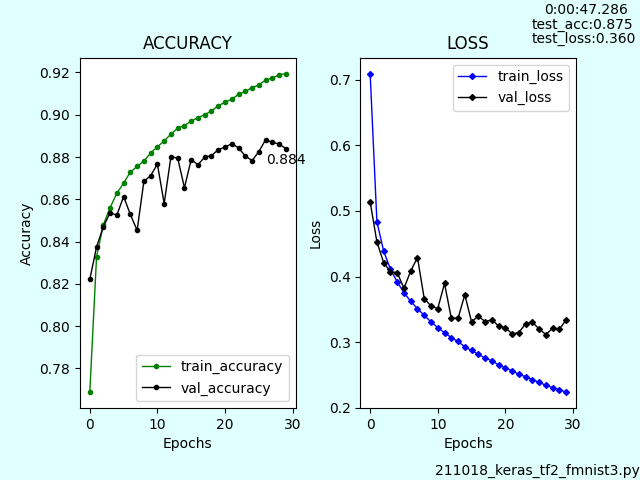
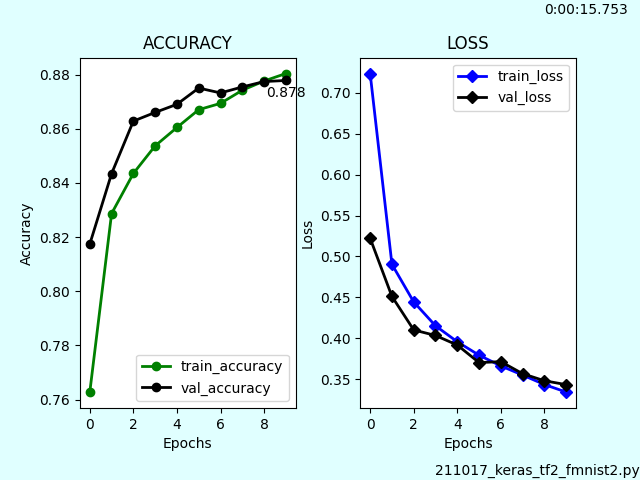
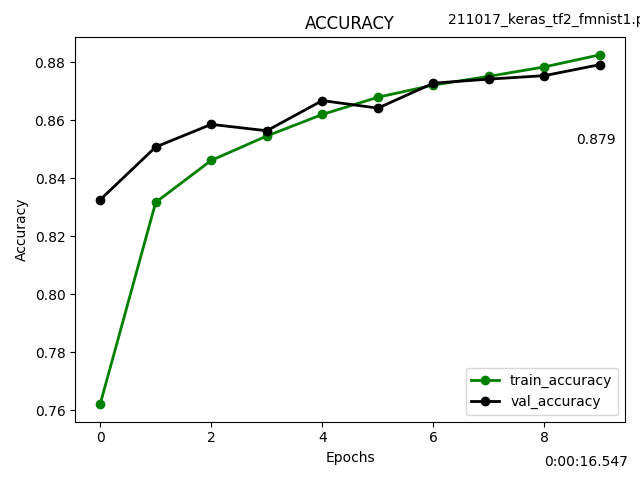
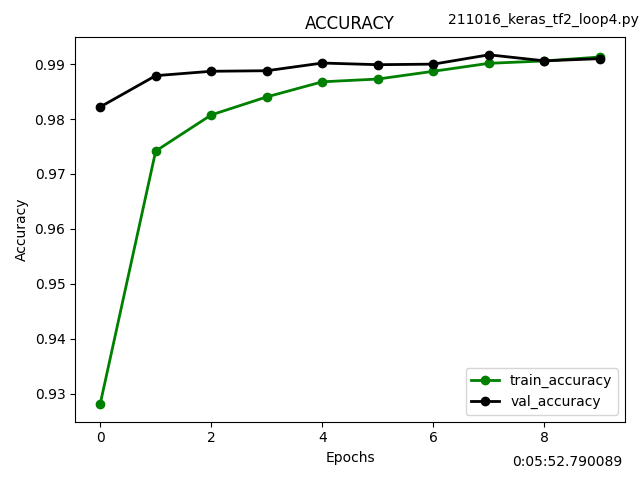
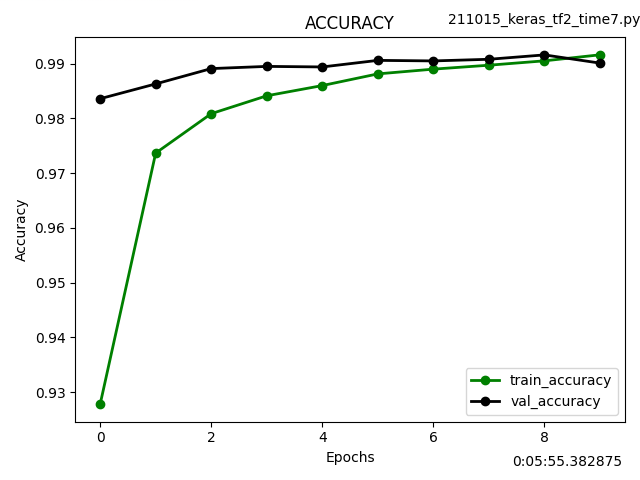
ネットから入手したファッションアイテム画像について予測してみました。
入手した画像を正方形の背景に埋め込み、リサイズ、グレースケールに変換してから学習モデルに供しました。
正解率は67%でした。Tシャツをシャツと予測ミスしていますが、即席の学習モデルではそんなところでしょう。

import tensorflow.keras as keras
from PIL import Image
import numpy as np
import os,glob,re
labels = ['tshirt','trouser','pullover','dress','coat','sandal','shirt','sneaker','bag','boot']
# 画像ファイル名にはラベル(正解)が含まれている(tshirt1.pngなど)
files = glob.glob('/test/*.png')
print(files)
X = list()
y = list()
for file in files:
image = Image.open(file)
image = image.resize((28, 28))
image = image.convert('L')
data = np.asarray(image)
label1 = re.search(r'[a-z]+',os.path.split(file)[1].replace('.png',''))
label2 = label1.group()
print(label2)
label3 = labels.index(label2)
print(label3)
X.append(data)
y.append(label3)
X_test = np.array(X)
# 白黒を反転させる
X_test2 = 255 - np.array(X)
print(X_test2)
y_test = np.array(y)
print(y_test)
model = keras.models.load_model('keras-fmnist-model.h5', compile=True)
y_prob = model.predict(X_test2)
print(y_prob)
y_pred = [ i for prob in y_prob for i,p in enumerate(prob) if p == max(prob)]
# predict_classesは廃止予定
# y_pred = model.predict_classes(X_test2)
print(y_pred)
y_pred2 = np.array(labels)[y_pred]
y_answer = np.array(labels)[y_test]
print(f'予測 {y_pred2} 正解 {y_answer}')
--------------------------------------------------
出力の一部
--------------------------------------------------
[[0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00 1.0000000e+00]
[0.0000000e+00 1.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
0.0000000e+00 1.0539890e-37 0.0000000e+00 0.0000000e+00 0.0000000e+00]
[3.0448330e-03 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
0.0000000e+00 9.9695516e-01 0.0000000e+00 0.0000000e+00 0.0000000e+00]]
[9 1 6]
予測 ['boot' 'trouser' 'shirt'] 正解 ['boot' 'trouser' 'tshirt']