回のようなトラブルになりますし、いっそのことコンパイルエラーにしてもらいたいものです。
#include <cppstd.h>
int main() {
int i;
char c;
cout << "iのアドレス: " << &i << endl;
cout << "iのサイズ: " << to_string(sizeof i) << endl;
cout << "cのアドレス: " << &c << endl;
cout << "cのサイズ: " << to_string(sizeof c) << endl;
for (i=0;i<5;i++){
scanf("%d",&c);
// 正しくは
// scanf("%s",&c);
cout << "cout c: " << c << endl;
printf("printf c: %d\n",c);
printf("%d\n",i);
}
return 0;
}
--------------------------------------------------
出力
--------------------------------------------------
iのアドレス: 0x16f56f698
iのサイズ: 4
cのアドレス:
cのサイズ: 1
1000
cout c: ?
printf c: -24
3